老师这节课上说了 显存里包含的内容有:参数的权重,参数的梯度,以及梯度反向传播过程中的中间值,最后还有数据(batch_size)。
所以你这样干算基本是没法算出来的。
我只能说,去掉一个1x1卷积层,在相同条件下训练,我的GPU显存少了0.8G。所以那一个卷积层就占了800MB。
2 Likes
可能时因为只通过一次卷积就将384个通道缩减为10个通道,感受野会比较有限,输出结果的每个位置都只能捕获到输入特征图对应位置3*3领域的信息,通过多级缩减,能够更好地扩大感受野,提高特征提取和表征的能力
6 Likes
图7.3.1 NiN的网络图,第二个NiN 块应该是padding=2(same),代码里是对的,图里写的是1。
1 Like
1*1的不是只有1个参数,和输入输出通道数相关。
3 Likes
单层1*1卷积层的nin块
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
结果:
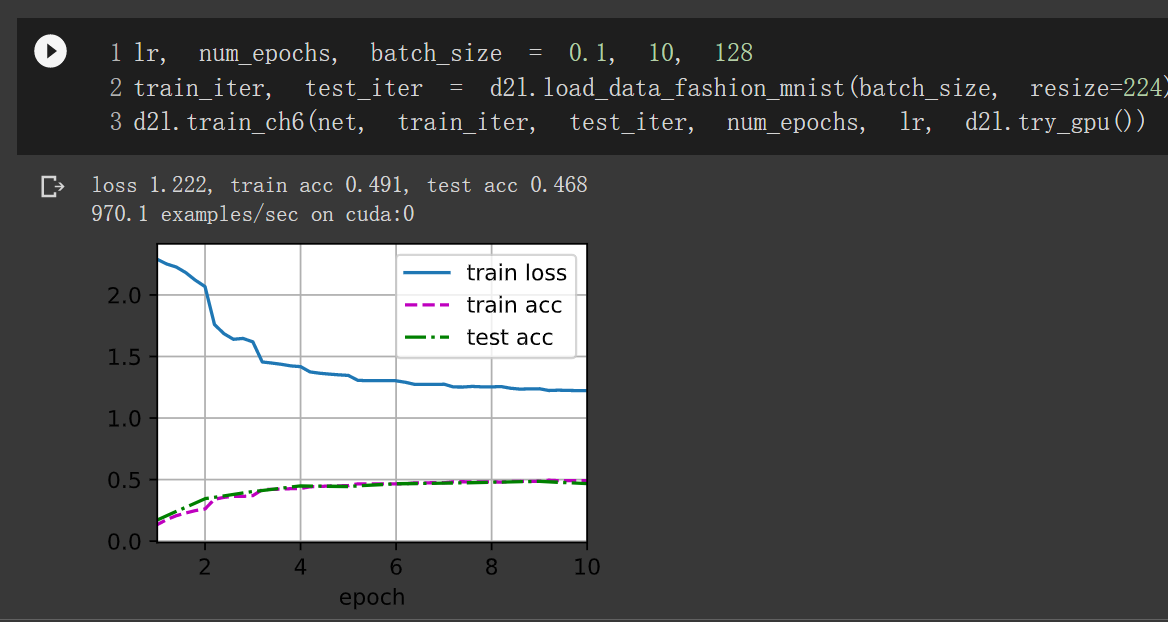
loss 0.317, train acc 0.884, test acc 0.885
1759.6 examples/sec on cuda:0
两层1*1卷积层的nin块
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU()),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
结果:
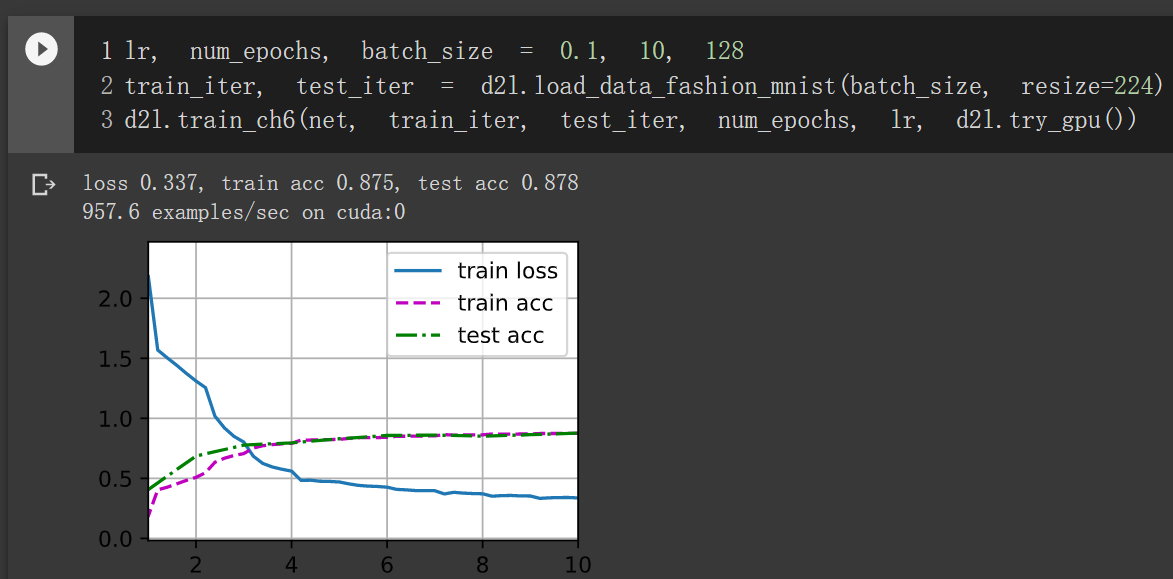
loss 0.317, train acc 0.883, test acc 0.884
1287.0 examples/sec on cuda:0
发现双层1*1卷积层没有显著提升性能,训练速度还是单层的70%左右。为什么要两层1*1卷积层呢?
论文原文 中提到的
Both layers map the local receptive field to a confidence value of the latent
concept.
这种网络的抽象能力似乎在这个图像识别问题上没有表现出很明显的效果
1 Like
NiN块中最后两个 1x1 卷积层起到了VGG中全连接层的作用。
这样的话每个channel只接受单个channel的输入,而不像全连接层一样接受所有神经元的输入
这两个1×1卷积层充当带有ReLU激活函数的逐像素全连接层。
文章7.3.1中的这个部分是否表达有误?在代码实现中可以看到使用了1×1卷积层之后仍需ReLU激活函数来增加非线性,也就是其实1×1卷积层仅能充当逐像素全连接层的作用,而不带有ReLU的增加非线性的作用?
我感觉计算量不对:
参考:
单层的参数量公式:(kernel x kernel) x(channel_input x channel_output)
单层的计算量公式:(channel_input x channel_output) x(kernel x kernel)x(out_map_h x out_map_w)
例如1st:nin ,1* 96 * 11* 11* 54* 54+96* 96* 1 * 1 * 54 * 54+96* 96* 1* 1* 54*54
1 Like
网上有个对于用两个1*1卷积的解释:第一个1x1卷积层实现featuremap的提取,第二个1x1卷积层进行featuremap的组合,但是不清楚对不对
画图时出现该报错
ValueError: svg is not a valid value for output; supported values are path , agg , macosx site:stackoverflow.com
可能需要修改
最后一层并没有添加softmax函数啊,最后一层只是用flatten展平了啊
hi,我也遇到了同样的问题,我觉得可能是网络初始化的问题,于是我试着重新初始化了net,发现是可行的
请问怎么选择卷积中的stride和padding呢?
按照计算(224+2乘以padding-11)/4+1,前面如何都算不出整数,有小数,就不知道内部怎么计算,答案是54。
padding=1,算出来54.75
padding=0,算出来54.25
个人觉得不用,因为最后都有多的行,1和0都可以
哥,你知不知道你在说啥,每个1x1是参数有1x96x54x54=279,936,一个参数的话我为什么要这一层,删了不就行了
调整NiN的超参数,以提高分类准确性。
依旧使用SGD,学习率调为0.12, epoch 15
epoch: 0 loss= 949.5301513671875
epoch: 1 loss= 541.0523071289062
epoch: 2 loss= 335.288818359375
epoch: 3 loss= 265.7752990722656
epoch: 4 loss= 236.0061492919922
epoch: 5 loss= 214.9103546142578
epoch: 6 loss= 200.35089111328125
epoch: 7 loss= 186.38710021972656
epoch: 8 loss= 173.8882293701172
epoch: 9 loss= 164.55499267578125
epoch: 10 loss= 157.58424377441406
epoch: 11 loss= 150.84255981445312
epoch: 12 loss= 145.72850036621094
epoch: 13 loss= 139.71893310546875
epoch: 14 loss= 134.76446533203125
测试集准确度 0.8855999708175659
为什么NiN块中有两个 1×1 卷积层?删除其中一个,然后观察和分析实验现象。
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
device = torch.device('cuda:0')
train_set = torchvision.datasets.FashionMNIST(
root='./dataMnist'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224))
])
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=128,
shuffle=True,
num_workers = 0
)
test_set = torchvision.datasets.FashionMNIST(
root='./dataMnist'
,train=False
,download=True
,transform=transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224))
])
)
test_loader = torch.utils.data.DataLoader(
test_set,
batch_size=128,
shuffle=True,
num_workers = 0
)
#创建Nin块
def Nin_block(in_channels, out_channels, padding, stride, kernel_size):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, padding=padding ,stride=stride, kernel_size=kernel_size),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU()
)
def Nin():
return nn.Sequential(
Nin_block(1, 96, stride=4, kernel_size=11, padding=0),
nn.MaxPool2d(kernel_size=3, stride=2),
Nin_block(96, 256, stride=1, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=3, stride=2),
Nin_block(256, 384, stride=1, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
Nin_block(384, 10, stride=1, kernel_size=3, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten() #去掉多余的维数
)
net = Nin()
# x = torch.zeros((1, 1, 224, 224))
# for layer in net:
# x = layer(x)
# print(layer.__class__.__name__, "\t输出的格式为: ", x.shape)
def init_weights(layer):
if type(layer)== nn.Linear or type(layer) == nn.Conv2d:
nn.init.xavier_uniform_(layer.weight) #初始化很重要,NiN随机初始化训练不动。。。
net.apply(init_weights)
print("Nin的结构为:", net)
optimizer = optim.SGD(net.parameters(), lr = 0.1)
loss = nn.CrossEntropyLoss(reduction='mean')
epoch = 10
losses = []
for i in range(epoch):
loss_sum = 0
for x, y in train_loader:
net = net.to(device)
x = x.to(device)
y = y.to(device)
y_hat = net(x)
loss_temp = loss(y_hat, y)
loss_sum += loss_temp
optimizer.zero_grad()
loss_temp.backward()
optimizer.step()
losses.append(loss_sum.cpu().detach().numpy()/train_set.data.shape[0])
print("epoch: ",i, "loss=", loss_sum.item())
acc = 0
with torch.no_grad():
for x, y in test_loader:
x = x.to(device)
y = y.to(device)
y_hat = net(x)
acc += torch.sum(y_hat.argmax(dim=1).type(y.dtype) == y)
print("测试集准确度",(acc/test_set.data.shape[0]).item())
plt.plot(range(epoch), losses)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
epoch: 0 loss= 993.8709716796875
epoch: 1 loss= 533.2142944335938
epoch: 2 loss= 361.1051330566406
epoch: 3 loss= 277.5993347167969
epoch: 4 loss= 232.45095825195312
epoch: 5 loss= 205.37686157226562
epoch: 6 loss= 187.60452270507812
epoch: 7 loss= 176.19105529785156
epoch: 8 loss= 165.3572540283203
epoch: 9 loss= 157.9745330810547
测试集准确度 0.8700000047683716
俩个可以多次融合通道信息
换成一个:
Nin的结构为: Sequential(
(0): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
)
(1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Sequential(
(0): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
)
(3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Sequential(
(0): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Dropout(p=0.5, inplace=False)
(7): Sequential(
(0): Conv2d(384, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(1, 1), stride=(1, 1))
(3): ReLU()
)
(8): AdaptiveAvgPool2d(output_size=(1, 1))
(9): Flatten(start_dim=1, end_dim=-1)
)
epoch: 0 loss= 847.5736694335938
epoch: 1 loss= 356.9827575683594
epoch: 2 loss= 261.1847839355469
epoch: 3 loss= 224.17762756347656
epoch: 4 loss= 196.07040405273438
epoch: 5 loss= 180.1049041748047
epoch: 6 loss= 171.22512817382812
epoch: 7 loss= 160.30470275878906
epoch: 8 loss= 153.3402099609375
epoch: 9 loss= 147.3529052734375
测试集准确度 0.8526999950408936
换成一个效果略低,俩个可以增加模型的非线性表达能力。
计算NiN的资源使用情况。参数的数量是多少?计算量是多少?
参数$96(11111+1)+(119696)2+256(9655+1)+(11256256)2+384(25633+1)+(11384384)2+10(38433+1)+2(1110*10)=1995284$
计算量:
$(5454961111)+(5454969696)2+(262625655)+(2626256256256)2+(121238433)+(1212384384384)+(103845533)+(105510*10)2 = 2.46910^{10}$
一次性直接将 384×5×5 的表示缩减为 10×5×5 的表示,会存在哪些问题?
信息损失过大?
1 Like
感觉文章中的logtis翻译成预估比较好吧
optimizer, lr, num_epochs, batch_size, resize = adam, 0.001, 10, 512, 96
epoch 10, loss 0.234, train acc 0.913, test acc 0.906
optimizer, lr, num_epochs, batch_size, resize = adam, 0.002, 10, 1024, 96
epoch 10, loss 0.241, train acc 0.912, test acc 0.901
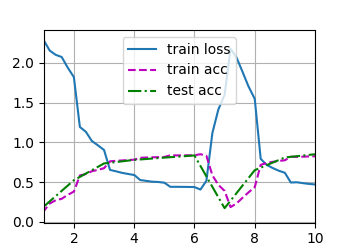
这是什么情况?Train_loss不稳定波动
lr=0.1 batchsize=128 epochs=10