为什么nin_block在实现的时候不把Max Pooling层放到block里面,而是单独写;但是,对比VGG的实现,在vgg_block里面就是加入了max pooling层?还是说都可以,就是习惯问题?
我在nin_block里面删除了一个1x1 conv layer之后的test accuracy = 0.884, 反而变高了?是因为少了参数,所以过拟合的可能性降低了吗?
前3个nin_block块卷积层后确实跟了max pooling层,但最后一个nin_block后跟着是一个AdaptiveAvgPool2d层。如果把max pooling放进nin_block中,最后一个nin_block就要一部分一分部拆开写。其实block只是最相同重复元素的抽象,方便网络定义。拆开一个个写效果是一样的。
请问为什么在最后一个NiN Block前添加Dropout层?
放一个后面测试predict的代码,根据图片大小改改(224,224)的地方就行了
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
def predict_ch3(net, test_iter,n=100): #@save
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X.to(device)).argmax(axis=1))
titles = [true + ‘\n’ + pred for true, pred in zip(trues, preds)]
d2l.show_images(X[0:n].reshape((n, 224, 224)), 1, n, titles=titles[0:n])
帅威正解,因为最后一个池化层不是MaxPool,所以没有把MaxPool放到模块构造函数里面
dropout 层都是为了防止过拟合吧.
“7.3.2 NiN模型”中第一段中说“。NiN使⽤窗口形状为11x11、5x5和3x3的卷积层,输出通道数量与AlexNet 中的相同”
这里的的 输出通道数量与 AlexNet 不相同啊。NiN模型的输出通道数在7.3.2节中可以看到是“96、256、384、10”;AlexNet模型的输出通道数在7.2.2节中可以看到是“64、128、256、512、512、10”。其中最后的10是由任务中的类别个数决定的。
而且中文问版书中写的都是“输出通道数量与AlexNet 中的相同”、“the corresponding numbers of output channels are the same as in AlexNet.”
求解,感谢。
7.2.2 讲的是VGG不是Alexnet
我直接把代码copy到colab(GPU:Tesla K80)上运行,结果在训练到第六个epoch loss爆增,acc爆减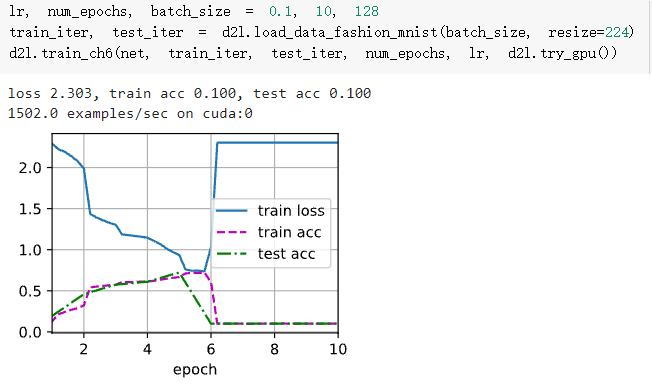
最大可能是用了relu作为激活函数的同时用了softmax做分类层的loss函数,当某一次训练传到最后一层的时候,某一节点激活过度(比如100),那么exp(100)=Inf,发生溢出,bp后所有的weight会变成NAN,然后从此之后weight就会一直保持NAN,于是loss就突然跳变了
连续2个1x1卷积核是为了加深网络提升网络的表达能力吗?
直接把256通道降为10通道可能会丢失很多信息吗?
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
构造net第一步时候,padding是不是要设置为1?
可以把学习率调成0.01,再试试吧。调完学习率,效果好些了
我的猜测是我们使用的数据集Fashion MNIST里面的数据仍然是相对简单的数据(28*28 pixel),原始的NiN模型对于这个数据集过于复杂了
btw,过拟合的意思是模型在训练集上的表现远好于测试集,但是在我们这个测试里面不是这种情况,所以我觉得这边说是因为降低了过拟合的可能性是不对的。
计算NiN的资源使用情况。
参数的数量是多少?
1st NiN:11x11x3(假设输入是RGB图像)x96+1x1x96x96+1x1x96x96=53280
pooling层没有参数故不计算
2nd NiN:5x5x96x256+1x1x256x256+1x1x256x256=745472
3rd NiN:3x3x256x384+1x1x384x384+1x1x384x384=1179648
4th NiN:3x3x384x10+1x1x10x10+1x1x10x10=34760
计算量是多少?
1st NiN:54x54x96+54x54x96+54x54x96
1st MaxPool2d:26x26x96
2st NiN:26x26x256+26x26x256+26x26x256
2nd MaxPool2d:12x12x256
3rd NiN: 12x12x384+12x12x384+12x12x384
3rd MaxPool2d:5x5x384
4th NiN:5x5x10+5x5x10+5x5x10
1st AdaptiveAvgPool2d:1x10
训练期间需要多少显存?
预测期间需要多少显存?
这个显存的问题之前的课后练习也有,不过一直不太会算,有没有人可以指导下。
一次性直接将 384×5×5 的表示缩减为 10×5×5 的表示,会存在哪些问题?
一次性把通道从384缩减成10应该会损失大量的信息
我同样也是删除一个1x1 conv layer之后准确率变高了,不是因为少了参数,过拟合可能性降低,这个1x1的conv layer层一共就1个参数,不是因为参数原因造成的。
而且你的train acc和test acc差距应该不大,不属于过拟合。
只能说目前的数据其实不需要很复杂的网络
说错了,虽然Fashion MNIST是28,但是丢进去之前做过resize了,所以计算量其实还是224