你好,我这边试了一下,发现不加
.detach()也是可以的。
我的理解是:
Query 代表测试数据的特征Keys 代表训练数据的特征Values 代表训练数据的标签测了一下,运行了多轮, 感觉没区别. 带自身的 loss epoch =2 后不变. 去掉自身epoch=2后.会抖动.
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
# keys的形状:('n_train','n_train'-1)
keys = X_tile
# values的形状:('n_train','n_train'-1)
values = Y_tile
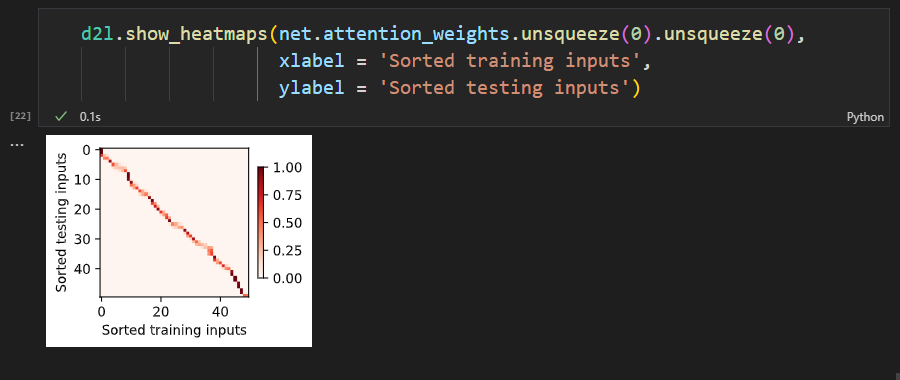
queries 是keys 的扩展,所以querier - keys 时候,主对角线元素肯定为0,导致主对角线上的attention_w就会变大,但queries - keys的操作,也会寻找非主对角线元素上的权值,也就是说寻找另一些特征,与keys中的某一个值有较大的权值关系。最后的y_hat 是attention_w 和 y_train (值)的矩阵乘积,也是权值累加求和
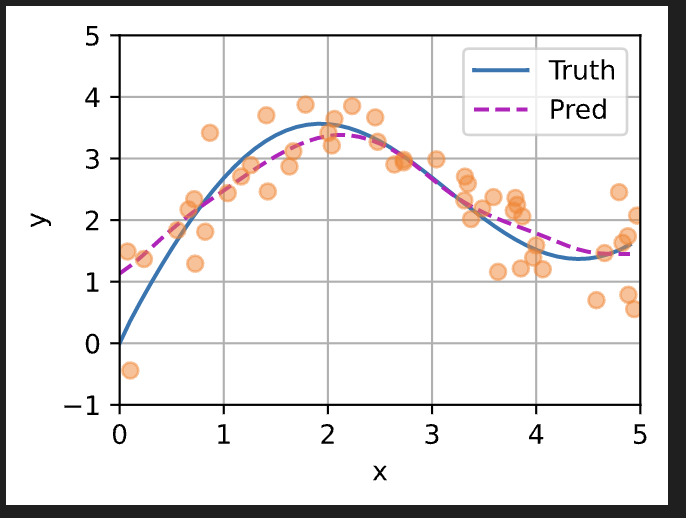
我觉得不平滑也是过拟合的问题,你把数据集的噪声项去掉之后再来训练带参数的核函数就会发现它变得平滑了
谢谢!我那天想的是,分子越小应该是分数越小,后来注意到e^[(-(1/2)^2]是一个在0处达到最大的函数,x-x_i越小,则函数值越大
个人认为:“query”(查询)用于确定关注的重点,“key”(键)表示数据集中的元素,“value”(值)与每个键相关联的实际值或信息
Attention接受三个输入,分别是Query,Key和Value。从输入和结果上来看,Attention层就是对输入的Value(inputs)进行一个加权的信息聚合处理,而不同的权值也就决定了输出的向量所具有的信息特性。而权值由Query和Key来确定:
Query和Key,经过一定的相似度(Compatibility)算法得到的相似度来确定不同Value所分配到的权重,并通过对所有的Value进行加权求和,得到一个(Query,Key)的作用所产生的输出,即通过每一个Query与所有的Key作用为对应的Value分配一个权重$w_i$,然后加权求和得到该Query对应产生的新Value。与Query越相似的Key,其对应的Value权重越大,即该Value的信息更深刻的映射在新Value中。
而这个Attention处理过程从作用和目的上来看,就是为了借助Attention机制提取出序列中的某些特征,理想状态下,最后经过Attention获得的结果,就是包含了我们想要得到的特征和信息的结果向量。
这是我的理解
为什么在训练的时候,要把对角线元素抛弃呢?不抛弃会怎么样呢?
刚刚做了实验,不抛弃就是非常地过拟合。抛弃了要好一点
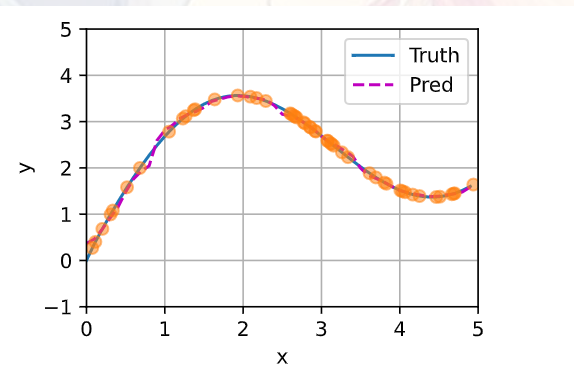
纠正一下jameshu的说法,不是完全匹配所有的y_train,而是跟y_train很接近,其实跟所有的y_train都不会相等,因为一个attention_weigths参数的模型还是比较简单,无法做到跟y_train完全匹配,只能是尽量靠近所有的y_train,使得loss最小
你的没有报错吗,不抛弃的话,w(x-xi)会有0项,而0项是没有导数的(element 0 of tensors does not require grad and does not have a grad_fn)
对第一点,有没有可能是他用的数据更少了,即更靠近的数据所占比重更大导致其他数据几乎对输出影响不大?
y_hat= net(x_test, keys, values).unsqueeze(1).detach()对于这句话里的unsqueeze,它扩张了一个维度,但是好像并没有什么作用,我把它去掉还是可以画图,倒不如说它向plot_kernel_reg(y_hat)输入了一个二维张量更出乎我的意料
非参数的Nadaraya-Watson核回归具有一致性 (consistency)的优点: 如果有足够的数据,此模型会收敛到最优结果。 尽管如此,我们还是可以轻松地将可学习的参数集成到注意力汇聚中。
这句话是不是错了?和课后问题直接冲突。而且讨论中也说明了
但现实中的采样数据肯定是有噪声的呀,难道先经过一次滤波,比如卡尔曼滤波
在计算keys和values的时候,为什么要进行如此复杂的操作,变成一个不是方阵的东西,不能够直接用X_tile和Y_tile充当他们吗
训练样本总地有 键,值,询问之分吧,询问用来对比与键的差异来确定各自键的值所对应的权重,所以地从训练样本中选个询问,剩下的作为键