maybe don’t try part above this train
我一开始也是这样,试试重启内核看看,或者重新运行所有代码,我的不知道为什么就好了
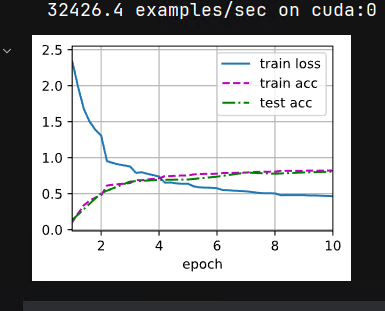
1.调整为maxpooling后:
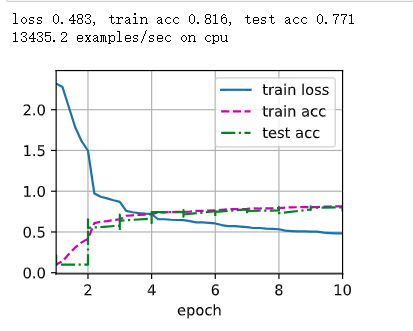
loss 0.431, train acc 0.841, test acc 0.796
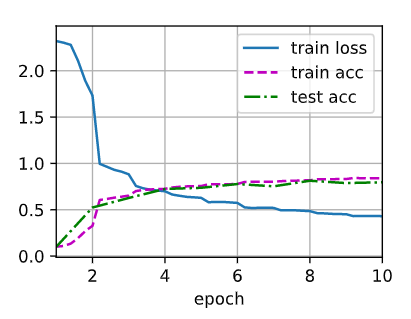
2.卷积核全部改成33,前面两层代替55,激活全部改成Relu,每两层卷积后面接一个最大池化,最后flatten,三个全连接改为240,120,10,训练epoch改成50,lr改成0.01,训练优化器改成adam,网络如下

训练结果如下:

感觉有点过拟合了,但是测试精度也比原来增加了10个点
增加weight_decay=0.005,epoch=25,拟合出一个还可以的模型
你代码敲错了,device在括号外面,应该是
device = next(iter(net.parameters())).device
1 Like
我觉得应该是lr设置太大了,改为0.1试一下
我个人建议用linux,然后别用Conda,少了很多麻烦。
你好,请问怎么调整train_ch6函数改用adam优化器呀
你好,请问怎么调整train_ch6函数改用adam优化器呢
在训练循环中,损失通常是计算为一批样本的平均损失。这样做的目的是使损失的量级独立于批次的大小,这样可以更容易地比较不同批次之间的损失,也有助于稳定训练过程。
在给定代码段中,l 是一批样本的平均损失,所以要计算整个批次的总损失,你需要将其乘以批次中的样本数量 X.shape[0]。随后,在累计损失和精度之后,你可以通过将这些值除以总样本数(metric[2])来计算整个训练集的平均损失和精度。
总结一下,将损失乘以批次大小并累计,然后再除以总样本数,等效于计算整个训练集的平均损失。这个方法可以使你更容易地跟踪训练过程中的损失,并且与批次大小无关。
第四题不太明白,请问第一层是6通道输出的话,那一个样本不是应该有6个feature map,9个样本不就应该有 9*6个feature map吗?

#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
“”“用GPU训练模型(在第六章定义)”""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print(‘training on’, device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel=‘epoch’, xlim=[1, num_epochs],
legend=[‘train loss’, ‘train acc’, ‘test acc’])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f’loss {train_l:.3f}, train acc {train_acc:.3f}, ’
f’test acc {test_acc:.3f}’)
print(f’{metric[2] * num_epochs / timer.sum():.1f} examples/sec ’
f’on {str(device)}’)
请问训练函数里metric = d2l.Accumulator(3)没有移到GPU里,metric.add(l * X.shape【0】, d2l.accuracy(y_hat, y), X.shape【0】)为什么不会报错呢?
请问训练函数里metric = d2l.Accumulator(3)没有移到GPU里,metric.add(l * X.shape【0】, d2l.accuracy(y_hat, y), X.shape【0】)为什么不会报错呢?
现在似乎无法在Colab跑LeNet。在第一步用pip安装环境的时候就会报错。请问有人知道该怎么解决吗?
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
arviz 0.15.1 requires pandas>=1.3.0, but you have pandas 1.2.4 which is incompatible.
google-colab 1.0.0 requires pandas==1.5.3, but you have pandas 1.2.4 which is incompatible.
google-colab 1.0.0 requires requests==2.31.0, but you have requests 2.25.1 which is incompatible.
jax 0.4.14 requires numpy>=1.22, but you have numpy 1.21.5 which is incompatible.
jaxlib 0.4.14+cuda11.cudnn86 requires numpy>=1.22, but you have numpy 1.21.5 which is incompatible.
mizani 0.9.3 requires pandas>=1.3.5, but you have pandas 1.2.4 which is incompatible.
plotnine 0.12.3 requires matplotlib>=3.6.0, but you have matplotlib 3.5.1 which is incompatible.
plotnine 0.12.3 requires numpy>=1.23.0, but you have numpy 1.21.5 which is incompatible.
plotnine 0.12.3 requires pandas>=1.5.0, but you have pandas 1.2.4 which is incompatible.
scipy 1.11.2 requires numpy<1.28.0,>=1.21.6, but you have numpy 1.21.5 which is incompatible.
tensorflow 2.13.0 requires numpy<=1.24.3,>=1.22, but you have numpy 1.21.5 which is incompatible.
tweepy 4.13.0 requires requests<3,>=2.27.0, but you have requests 2.25.1 which is incompatible.
xarray 2023.7.0 requires pandas>=1.4, but you have pandas 1.2.4 which is incompatible.
yfinance 0.2.28 requires pandas>=1.3.0, but you have pandas 1.2.4 which is incompatible.
yfinance 0.2.28 requires requests>=2.31, but you have requests 2.25.1 which is incompatible.
学习率太高了,对于ReLU来说。把学习率调小就会收敛。
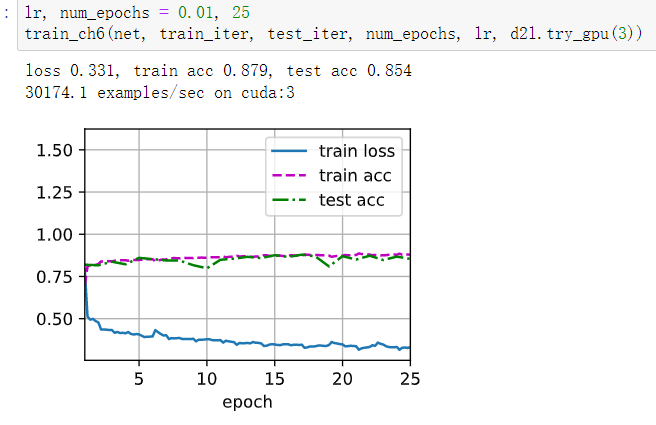
我将所有sigmoid更换为了relu, 所有avgpool更换为了maxpool, 将SGD更换为了Adam, 并在参数初始化时用了kaiming_normal_, lr设置为0.005, epoch 10-20均可. 获得了loss 0.148, train acc 0.944 test acc 0.900的优异数据. 虽然有点过拟合, 但在测试集上的准确率还是很客观的, 从图像上看, 仅在2个epoch左右,两个集上的acc就快速上升了, loss也快速下降了 (-_-)
Q1从你的实验结果来看,我觉得Max Pooling在epoch次数翻倍后,在测试集上的精度没有Avg Pooling高,不是过拟合。因为epoch 10->20,Max Pooling的训练集精度、测试集精度都是提升的。没有出现比较典型的过拟合现象。
1,我把平均池化换成最大池层之后(里面的参数值没有变),loss变大,准确率下降
这是MaxPool: