谢谢老哥(zsbdzsbdzsbdzsbd
所以书里说的“#@save是特殊标记,会把语句保存在对d2l包中”是骗人的啊,还在奇怪这咋实现的
1 Like
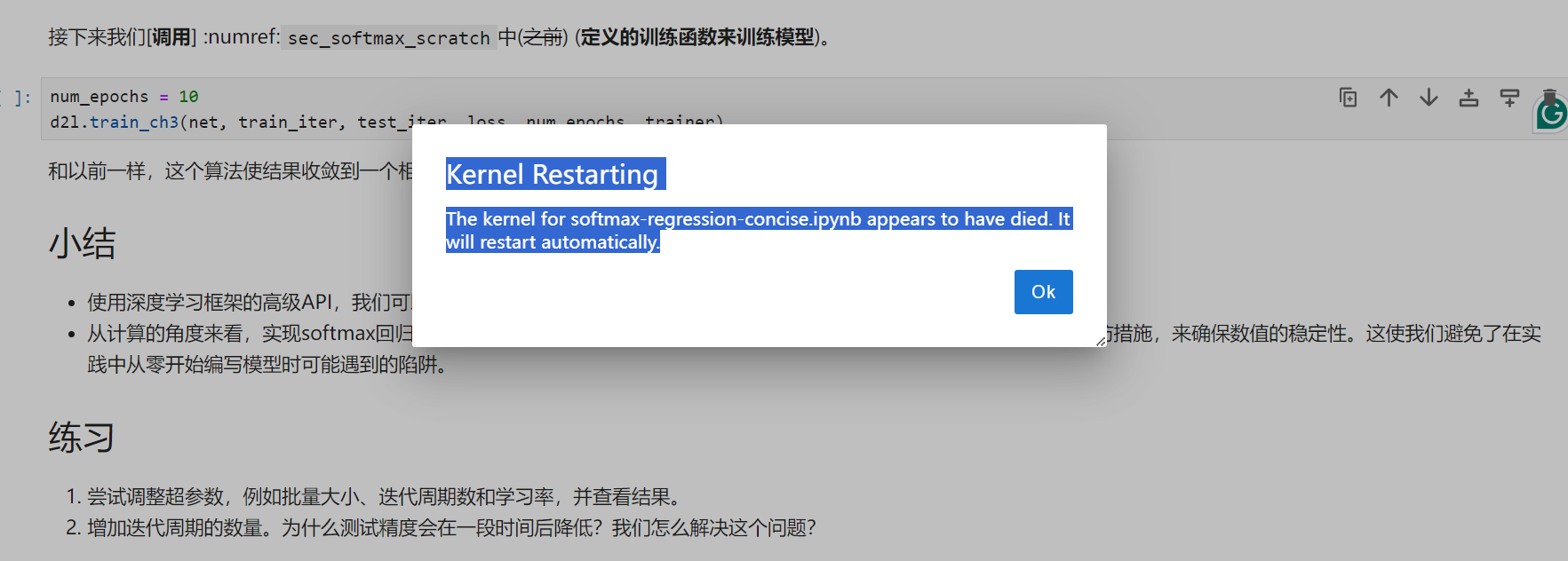
我在本地conda环境下运行notebook, 但是在最后一步训练的时候,ipynb的kernel似乎崩溃了,显示如下信息:
Kernel Restarting
The kernel for softmax-regression-concise.ipynb appears to have died. It will restart automatically.
请问运行这个notebook对硬件的要求是什么。我手上的笔记本有点老了。i7 6代处理器,24G内存,4G英伟达显卡,是否跑得动,谢谢
我也遇到这个问题,是要降低d2l的版本吗
![]()
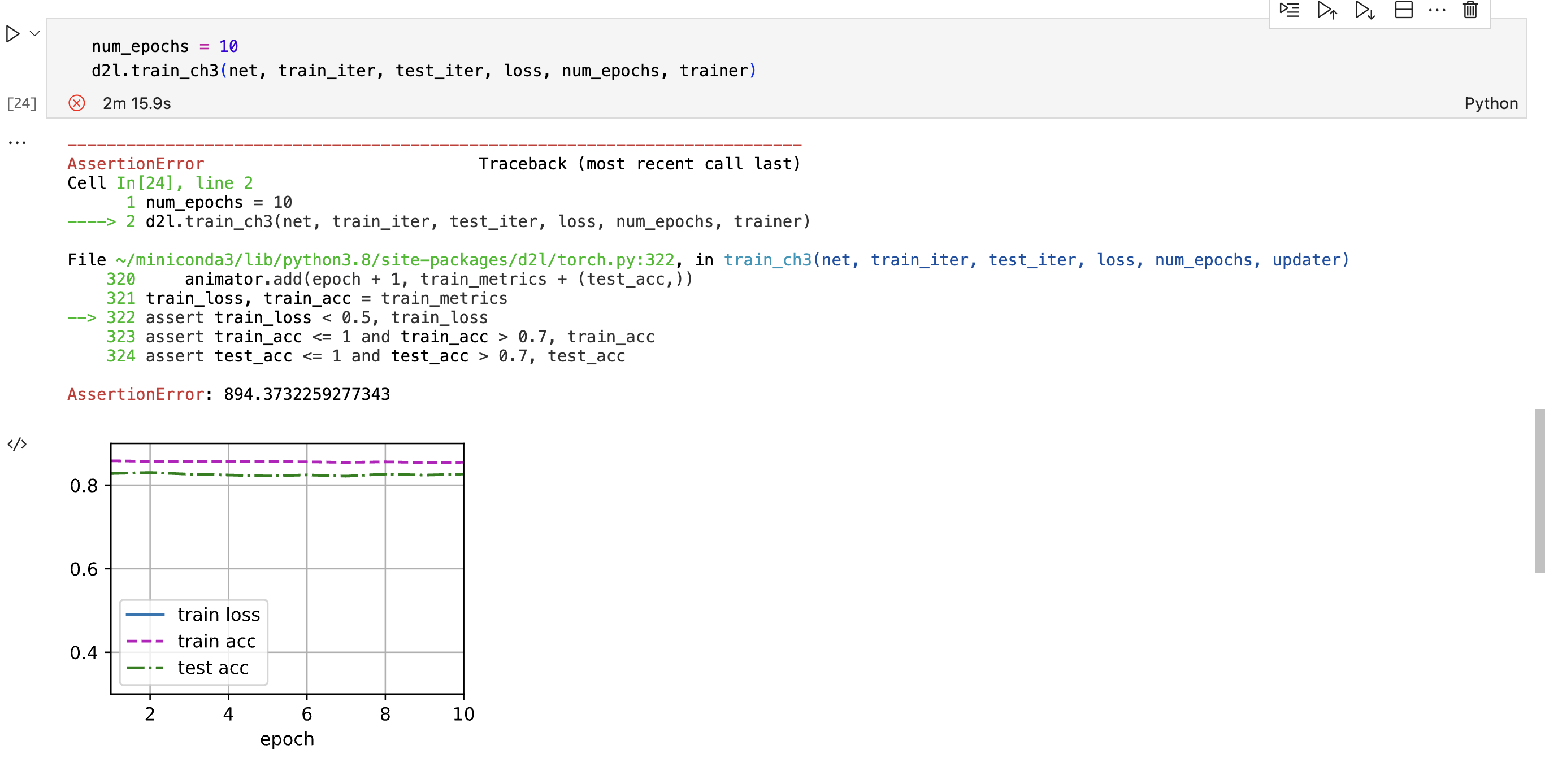
在前一章节明明已经保存了train_ch3函数了,为什么在这一章节里还是module ‘d2l.torch’ has no attribute 'train_ch3’呢?我又尝试了重新保存再重新导入d2l包仍然不行。好奇怪。
d2l版本的问题,降低一下版本试试,我之前默认是1.0.3,也提示相关错误,现在换成0.17.0好了
d2l=1.0.3环境下运行代码 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer) 报错 module 'd2l.torch' has no attribute 'train_ch3'
似乎是新版本的包中缺少了 train_ch3 的相关实现,解决办法是在 d2l 的包中添加相关代码,也就是 3.6中的 evaluate_accurary(), train_epoch_ch3() 和 train_ch3(),具体步骤如下:
- 定位到环境下d2l包的位置,我使用conda虚拟环境,名称为d2l,python版本3.11,具体是在
/home/cutelemon6/miniconda3/envs/d2l/lib/python3.11/site-packages/d2l - 删除原来的缓存
rm -r /home/cutelemon6/miniconda3/envs/d2l/lib/python3.11/site-packages/d2l/__pycache__ - 如果你使用pytorch,在
torch.py中添加如下代码
def evaluate_accurary(net, data_iter: torch.utils.data.DataLoader):
if isinstance(net, torch.nn.Module):
net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_epoch_ch3(net, train_iter, loss, updater):
metrics = Accumulator(3)
if isinstance(net, torch.nn.Module):
net.train()
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.mean().backward()
updater.step()
else:
l.sum().backward()
updater(X.shape[0]) # number of X's samples
metrics.add(float(l.sum()), accuracy(y_hat, y), y.numel())
return metrics[0] / metrics[2], metrics[1] / metrics[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for i in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accurary(net, test_iter)
animator.add(i + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
- 重启jupyter notebook kernel,全部运行代码即可
1 Like
Hi, the reason why the trainloss is not displayed on the image is because the value of the loss is too large or the value of the loss is too small. You can check the code that calculates the loss to see if the loss added in is too large or too small.
![]() d2l的train_ch3包找不到的话,可以在前面加这些代码:
d2l的train_ch3包找不到的话,可以在前面加这些代码:
def evaluate_accuracy(net, data_iter):
net.eval()
metric = Accumulator(2)
with torch.no_grad():
for x,y in data_iter:
metric.add(accuracy(net(x),y), y.numel())
return metric[0] / metric[1]
def train_epoch_ch3(net, train_iter, loss, updater):
net.train()
metric = Accumulator(3)
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
updater.zero_grad()
l.mean().backward()
updater.step()
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
![]() 如果你的train loss显示不出来,你可以在上述的train_ch3中加入一段代码输出loss,看是否过大或过小。
如果你的train loss显示不出来,你可以在上述的train_ch3中加入一段代码输出loss,看是否过大或过小。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
print(f'epoch:{epoch+1} and train loss:{train_metrics[0]}') #这里输出loss
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
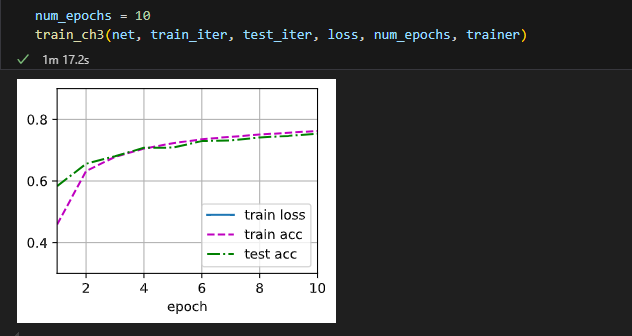
解决了。原因是loss不能用求和,这样会超过坐标轴的表示范围
修改为:loss = nn.CrossEntropyLoss(reduction=‘mean’)
使用均值就能成功在坐标轴上显示了
想请问一下在softmax的简洁回归中,d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer) 这句代码,报错显示:
AttributeError: module ‘d2l.torch’ has no attribute ‘train_ch3’
这是什么原因呢?
补一下,已经试过在上一个从零开始的代码中将train_ch3函数定义到d2l中
d2l.train_ch3 = train_ch3
效果好差,而且为什么没有train_loss曲线

运行时报错:
RuntimeError: grad can be implicitly created only for scalar outputs
将loss = nn.CrossEntropyLoss(reduction=‘none’)中
reduction='none' 改为 'mean'就正常了
测试可行,感谢!
以上列出的第二步“ 2. 删除原来的缓存 rm -r /home/cutelemon6/miniconda3/envs/d2l/lib/python3.11/site-packages/d2l/__pycache__是macOS的命令,在windows环境下输入会报错。我自己的windows电脑上略去第二步也可以解决问题。
我也是 现在都还没解决。。。。。。。。。。。。
1 Like
使用最新版d2l【1.0.3】的同学,由于新版d2l包不包含第三章训练代码,需要手动在【D:\exec_code\Python\D2DL\venv\Lib\site-packages\d2l\torch.py】文件中添加以下代码:
def evaluate_accurary(net, data_iter: torch.utils.data.DataLoader):
if isinstance(net, torch.nn.Module):
net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def train_epoch_ch3(net, train_iter, loss, updater):
metrics = Accumulator(3)
if isinstance(net, torch.nn.Module):
net.train()
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.mean().backward()
updater.step()
else:
l.sum().backward()
updater(X.shape[0]) # number of X's samples
metrics.add(float(l.detach().sum()), accuracy(y_hat, y), y.numel())
return metrics[0] / metrics[2], metrics[1] / metrics[2]
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for i in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accurary(net, test_iter)
animator.add(i + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
改动点:将本书中的:
metrics.add(float(l.sum()), accuracy(y_hat, y), y.numel())
改为:
metrics.add(float(l.detach().sum()), accuracy(y_hat, y), y.numel())
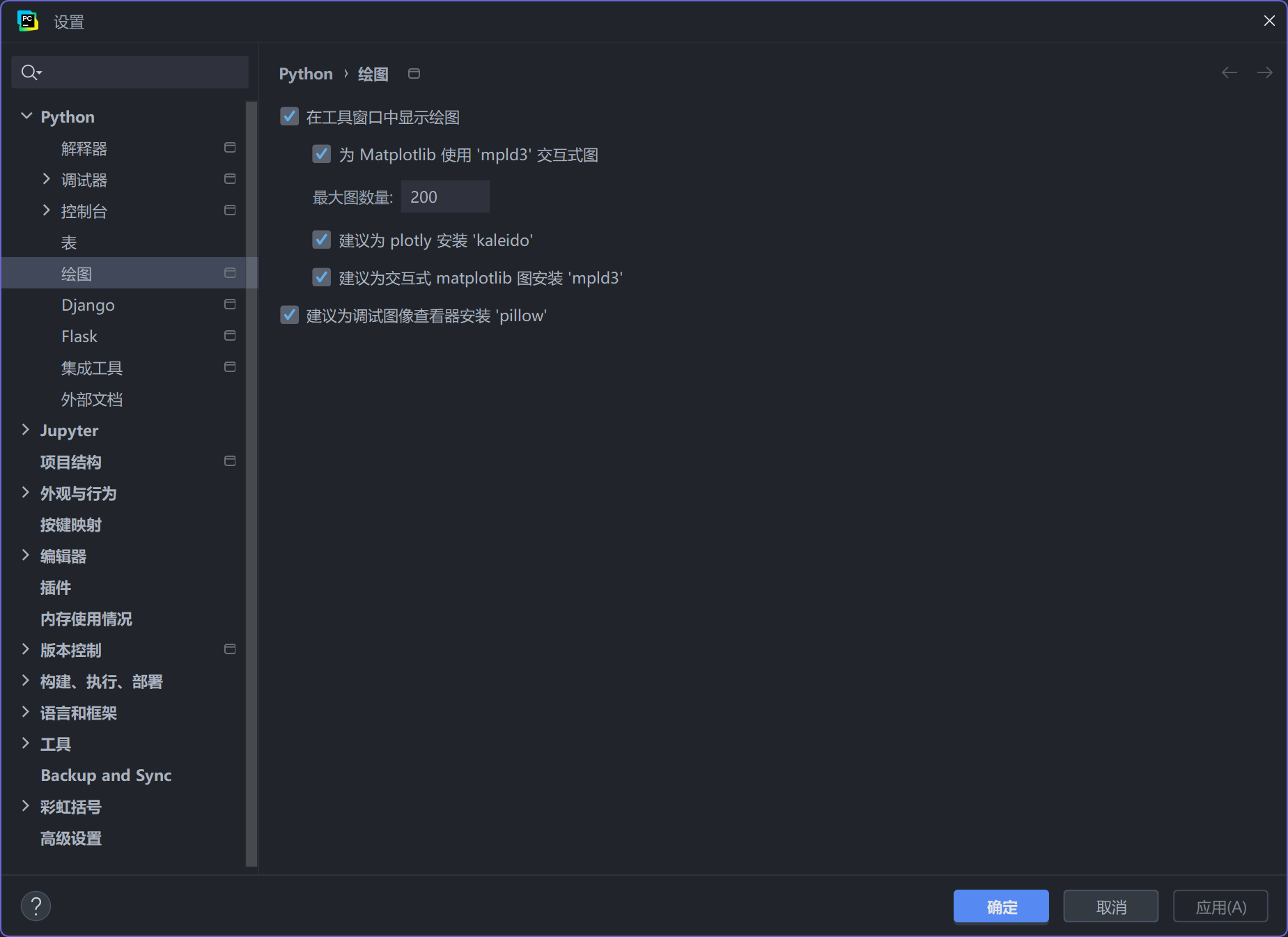
同时,针对使用在Pycharm专业版中,使用Jupyter时,没有图像输出,或者图像一闪而过的情况,需修改以下代码:
在【D:\exec_code\Python\D2DL\venv\Lib\site-packages\d2l\torch.py】文件中,将【Animator】类中的:
display.display(self.fig)
display.clear_output(wait=True)
注释掉即可。
新的【Animator】类如下:
class Animator:
"""For plotting data in animation."""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
"""Defined in :numref:`sec_utils`"""
# Incrementally plot multiple lines
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# Use a lambda function to capture arguments
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# Add multiple data points into the figure
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
# display.display(self.fig)
# display.clear_output(wait=True)
同时,Pycharm专业版中,以下设置需要打开:
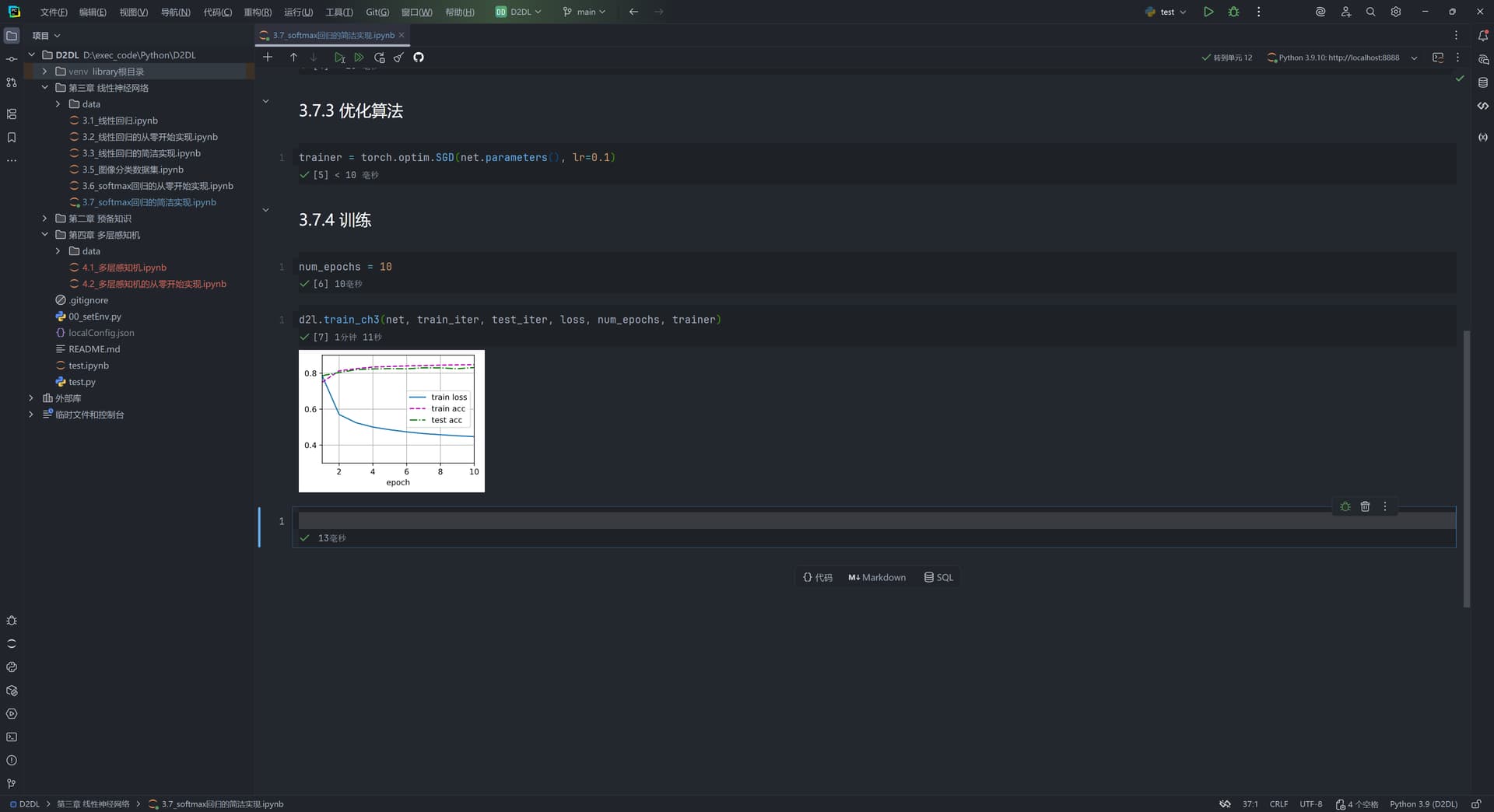
成功结果如下所示:
2 Likes