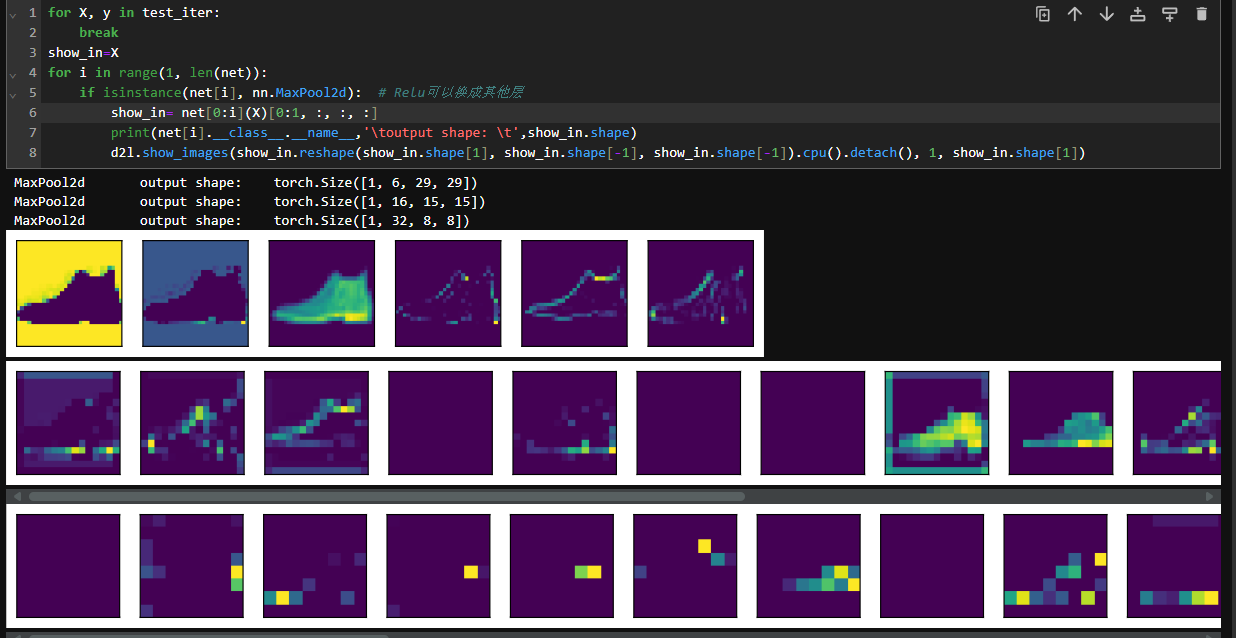
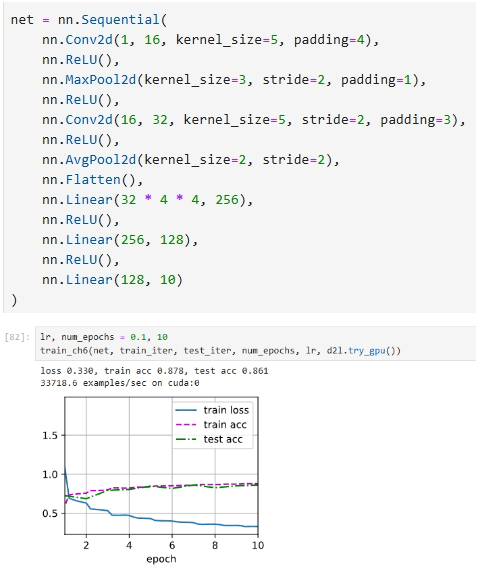
以下是我设计的网络:
mynet = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.ReLU(),
nn.Linear(120, 84), nn.ReLU(),
nn.Linear(84, 10))
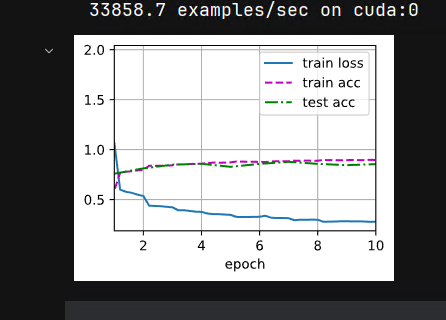
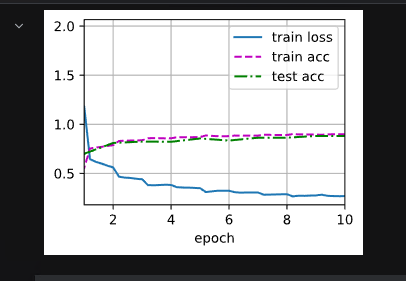
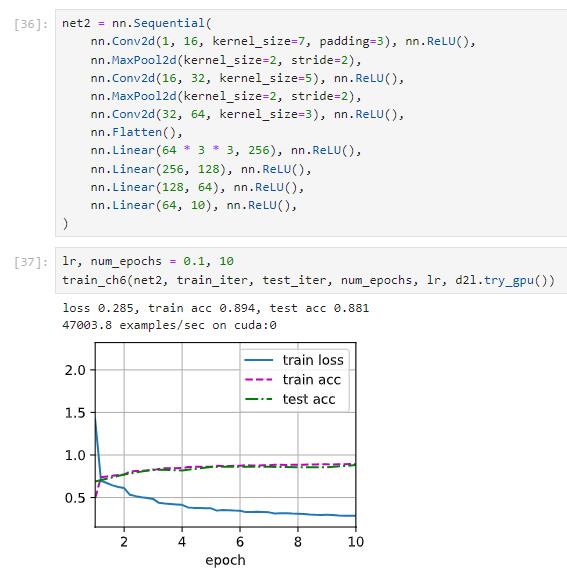
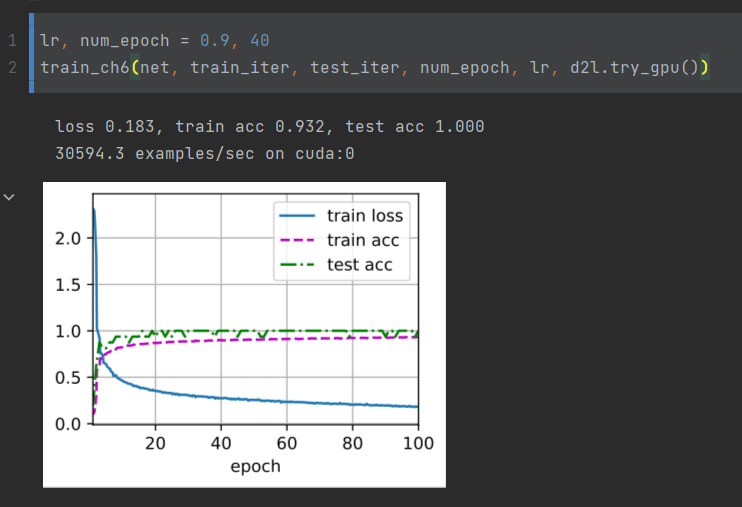
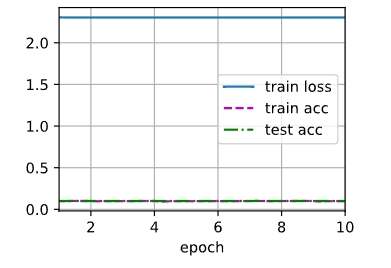
lr, num_epochs = 0.1, 10
train_ch6(mynet, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
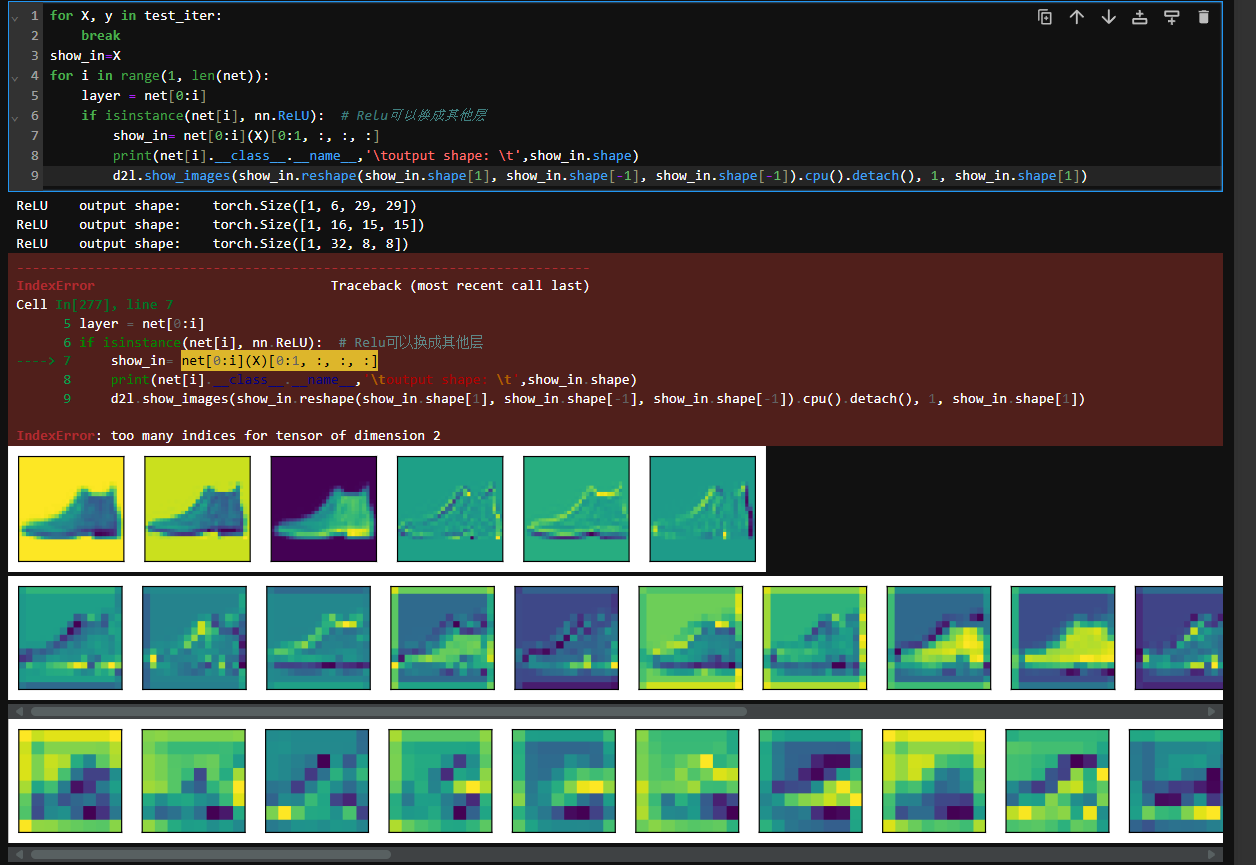
显示数据在进入第一层和第二层的图像
import torchvision
from torchvision import transforms
from torch.utils import data
trans = transforms.ToTensor()
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
# mnist_test是一个10000行的数据,每一行是一个tuple (tensor 和标签),每个tensor是一张图片(1,28,28),mnist_test[i][0]表示第i张图片
X, _ = next(iter(data.DataLoader(mnist_test, batch_size=4)))
# DataLoader 返回 一个迭代器 指向一个 batch_size的数据
# X是一个tensor (bbatch_size,(img size))
d2l.show_images(X.reshape(4,28,28),1,4,titles=['input']*4)
X, _ = next(iter(data.DataLoader(mnist_test, batch_size=4)))
X=mynet[:1](X.to('cuda'))
X=X.to('cpu')
d2l.show_images(X[:,0:3,:,:].permute(1,0,2,3).detach().reshape(12,28,28),3,4,titles=['Conv2d']*12)
X, _ = next(iter(data.DataLoader(mnist_test, batch_size=4)))
X=mynet[:2](X.to('cuda'))
X=X.to('cpu')
d2l.show_images(X[:,0:3,:,:].permute(1,0,2,3).detach().reshape(12,28,28),3,4,titles=['ReLU']*12)