这里两种设计方式应该指的是:是否将编码器的输出拼接到解码器每一个step的输入上,而上面的问题是预测阶段解码器每一个step的输入拼接的不再是encoder的输出,而是上一个step的隐状态了,已经默认选择第二种设计方式了
hidden_state有指定吧, hidden_state不就是输入参数里面的state吗,这里的state应该不只是加到输入上,而且应该包含了将state作为隐变量进行向前传播。
!!!
- 非常不理解原文为什么要用l.sum().backward(), 而不用l.mean().backward(), 在softmax的scratch那一节中明确采用了l.mean(), 然后再用optimizer.step(). 这里的损失l.shape=(
batch_size,) . 每一个元素表示【一个样本在各个时间步的平均损失】 - 也不懂为什么用l.sum()除以num_tokens表示的到底是什么意思,l.sum 既然是batch的综合【对时间步求平均后再对batch求和】,就应该除以batch_size, 但是原文除以num_tokens是什么鬼???
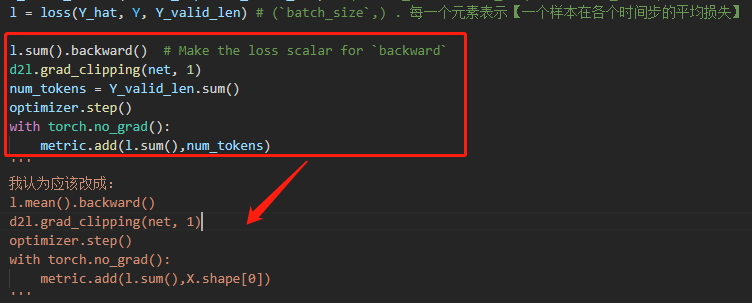
我也觉得,loss应该除以有效样本数啊,是否是应该先sum,再除以valid_lens
我觉得也是逻辑有错误,需要被cat的encode输出状态在后面预测的时候就成了每个时间步都变化的decoder最新隐状态了,所以我修改了下Seq2SeqDecoder类的实现,修改了init_state函数的输出和forward函数的一部分,使得运行逻辑和文字部分描述相符。
我看到后面“Bahadanau注意力”章节时注意到预测函数的本意是想让state携带着decoder的最新时间步隐状态和encoder输出状态的,所以这里也把Seq2SeqDecoder修改为这个逻辑。
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
#return enc_outputs[1]
return (enc_outputs[1], enc_outputs[1][-1])
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
# new
encode = state[1]
state = state[0]
# new end
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
#return output, state
return output, (state, encode)
这样修改并训练之后,最后的预测部分bleu会获得提升,我的输出为:
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est paresseux ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
8 Likes
请教一个问题啊。如果使用 LSTM Cell 的话,是不是需要把解码器所有层最终时间步的隐藏状态 H 和记忆状态 C 都用来初始化编码器对应位置的内部状态?
对于第一个问题,这里的maskedSoftmaxCELoss函数,输入一个批次的句子(假设batch_size是4,有A、B、C、D四个句子),那么输出的l是A、B、C、D这个批次对应的四个loss,每个就是你所说的【一个样本在各个时间步的平均损失】,反向传播用l.sum()和l.mean()实际上没有任何太大的区别,后者让学习率*batch_size其实也和前者一样了
对于第二个问题,只能说进行反向传播的那个loss确实和你理解的是一个意思,但这一部分实际输出出来是给你看训练效果的。所以当然要从token的角度考虑loss啊,在上一节就给出了例子:
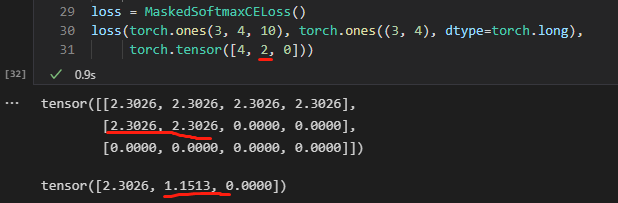
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long),
torch.tensor([4, 2, 0]))
实际输出:
tensor([2.3026, 1.1513, 0.0000])
l.sum()是3.4539, num_tokens是4+2+0=6,这时候print输出的loss显示就是3.4539/6=0.57565
所以可以看到,有效长度影响了loss的大小
这样就带来一个问题(如果按照你的思路只除以batch_size):比如说,在上一个batch,你选的句子都恰好都是valid_len比较大的几句话,计算出来的loss比较大,假设你没进行任何反向传播和参数更新,在当前batch你刚好选了几个valid_len比较小的几句话,那计算出来的loss自然就会很小,但是你没有进行任何训练呀。
还是刚才那个例子:
如果改成批次内三个句子的valid_len都是4
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long),
torch.tensor([4, 4, 4]))
实际输出:
tensor([2.3026, 2.3026, 2.3026])
l.sum()是6.9078, num_tokens是4+4+4=12,这时候print输出的loss显示就是6.9078/12=0.57565
发现了吗,除以num_tokens(也就是当前批次valid_len之和)能保证输出显示的loss不受句子长度的影响,按照你的思路都除以3,那现在输出的这个loss显然就要比之前那个大了,这样的loss并不能反应我们训练的过程,所以我们要除以vaild_lens。
2 Likes

累加器有必要放在torch.no_grad()下嘛?
你这样改了跟没改在训练的时候,根本就没差别,你把encode的最后一层隐状态单独返回回来,你又没有用它,我还没看预测代码,这是我看到训练代码时候评论的
1 Like
编码器,forward那里
···output, state = self.rnn(X)···
不应该是
···output, state = self.rnn(X, state)··· 吗?
公式都说了,t时刻的state,需要t时刻的输入与t-1时刻的state,不是很明白?
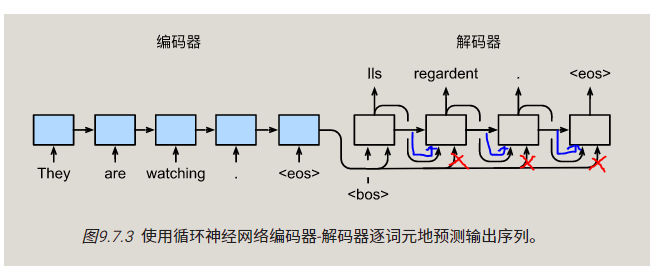
预测的代码,应该是图上的过程吧。
确实,按照给的代码来说,就是按照你给的这个信息流走的
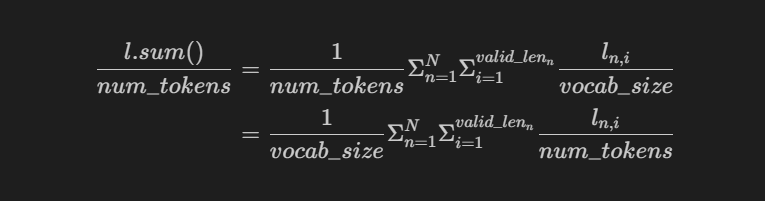
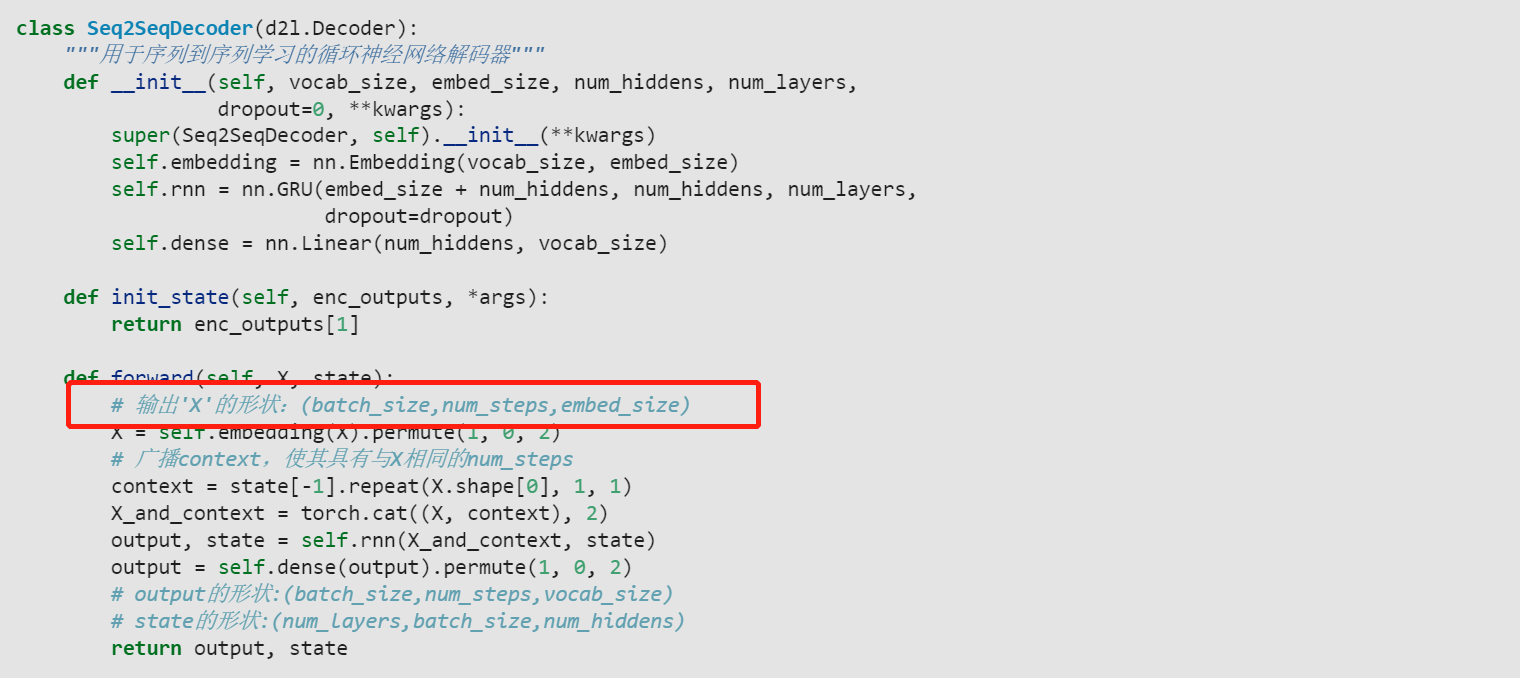
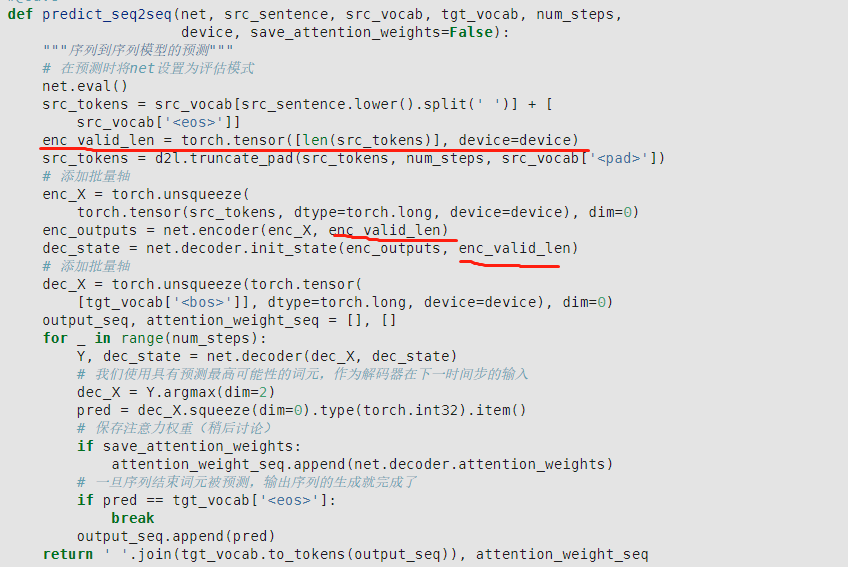
这里输出’X’的形状:应该是(num_steps,batch_size,embed_size),不然和下面的context就没法cat了,而且下面演示的时候,也是直接decoder(X, state),这里的X是(batch_size,num_steps),所以进到forward里面经过permute应该是(num_steps,batch_size,embed_size)!
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 修改
# self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1] # state
def forward(self, x, state):
x = self.embedding(x).permute(1, 0, 2)
context = state[-1].repeat(x.shape[0], 1, 1)
# 修改
# x_and_context = torch.cat((x, context), 2)
# output, state = self.rnn(x_and_context, state)
output, state = self.rnn(x, state)
output = self.dense(output).permute(1, 0, 2)
return output, state
我这样修改跟你的结果是一样的
说得没错。
当初我也有将decoder prediction改为training 方式。。。
不过后来我反过来做:事实上,我将context disable,效果bleu显著改善。 我想这本身state已经包含了context信息了,何必再额外分开搞个context?
1 Like
参数初始不同,可以使用next(iter( net.parameters) )观察
描述得好,但感觉 这个vocab_size应该改为num_steps
其实如果在mask CE中不计算mean()而使用sum(),那么此时的结果会更加直观
1 Like
应该是的,问题在于不符合设计,也和训练的流程不一致了。
Seq2SeqDecoder设计中state既和X拼接当做输入,又当做rnn初始的隐状态。这在训练的时候是没问题的,encoder最后的隐状态 encoder_state一次性拼接了所有时间步的X,也当做decoder的起始状态。
但在预测的时候,因为是用for循环一步一步更新的,每步都调用一次Seq2SeqDecoder,过程中改变了state, state变成了上一时刻的隐状态,输入rnn没有问题,但因为不再是encoder_state,和X拼接后就和训练不一致了。
比较简单的改法是修改Decoder,更新state的同时,保留encoder_state用于拼接。或者按照另一种设计方式,删除拼接步骤,encoder_state只用于做初始化。
2 Likes