我试了别的大小也可以,不知道这个是怎么确定的
GPU运行内存不够了。。。。。。。。。。。。。。。。。
请问如何找到d2l中的dataloade中的参数num_workers?谢谢。
减小batchsize的大小,然后结束掉占用显卡的进程可以解决这个问题的。我减少到16就可以了,最低可以减少到2,你可以试一下
打开你anaconda的d2l包安装位置(我的是E:\anaconda\envs\d2l\Lib\site-packages\d2l),找到torch.py,搜索load_data_fashion_mnist,找到这个函数中的num_workers即可
你看一下模型图啊,不能按文章这么理解啊,真照这句话,难道还给1*1convolution后面加relu吗,看模型图一目了然
Empty Traceback (most recent call last)
File ~\miniconda3\lib\site-packages\torch\utils\data\dataloader.py:1011, in _MultiProcessingDataLoaderIter._try_get_data(self, timeout)
1010 try:
→ 1011 data = self._data_queue.get(timeout=timeout)
1012 return (True, data)
File ~\miniconda3\lib\multiprocessing\queues.py:114, in Queue.get(self, block, timeout)
113 if not self._poll(timeout):
→ 114 raise Empty
115 elif not self._poll():
Empty:
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
Input In [9], in <cell line: 3>()
1 lr, num_epochs, batch_size = 0.05, 10, 256
2 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
----> 3 d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
File ~\miniconda3\lib\site-packages\d2l\torch.py:512, in train_ch6(net, train_iter, test_iter, num_epochs, lr, device)
510 metric = d2l.Accumulator(3)
511 net.train()
→ 512 for i, (X, y) in enumerate(train_iter):
513 timer.start()
514 optimizer.zero_grad()
File ~\miniconda3\lib\site-packages\torch\utils\data\dataloader.py:530, in _BaseDataLoaderIter.next(self)
528 if self._sampler_iter is None:
529 self._reset()
→ 530 data = self._next_data()
531 self._num_yielded += 1
532 if self._dataset_kind == _DatasetKind.Iterable and
533 self._IterableDataset_len_called is not None and
534 self._num_yielded > self._IterableDataset_len_called:
File ~\miniconda3\lib\site-packages\torch\utils\data\dataloader.py:1207, in _MultiProcessingDataLoaderIter._next_data(self)
1204 return self._process_data(data)
1206 assert not self._shutdown and self._tasks_outstanding > 0
→ 1207 idx, data = self._get_data()
1208 self._tasks_outstanding -= 1
1209 if self._dataset_kind == _DatasetKind.Iterable:
1210 # Check for _IterableDatasetStopIteration
File ~\miniconda3\lib\site-packages\torch\utils\data\dataloader.py:1173, in _MultiProcessingDataLoaderIter._get_data(self)
1169 # In this case, self._data_queue is a queue.Queue,. But we don’t
1170 # need to call .task_done() because we don’t use .join().
1171 else:
1172 while True:
→ 1173 success, data = self._try_get_data()
1174 if success:
1175 return data
File ~\miniconda3\lib\site-packages\torch\utils\data\dataloader.py:1024, in _MultiProcessingDataLoaderIter._try_get_data(self, timeout)
1022 if len(failed_workers) > 0:
1023 pids_str = ', '.join(str(w.pid) for w in failed_workers)
→ 1024 raise RuntimeError(‘DataLoader worker (pid(s) {}) exited unexpectedly’.format(pids_str)) from e
1025 if isinstance(e, queue.Empty):
1026 return (False, None)
RuntimeError: DataLoader worker (pid(s) 4056, 13616, 11320, 9348) exited unexpectedly
这是为啥啊?
只有一个training on cuda:0是怎么回事?
老师,您好,我进入jupyter点击run all之后,提示file failed to load,然后就没反应,这个是什么情况啊,该怎么解决呢?
ERROR: Failed building wheel for pandas
Failed to build pandas
ERROR: Could not build wheels for pandas which use PEP 517 and cannot be installed directly
朋友们,pip安装d2l时报这个错怎么解决呀?
以下为ResNet50的简单实现,请多多指教。
import torch
from torch import nn
from torch.nn import functional as F
# 1x1 conv -> 3x3 conv -> 1x1 conv
class Bottleneck(nn.Module):
def __init__(self, in_channels, channels, stride=1, use_1x1conv=False):
super(Bottleneck,self).__init__()
self.conv1 = nn.Conv2d(in_channels, channels, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(channels)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(channels)
self.conv3 = nn.Conv2d(channels, channels*4, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(channels*4)
if use_1x1conv:
self.conv4 = nn.Conv2d(
in_channels, channels*4, kernel_size=1, stride=stride
)
else:
self.conv4 = None
def forward(self, x):
# 1x1 conv 通道数:in_channels -> channels
out = F.relu(self.bn1(self.conv1(x)))
# 3x3 conv 通道数:channels -> channels
out = F.relu(self.bn2(self.conv2(out)))
# 1x1 conv 通道数: channels -> 4*channels
out = self.bn3(self.conv3(out))
# 恒等映射 or 1x1 conv
if self.conv4 == None:
identity = x
else:
identity = self.conv4(x)
out += identity
return F.relu(out)
def bottleneck_block(in_channels, channels, num_bottlenecks, not_FirstBlock = True):
# 第一个neck使用1x1conv,剩余的neck不使用1x1conv
# 第一个block的stride=1,后面的block的stride=2
blk = []
for i in range(num_bottlenecks):
if i == 0:
blk.append(
Bottleneck(in_channels, channels, stride=not_FirstBlock+1, use_1x1conv=True)
)
else:
blk.append(
Bottleneck(channels*4, channels)
)
return blk
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(*bottleneck_block(64, 64, 3, not_FirstBlock=False))
b3 = nn.Sequential(*bottleneck_block(64*4, 128, 3))
b4 = nn.Sequential(*bottleneck_block(128*4, 256, 3))
b5 = nn.Sequential(*bottleneck_block(256*4, 512, 3))
resnet50 = nn.Sequential(
b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(2048, 10)
)
3 Likes
残差单元的改进版本
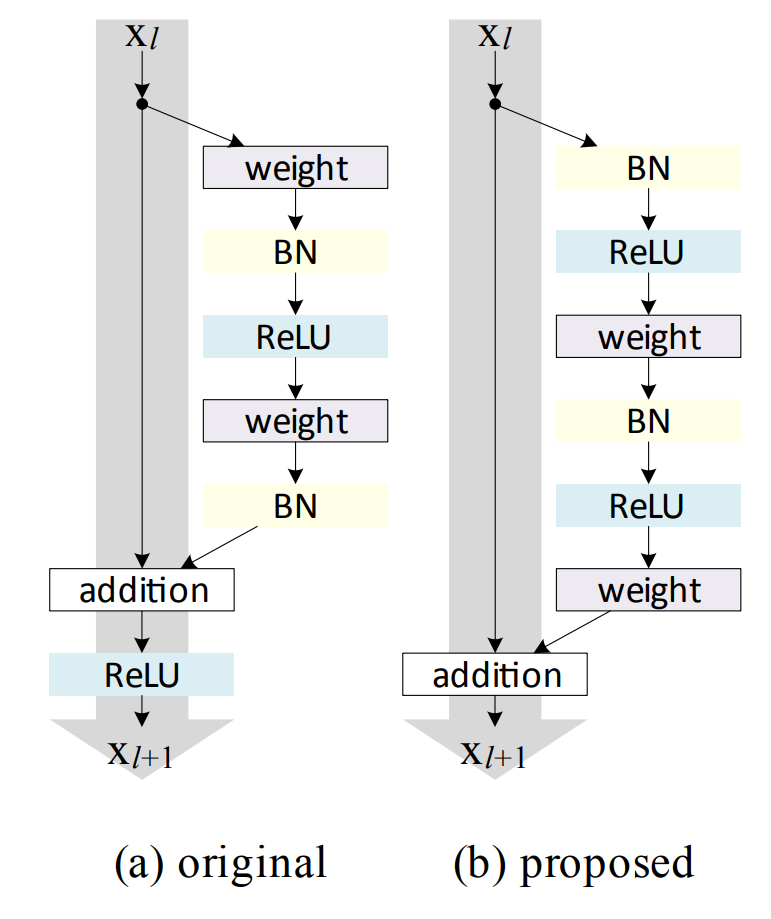
改进后的代码实现
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(input_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = self.conv1(F.relu(self.bn1(X)))
Y = self.conv2(F.relu(self.bn2(Y)))
if self.conv3:
X = self.conv3(X)
Y += X
return Y
其实,Residual 的 use_1x1conv 参数,可以去掉。
残差块:f(x) = g(x) + x
use_1x1conv 的目的是,在 g(x) 会改变特征图的通道数 / 高 / 宽的情况下,利用 1x1 卷积,调整 x 的形状(通道数 / 高 / 宽)。
因此,只需要判断 Residual 的参数,当 input_channels != num_channels || strides > 1 时,即特征图形状会发生改变时,调整 x 的形状即可。即 use_1x1conv 的传参可省略
3 Likes
单纯的对原函数x进行reshape是满足不了的,因为reshape必需使得 reshape前的输入像素总数=reshape后的输入像素总数,而1x1 卷积层能满足
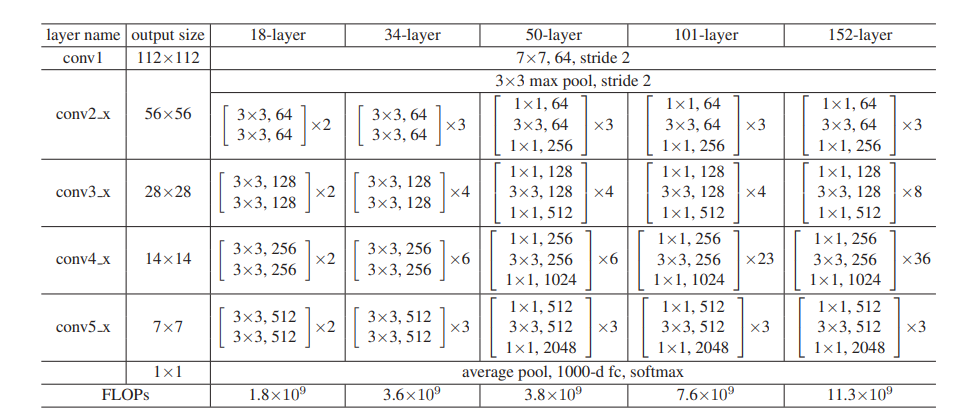
参考原论文ResNet-34 一共16个Residual模块,每个模块两个卷积层。加上第一个7*7卷积层和最后的全连接层一共34个卷积层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(*resnet_block(64, 64, 3, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 4))
b4 = nn.Sequential(*resnet_block(128, 256, 6))
b5 = nn.Sequential(*resnet_block(256, 512, 3))
Resnet34 = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
ResNet-18 训练结果
loss 0.016, train acc 0.996, test acc 0.892
1637.3 examples/sec on cuda:0
ResNet-34 训练结果
loss 0.042, train acc 0.985, test acc 0.810
1027.2 examples/sec on cuda:0
发现训练效果没有提高,是不是哪里出问题了?
2 Likes
Empty Traceback (most recent call last)
File ~\anaconda3\envs\pytorch-gpu\lib\site-packages\torch\utils\data\dataloader.py:1163, in _MultiProcessingDataLoaderIter._try_get_data(self, timeout)
1162 try:
→ 1163 data = self._data_queue.get(timeout=timeout)
1164 return (True, data)
File ~\anaconda3\envs\pytorch-gpu\lib\multiprocessing\queues.py:108, in Queue.get(self, block, timeout)
107 if not self._poll(timeout):
→ 108 raise Empty
109 elif not self._poll():
Empty:
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
Input In [4], in <cell line: 3>()
1 lr, num_epochs, batch_size = 0.1, 10, 128
2 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
----> 3 d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
File ~\anaconda3\envs\pytorch-gpu\lib\site-packages\d2l\torch.py:494, in train_ch6(net, train_iter, test_iter, num_epochs, lr, device)
492 metric = d2l.Accumulator(3)
493 net.train()
→ 494 for i, (X, y) in enumerate(train_iter):
495 timer.start()
496 optimizer.zero_grad()
File ~\anaconda3\envs\pytorch-gpu\lib\site-packages\torch\utils\data\dataloader.py:681, in _BaseDataLoaderIter.next(self)
678 if self._sampler_iter is None:
679 # TODO(Bug in dataloader iterator found by mypy · Issue #76750 · pytorch/pytorch · GitHub)
680 self._reset() # type: ignore[call-arg]
→ 681 data = self._next_data()
682 self._num_yielded += 1
683 if self._dataset_kind == _DatasetKind.Iterable and
684 self._IterableDataset_len_called is not None and
685 self._num_yielded > self._IterableDataset_len_called:
File ~\anaconda3\envs\pytorch-gpu\lib\site-packages\torch\utils\data\dataloader.py:1359, in _MultiProcessingDataLoaderIter._next_data(self)
1356 return self._process_data(data)
1358 assert not self._shutdown and self._tasks_outstanding > 0
→ 1359 idx, data = self._get_data()
1360 self._tasks_outstanding -= 1
1361 if self._dataset_kind == _DatasetKind.Iterable:
1362 # Check for _IterableDatasetStopIteration
File ~\anaconda3\envs\pytorch-gpu\lib\site-packages\torch\utils\data\dataloader.py:1325, in _MultiProcessingDataLoaderIter._get_data(self)
1321 # In this case, self._data_queue is a queue.Queue,. But we don’t
1322 # need to call .task_done() because we don’t use .join().
1323 else:
1324 while True:
→ 1325 success, data = self._try_get_data()
1326 if success:
1327 return data
File ~\anaconda3\envs\pytorch-gpu\lib\site-packages\torch\utils\data\dataloader.py:1176, in _MultiProcessingDataLoaderIter._try_get_data(self, timeout)
1174 if len(failed_workers) > 0:
1175 pids_str = ', '.join(str(w.pid) for w in failed_workers)
→ 1176 raise RuntimeError(‘DataLoader worker (pid(s) {}) exited unexpectedly’.format(pids_str)) from e
1177 if isinstance(e, queue.Empty):
1178 return (False, None)
RuntimeError: DataLoader worker (pid(s) 10320, 21396, 6460, 25096) exited unexpectedly
请问有大神知道解决方法吗
执行pip install matplotlib_inline
亲测有效
1 Like
你机器性能不强,跑的慢而已。我用P6000显卡,大约跑完10个epoch需要3分钟,用小笔记本跑完得用一小时。