我安装了d2l,为什么在notebook里面还是报错,ModuleNotFoundError: No module named ‘d2l’,请大佬指教
reinstall重新pip。
Preview:
pip install git+https://github.com/d2l-ai/d2l-en.git
RuntimeError: DataLoader worker (pid(s) 9128, 1780, 7056, 6240) exited unexpectedly
运行错误帮忙解决,谢谢
也碰到同样问题,搜索了下,疑似并行线程占用资源太多,没有解决,同求助
设置d2l包中dataloader函数的参数 num_workers = 0

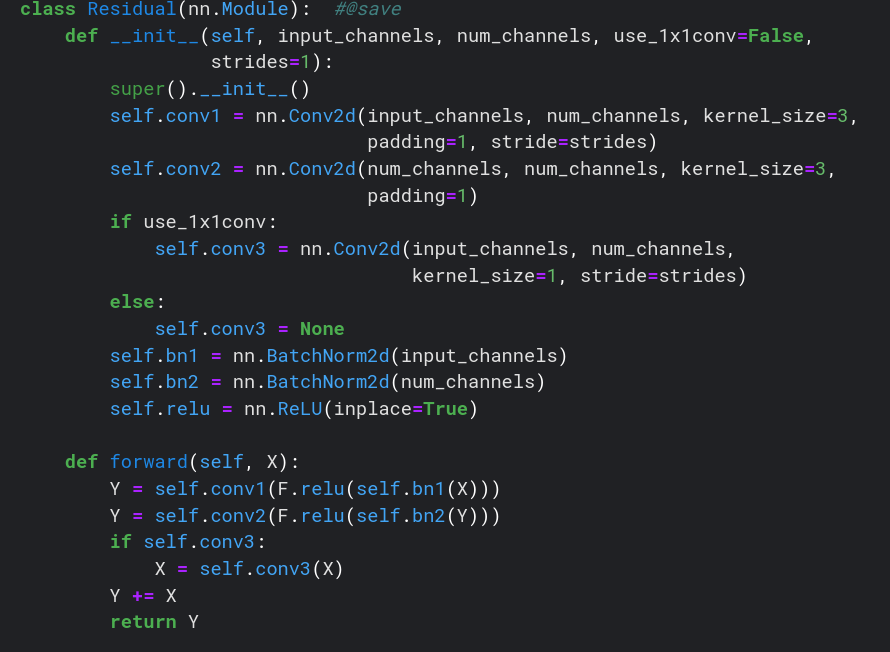
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
在forward中加入条件判断语句,速度应该会下降?(猜测)因为GPU没有分支预测,也无法乱序执行。建议放在__init__函数中根据条件先定义好模块,到forward中直接用。
such as
class Build_block(nn.Module):
def __init__(self,in_channels,out_channels,downsample=False):
super().__init__()
self.preprocess = nn.Sequential()
if downsample: # 如果需要做下采样,说明通道和分辨率都需要改变
self.conv1 = Basic_conv(in_channels,out_channels,stride = 2)
conv3 = Basic_conv(in_channels,out_channels,stride = 2)
self.preprocess.add_module('1x1conv',conv3)
else:
self.conv1 = Basic_conv(in_channels,out_channels,stride = 1)
self.conv2 = Basic_conv(out_channels,out_channels,stride = 1)
self.relu = nn.ReLU()
def forward(self,X):
Y = self.conv1(X)
Y = self.relu(Y)
Y = self.conv2(Y)
Y += self.preprocess(X)
return Y
老师您好,我按照教程第一次启动jupyter notebook 运行测试的d2l ,但是在点了run all之后浏览器自动跳转到最下面,之后就没有任何反应了,也不是按照教程下载数据包,这是怎么回事?和我用的浏览器有关系吗?
参照何凯明的文章和torchvision.models.resnet源码,以下我实现了ResNet50/101/152,相对于课程简单实现中Residual基础块,以下模型引入了bottleneck块。由于使用了和torchvision.models.resnet一致的层命名方式,可以直接加载torchvision中提供的预训练模型参数state_dict。供小伙伴们参考 
import torch
import torchvision
from torch import nn
from typing import List, Optional
class Bottleneck(nn.Module):
# ResNet bottleneck block, 1x1conv-3x3conv-1x1conv.
# downsample between stage layers to halve the size of input,
# cooperated with 3x3conv stride=2
# Normally the 3td conv possesses 4x channels compared to previous ones
expansion = 4
def __init__(self, in_channels, channels, stride=1, downsample: Optional[nn.Module]=None):
super(Bottleneck, self).__init__()
# Notice: In the first bottleneck of every residual stage,
# set 3x3conv stride=2 to halve the feature_map size,
# except the first residual stage (also named stage 2),
# which has been halved by MaxPooling with stirde=2 in stage 1.
self.conv1 = nn.Conv2d(in_channels, channels, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(channels)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(channels)
self.conv3 = nn.Conv2d(channels, channels * self.expansion, kernel_size=1,
stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(channels *self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.downsample == None:
identity = x
else:
identity = self.downsample(x)
out += identity # pixel-wise addtition
out = self.relu(out)
return out
class ResNet(nn.Module):
# Generic building func for ResNet-n
def __init__(self, layers: List[int], num_classess=1000):
super(ResNet, self).__init__()
self.in_channels = 64
self.bottleneck = Bottleneck
# The followling layers define stage 1(befor residual blocks)
self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size=7,
stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# The following layers define stage 2-5(residual blocks)
self.layer1 = self._make_layer(64, layers[0])
self.layer2 = self._make_layer(128, layers[1], stride=2)
self.layer3 = self._make_layer(256, layers[2], stride=2)
self.layer4 = self._make_layer(512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * self.bottleneck.expansion, num_classess)
# Build residual block
def _make_layer(self, channels, num_bottleneck, stride=1):
# 'stride' for 3x3conv or 1x1conv in downsample
# channel=64 in first residual stage
# stride=2 3x3conv & 1x1conv(downsmaple) in bottlenect 1 in in stage 2-5
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, channels * self.bottleneck.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels * self.bottleneck.expansion))
layers = []
# Append the first bottleneck of residual block
layers.append(self.bottleneck(
self.in_channels, channels, stride, downsample))
# Append the rest bottlenecks of residual block
self.in_channels *= self.bottleneck.expansion
# For stage 3-5, in_channels is half of the out_channels of previous stage
if channels != 64: # Indicate stage 3-5
self.in_channels = int(self.in_channels / 2)
for _ in range(1, num_bottleneck):
layers.append(self.bottleneck(self.in_channels, channels))
return nn.Sequential(*layers)
def forward(self, x):
# Stage 1
out = self.maxpool(self.relu(self.bn1(self.conv1(x))))
# Stage 2-5
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
# GlobalAvgPool-FC
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
# Construct ResNet-n
def ResNet50(num_classess):
return ResNet([3, 4, 6, 3], num_classess)
def ResNet101(num_classess):
return ResNet([3, 4, 23, 3], num_classess)
def ResNet152(num_classess):
return ResNet([3, 8, 36, 3], num_classess)
if __name__ == '__main__':
num_classess = 1000
# Build model structure
resnet152 = ResNet.ResNet152(num_classess)
# Load parameters from pretrained model
pretraind_model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',}
state_dict = torchvision.models.utils.load_state_dict_from_url(
pretraind_model_urls['resnet152'],
progress=True )
resnet152 = resnet152.load_state_dict(state_dict)7.6.2 的pytorch代码里面,定义了 self.relu = nn.ReLU(inplace=True),但是实际并没有用到,forward的里面用的是F.relu()函数,定义多余了吧。
拜托改一下头像吧,大兄dei, 误会大了
将学习率降低十倍试试。。。。。。。。。。。。。。。
数据集是个分类问题,为什么没有加resnet模型没有加softmax???
因为损失函数crossentropy融合了softmax层,可以搜一下crossentropy
知道了,谢谢知道了,谢谢知道了,谢谢知道了,谢谢
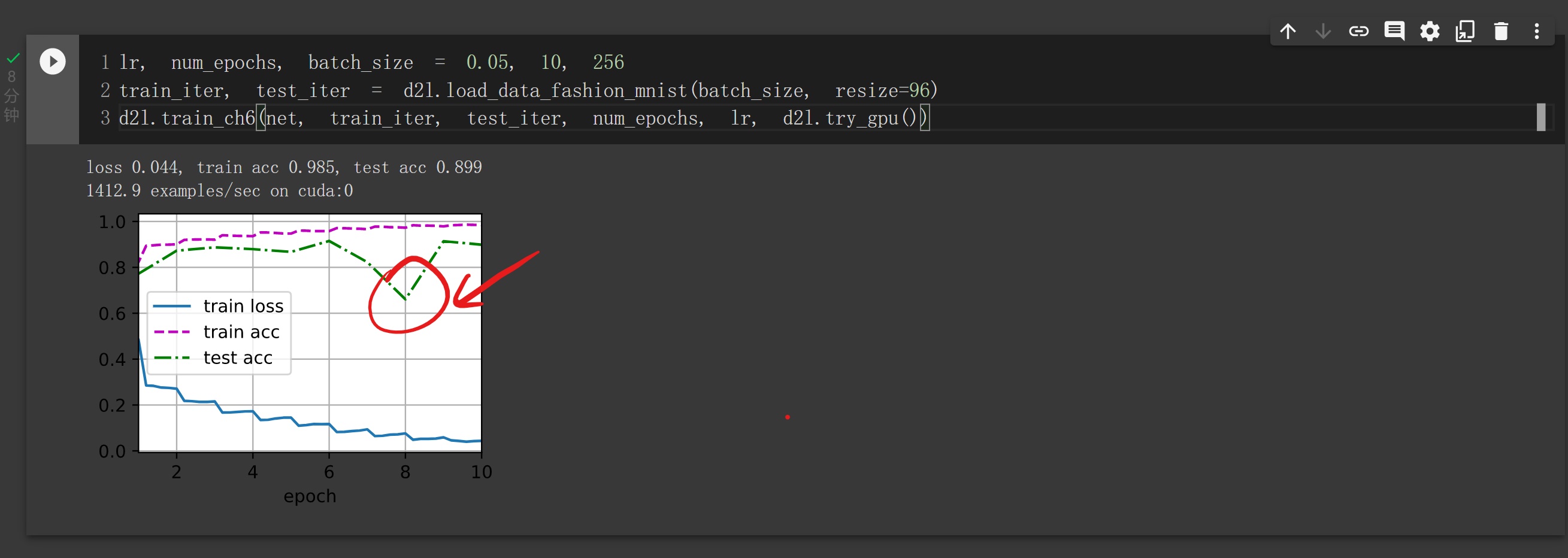
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
这里为什么resize到96?