这个不对啊,改了之后不收敛了zszszszszs
net = nn.Sequential(b1, b2, b3, b4, b5, nn.BatchNorm2d(512), nn.ReLU(),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
因为b5是卷积层的输出,还需要在b5之后加入nn.BatchNorm2d(512), nn.ReLU()
显存不够,224的话会报错out of mm
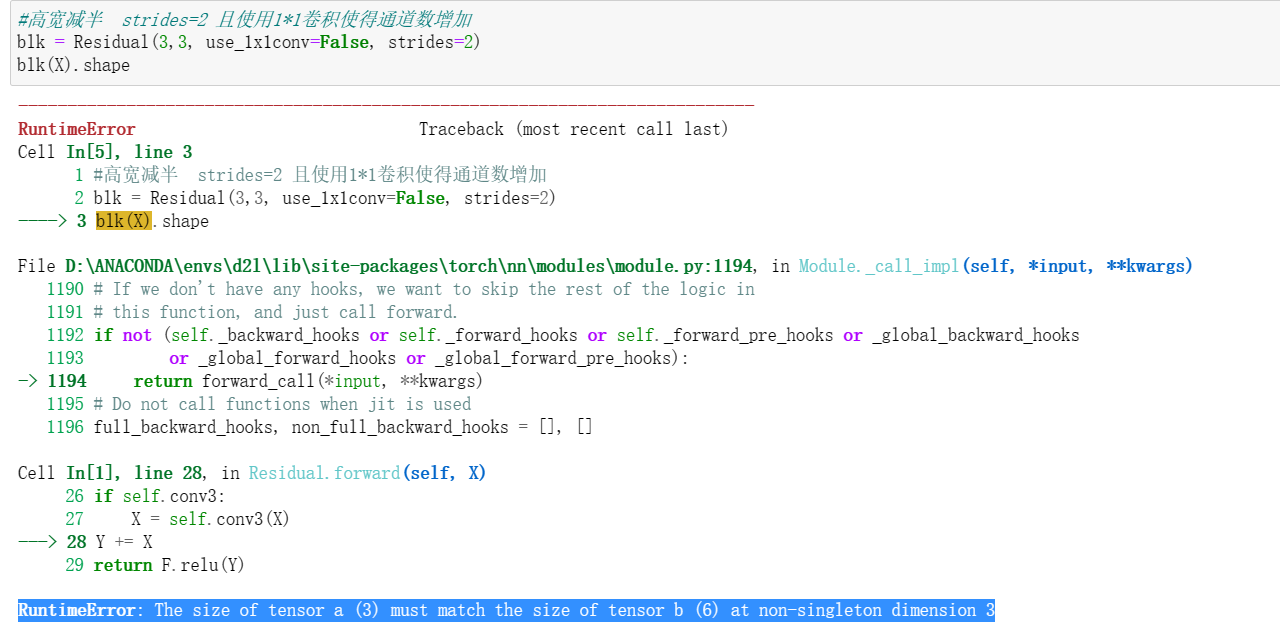
不对吧,block的最后一个不就是Batchsize吗(1*1卷积不做规范化)
同问,试了好几个不同的学习率都不行。。。。。
谢谢分享,我也想实现resnet50,可就算改的跟你一样还是有错,最后直接拿你的上手了,哈哈哈哈 ![]()
我明白了,我的错误是在还用的resnet_block,而没有换成bottleneck_block
在深度学习中,我们通常使用神经网络来建模函数类,其中函数的复杂性通常由神经网络的结构和参数化方式决定。即使函数类是嵌套的,我们也需要限制增加函数的复杂性,因为过于复杂的函数类可能会导致以下问题:
- 过拟合:如果函数类太复杂,它可能会过度拟合训练数据,导致模型无法泛化到新的数据上。这意味着模型在训练数据上表现得非常好,但在测试数据上表现很差。
- 计算资源:过于复杂的函数类需要更多的计算资源来训练和测试模型,这可能会导致训练时间变长,需要更多的存储空间,并增加训练过程中的计算成本。
- 可解释性:过于复杂的函数类可能很难解释,因为它们可能包含大量的参数和层次结构,使得理解模型的决策过程变得非常困难。
因此,为了避免上述问题,我们通常会限制模型的复杂性,例如使用正则化技术来控制模型参数的数量,使用剪枝技术来删除不必要的神经元和层,以及使用交叉验证等技术来评估模型的泛化能力。
2 Likes
想问一下为什么测试精度比训练精度低了0.1还要多啊
可以直接在代码中敲出
d2l.get_dataloader_workers
然后点击函数选择
go to definition
修改里面的数值应该就行了
1 Like
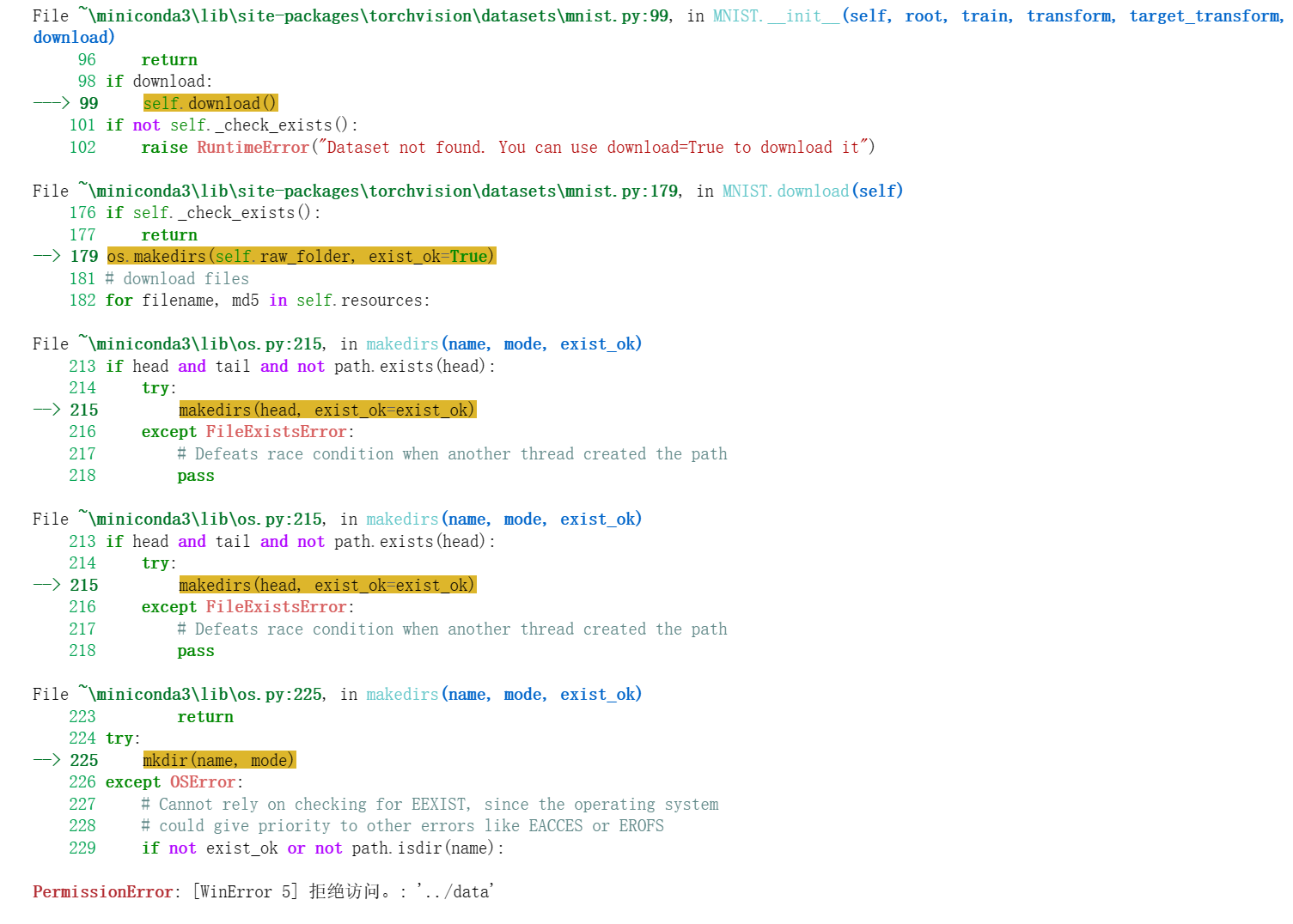
应该是下载数据集的时候出错,你没有当前下载路径的权限,你可以改一下下载路径
跑多少轮?模型越复杂,前期效果越差,轮数多了以后,比简单模型效果好
resnet
numref:fig_inception中的Inception块与残差块之间的主要区别是什么?在删除了Inception块中的一些路径之后,它们是如何相互关联的?
个人所见,尽管俩个网络的构建思路不同,Inception是为了使用不同的卷积核去提取不同的特征(同时使用少的参数),但是Resnet模块是为了保证更深的网络表达的函数囊括浅层的函数,使得更深的网络有意义。但是在架构上,可以将Resnet看作是一种特殊的Inception模块。
参考ResNet论文 :cite:He.Zhang.Ren.ea.2016中的表1,以实现不同的变体。
贴一下Resnet 18的训练结果
epoch: 0 loss= 274.33294677734375
epoch: 1 loss= 123.11670684814453
epoch: 2 loss= 98.39700317382812
epoch: 3 loss= 81.01783752441406
epoch: 4 loss= 65.5454330444336
epoch: 5 loss= 51.666439056396484
epoch: 6 loss= 37.66799545288086
epoch: 7 loss= 27.368988037109375
epoch: 8 loss= 18.34890365600586
epoch: 9 loss= 10.552614212036133
epoch: 10 loss= 9.15225601196289
epoch: 11 loss= 5.566713809967041
epoch: 12 loss= 2.6198325157165527
epoch: 13 loss= 0.49261292815208435
epoch: 14 loss= 0.2144828885793686
测试集准确度 0.9327999949455261
实现一下Resnet-34:
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
device = torch.device('cuda:0')
train_set = torchvision.datasets.FashionMNIST(
root='./dataMnist'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224))
])
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=128,
shuffle=True,
num_workers = 0
)
test_set = torchvision.datasets.FashionMNIST(
root='./dataMnist'
,train=False
,download=True
,transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224))
])
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=128,
shuffle=True,
num_workers = 0
)
#创建Resnet_block
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, b2=False, first_block = True):
super().__init__()
if(first_block and not b2):
stride = 2
self.conv_one = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, padding=0)
else:
self.conv_one = None
stride = 1
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
y = F.relu(self.bn1(self.conv1(x)))
y = self.bn2(self.conv2(y))
if(self.conv_one):
out = F.relu(y + self.conv_one(x))
else:
out = F.relu(y + x)
return out
def ResBlocks(nums, b2, in_channels, out_channels):
block = []
for i in range(nums):
if(i == 0):
block.append(ResBlock(in_channels, out_channels, b2, first_block = True))
else:
block.append(ResBlock(out_channels, out_channels, b2, first_block = False))
return nn.Sequential(*block)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = ResBlocks(3, True, 64, 64)
b3 = ResBlocks(4, False, 64, 128)
b4 = ResBlocks(6, False, 128, 256)
b5 = ResBlocks(3, False, 256, 512)
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1,1)), nn.Flatten(), nn.Linear(512, 10))
x = torch.zeros((1, 1, 224, 224))
for layer in net:
x = layer(x)
print(layer.__class__.__name__, "\t输出的形状为:", x.shape)
def init_weights(layer):
if type(layer)== nn.Linear or type(layer) == nn.Conv2d:
nn.init.xavier_uniform_(layer.weight) #初始化很重要,NiN随机初始化训练不动。。。
net.apply(init_weights)
print("Resnet18的结构为:", net)
optimizer = optim.SGD(net.parameters(), lr = 0.12)
loss = nn.CrossEntropyLoss(reduction='mean')
epoch = 10
losses = []
for i in range(epoch):
loss_sum = 0
for x, y in train_loader:
net = net.to(device)
x = x.to(device)
y = y.to(device)
y_hat = net(x)
loss_temp = loss(y_hat, y)
loss_sum += loss_temp
optimizer.zero_grad()
loss_temp.backward()
optimizer.step()
losses.append(loss_sum.cpu().detach().numpy()/train_set.data.shape[0])
print("epoch: ",i, "loss=", loss_sum.item())
acc = 0
with torch.no_grad():
for x, y in test_loader:
x = x.to(device)
y = y.to(device)
y_hat = net(x)
acc += torch.sum(y_hat.argmax(dim=1).type(y.dtype) == y)
print("测试集准确度",(acc/test_set.data.shape[0]).item())
plt.plot(range(epoch), losses)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
epoch: 0 loss= 379.17254638671875
epoch: 1 loss= 152.3948211669922
epoch: 2 loss= 121.77942657470703
epoch: 3 loss= 103.70003509521484
epoch: 4 loss= 89.28633117675781
epoch: 5 loss= 75.78622436523438
epoch: 6 loss= 62.75402069091797
epoch: 7 loss= 53.15045928955078
epoch: 8 loss= 42.1845703125
epoch: 9 loss= 34.198307037353516
测试集准确度 0.9125999808311462
对于更深层次的网络,ResNet引入了“bottleneck”架构来降低模型复杂性。请你试着去实现它。
x = torch.zeros((1, 1, 224, 224))
class bottleneck(nn.Module):
def __init__(self, c_num, conv_skip = True, stride = 1):
super().__init__()
self.conv_layer = nn.Sequential(
nn.Conv2d(c_num[0], c_num[1], kernel_size=1, padding=0, stride=1),
nn.BatchNorm2d(c_num[1]),
nn.ReLU(),
nn.Conv2d(c_num[1], c_num[1], kernel_size=3, padding=1, stride=stride),
nn.BatchNorm2d(c_num[1]),
nn.ReLU(),
nn.Conv2d(c_num[1], c_num[2], kernel_size=1, padding=0, stride=1),
nn.BatchNorm2d(c_num[2]),
nn.ReLU())
if(conv_skip):
self.conv_skip = nn.Conv2d(c_num[0], c_num[2], kernel_size=1, padding=0, stride=stride)
else:
self.conv_skip = None
def forward(self, x):
y = self.conv_layer(x)
if(self.conv_skip):
out = y + self.conv_skip(x)
else:
out = y + x
return out
def bottle_block(block_num, c_num, b2 = False):
block = []
for i in range(block_num):
if(i == 0 and not b2):
block.append(bottleneck(c_num, True, stride=2))
else:
block.append(bottleneck([c_num[2], c_num[1], c_num[2]], False))
return nn.Sequential(*block)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = bottle_block(3, [64, 64, 256])
b3 = bottle_block(4, [256, 128, 512])
b4 = bottle_block(6, [512, 256, 1024])
b5 = bottle_block(3, [1024, 512, 2048])
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1,1)), nn.Flatten(), nn.Linear(2048, 10))
for layer in net:
x = layer(x)
print(layer.__class__.__name__, "\t输出的形状为:", x.shape)
Sequential 输出的形状为: torch.Size([1, 64, 56, 56])
Sequential 输出的形状为: torch.Size([1, 256, 28, 28])
Sequential 输出的形状为: torch.Size([1, 512, 14, 14])
Sequential 输出的形状为: torch.Size([1, 1024, 7, 7])
Sequential 输出的形状为: torch.Size([1, 2048, 4, 4])
AdaptiveAvgPool2d 输出的形状为: torch.Size([1, 2048, 1, 1])
Flatten 输出的形状为: torch.Size([1, 2048])
Linear 输出的形状为: torch.Size([1, 10])
为什么即使函数类是嵌套的,我们仍然要限制增加函数的复杂性呢?
-
如无必要,勿增实体,拟合能力过强的函数会导致过拟合。
-
复杂的函数会消耗大量的计算资源
-
可解释性会变差
1 Like
残差块修改后的代码及效果图:
class Residual(nn.Module):
def __init__(self,input_channels,num_channels,use_1x1conv=False,strides=1):
super().__init__()
self.conv1=nn.Conv2d(input_channels,num_channels,kernel_size=3,padding=1,stride=strides)
self.conv2=nn.Conv2d(num_channels,num_channels,kernel_size=3,padding=1)
if use_1x1conv:
self.conv3=nn.Conv2d(input_channels,num_channels,kernel_size=1,stride=strides)
else:
self.conv3=None
self.bn1=nn.BatchNorm2d(input_channels)
self.bn2=nn.BatchNorm2d(num_channels)
def forward(self,X):
Y=self.conv1(self.bn1(F.relu(X)))
Y=self.conv2(self.bn2(F.relu(Y)))
if self.conv3:
X=self.conv3(X)
Y+=X
return Y

还是有作用的,整体曲线更平滑了,拟合能力也更强了。不知道为什么评论区有人说改进之后不收敛了,我看代码和我的也一样啊?不是很理解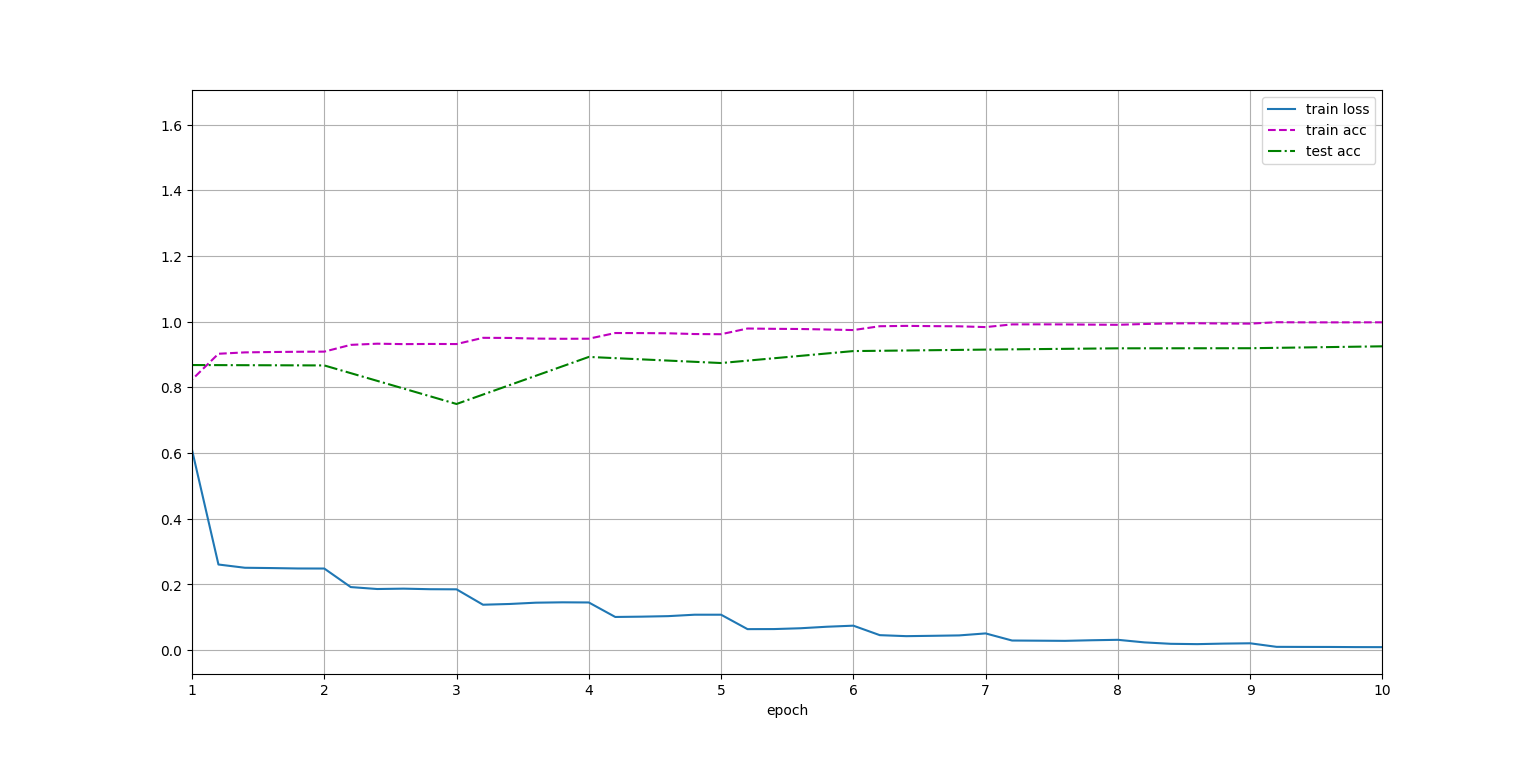
我也遇到过这个问题。
我遇到这个问题的情形是:GPU显存不够了,然后程序报错终止了,然后我再继续训练。就报了这个错。
解决办法是:把jupyter关掉后重启。
试试缩小lr和batch_size,亲测lr=0.005, batch_size=64 可以收敛
