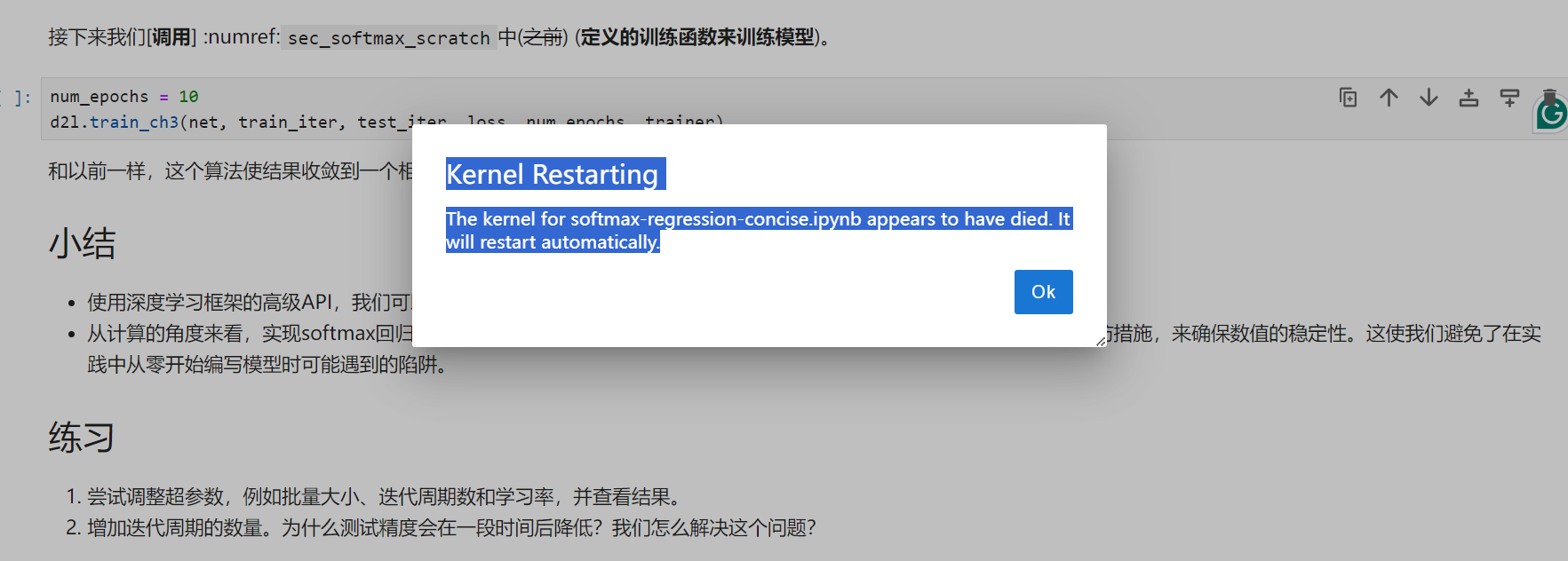
d2l=1.0.3环境下运行代码 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer) 报错 module 'd2l.torch' has no attribute 'train_ch3'
似乎是新版本的包中缺少了 train_ch3 的相关实现,解决办法是在 d2l 的包中添加相关代码,也就是 3.6中的 evaluate_accurary(), train_epoch_ch3() 和 train_ch3(),具体步骤如下:
- 定位到环境下d2l包的位置,我使用conda虚拟环境,名称为d2l,python版本3.11,具体是在
/home/cutelemon6/miniconda3/envs/d2l/lib/python3.11/site-packages/d2l
- 删除原来的缓存
rm -r /home/cutelemon6/miniconda3/envs/d2l/lib/python3.11/site-packages/d2l/__pycache__
- 如果你使用pytorch,在
torch.py 中添加如下代码
def evaluate_accurary(net, data_iter: torch.utils.data.DataLoader):
if isinstance(net, torch.nn.Module):
net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_epoch_ch3(net, train_iter, loss, updater):
metrics = Accumulator(3)
if isinstance(net, torch.nn.Module):
net.train()
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.mean().backward()
updater.step()
else:
l.sum().backward()
updater(X.shape[0]) # number of X's samples
metrics.add(float(l.sum()), accuracy(y_hat, y), y.numel())
return metrics[0] / metrics[2], metrics[1] / metrics[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for i in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accurary(net, test_iter)
animator.add(i + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
- 重启jupyter notebook kernel,全部运行代码即可