确实,按照给的代码来说,就是按照你给的这个信息流走的
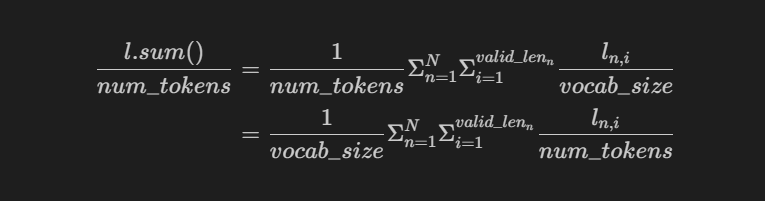
这里输出’X’的形状:应该是(num_steps,batch_size,embed_size),不然和下面的context就没法cat了,而且下面演示的时候,也是直接decoder(X, state),这里的X是(batch_size,num_steps),所以进到forward里面经过permute应该是(num_steps,batch_size,embed_size)!
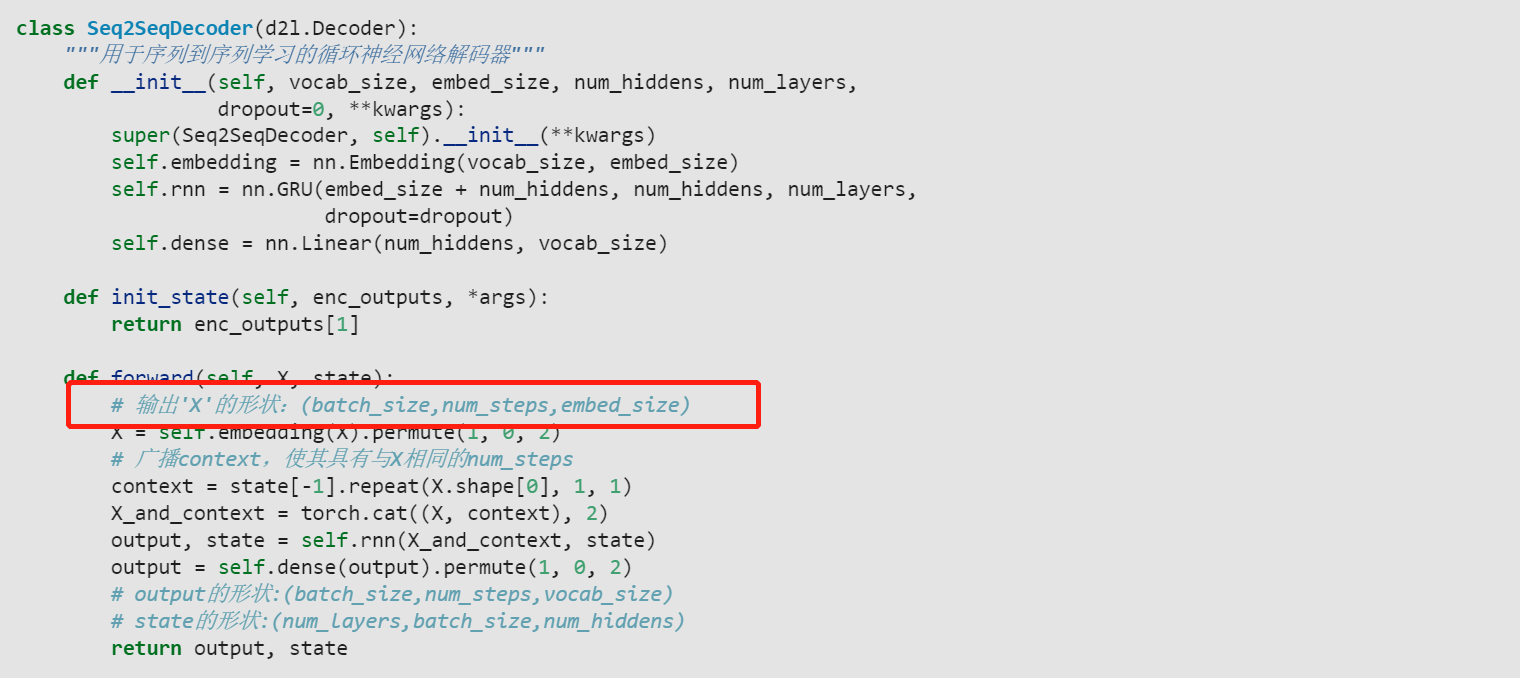
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 修改
# self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1] # state
def forward(self, x, state):
x = self.embedding(x).permute(1, 0, 2)
context = state[-1].repeat(x.shape[0], 1, 1)
# 修改
# x_and_context = torch.cat((x, context), 2)
# output, state = self.rnn(x_and_context, state)
output, state = self.rnn(x, state)
output = self.dense(output).permute(1, 0, 2)
return output, state
我这样修改跟你的结果是一样的
说得没错。
当初我也有将decoder prediction改为training 方式。。。
不过后来我反过来做:事实上,我将context disable,效果bleu显著改善。 我想这本身state已经包含了context信息了,何必再额外分开搞个context?
1 Like
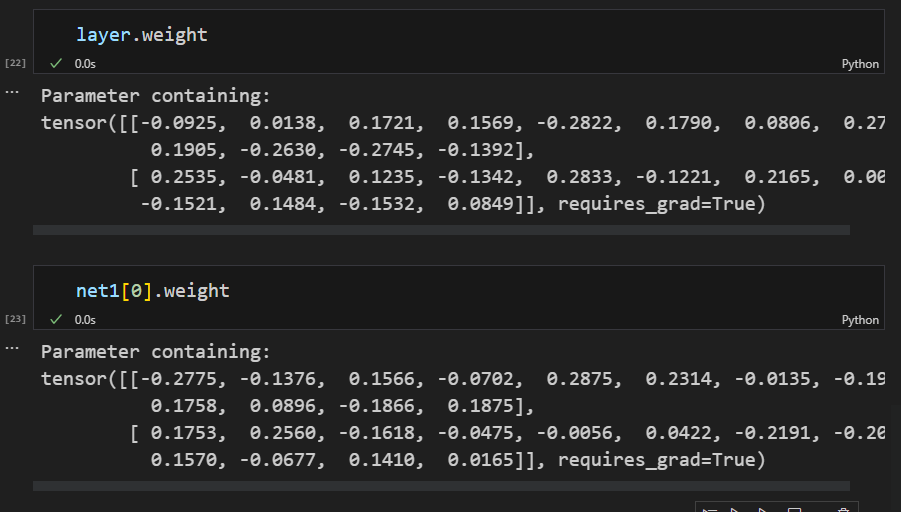
参数初始不同,可以使用next(iter( net.parameters) )观察
描述得好,但感觉 这个vocab_size应该改为num_steps
其实如果在mask CE中不计算mean()而使用sum(),那么此时的结果会更加直观
1 Like
应该是的,问题在于不符合设计,也和训练的流程不一致了。
Seq2SeqDecoder设计中state既和X拼接当做输入,又当做rnn初始的隐状态。这在训练的时候是没问题的,encoder最后的隐状态 encoder_state一次性拼接了所有时间步的X,也当做decoder的起始状态。
但在预测的时候,因为是用for循环一步一步更新的,每步都调用一次Seq2SeqDecoder,过程中改变了state, state变成了上一时刻的隐状态,输入rnn没有问题,但因为不再是encoder_state,和X拼接后就和训练不一致了。
比较简单的改法是修改Decoder,更新state的同时,保留encoder_state用于拼接。或者按照另一种设计方式,删除拼接步骤,encoder_state只用于做初始化。
2 Likes
那个vaild_len现在是没用的,之后下一章训练加性注意力模型就有用了(不要问我为什么知道的)
1 Like
这一节是学过的最难的一期,也非常有收获~
1 Like
我想问一下,训练代码中的
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
这一句是为了给目标序列的5’端头部加入一个起始符。为什么要将目标序列的尾部剪掉呢?这样做是否会损失目标序列最后一个时间步的信息?
还有关于词表tgt_vocab,如果我原始序列的词总数是4,由于加入,是不是意味着我需要更改词列表的长度,在decoder 的embedding步骤需要设置Seq2SeqDecoder模型为
decoder = Seq2SeqDecoder(vocab_size=5, other parameters)
再次感谢此课程,确实是这么听下来最难的一章,也帮我节省了不少时间。
预测中每一个step输入的不是x+上一个state,x你是不知道的。他每一个时间步输入的是y+上一个state,这个y是y-1+上上个state输出的结果。所以自然context在变很正常啊

请问你是将已经预测出的token全部输进decoder用来预测下一个token吗
“则第一个序列的第一项和第二个序列的前两项之后的剩余项将被清除为零。”这句话不太通顺,“则仅保留第一个序列的第一项和第二个序列的前两项,其余的项将被清零”
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device) # 1
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>']) # len = 10
# 添加批量轴
enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0) # 1*10
enc_outputs = net.encoder(enc_X, enc_valid_len) # enc_outputs = (output=10*1*32, state=2*1*32)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len) # 2*1*32 返回的就是编码器输出的state
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0) # 1*1
output_seq, attention_weight_seq = [], []
for _ in range(num_steps): # 预测每个词元的下一个
Y, _ = net.decoder(dec_X, dec_state) # 1*1*201 2*1*32
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2) # 1*1
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
这样就能保证context不更新了吧,但bleu的结果变差了
一直有个疑惑,这里的decoder是一个gru的网络,每次输入一个单词,输出一个预测的单次然后作为下一次decoder中gru的输入,也就是说这两次在gru的内部是毫无关系的,而gru的记忆功能不是网络内部么? 这样的话seq2seq在解码的时候记忆功能不是就没有了么?