我也是,这里面的原因是什么?有数学关系吗?
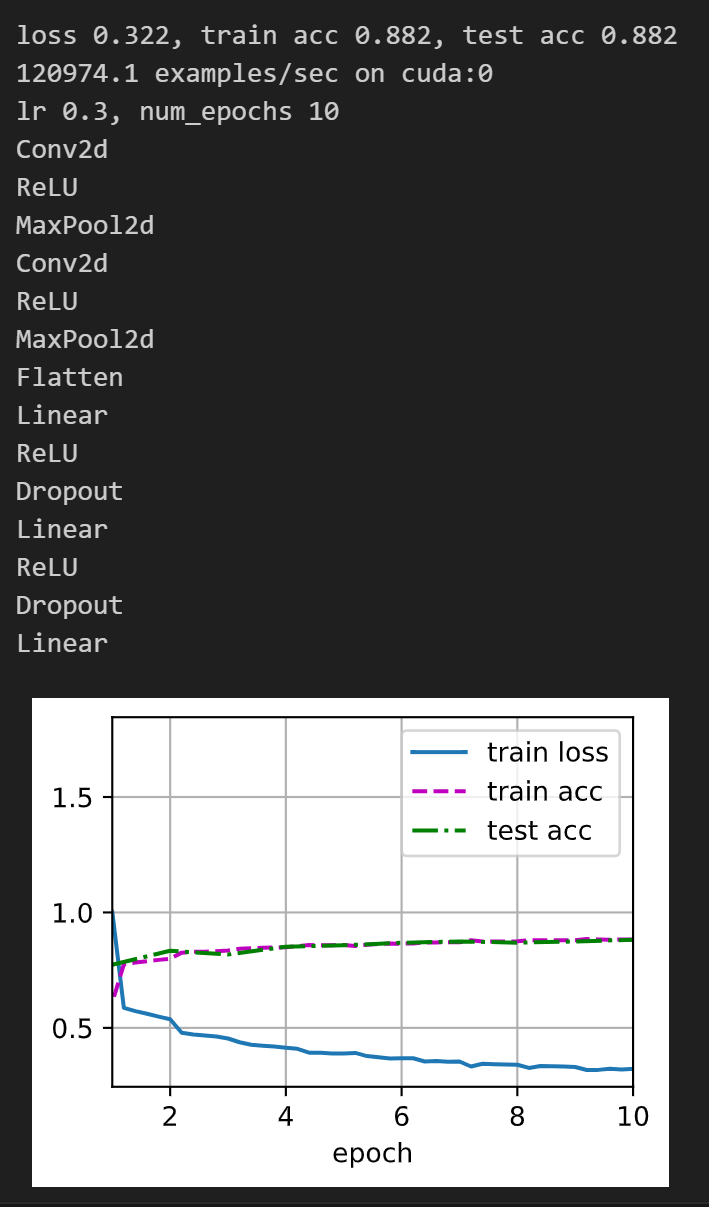
我的代码可以在Colab跑,中间有些累赘的地方没有删除,请忽略 ![]()
import torch
import torchvision.datasets
from torch import nn
import sys,os
from torch.utils.data import DataLoader
import time
from numpy import size, dtype, argmax
from torch import nn
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
#用矢量图显示
def use_svg_display():
display.set_matplotlib_formats('svg')
#设置图的尺寸
def set_figsize(figsize=(3.5,2.5)):
use_svg_display()
plt.rcParams['figure.figsize'] = figsize
#设置matplotlib的轴
def set_axes(axes,xlabel,ylabel,xlim,ylim,xscale,yscale,legend):
axes.set_xlabel(xlabel)
axes.set_ylabel(ylabel)
axes.set_xscale(xscale)
axes.set_yscale(yscale)
axes.set_xlim(xlim)
axes.set_ylim(ylim)
if legend:
axes.legend(legend)
axes.grid()
#每次返回batch_size个随机样本的特征和标签
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices=list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
j=torch.LongTensor(indices[i:min(i+batch_size,num_examples)])
yield features.index_select(0,j),labels.index_select(0,j)
#使用mm函数做矩阵乘法
def linreg(X,w,b):
return torch.mm(X,w) + b
#定义损失函数
def squared_loss(y_hat,y):
return (y_hat-y.view(y_hat.size()))**2/2
#定义优化算法
def sgd(params,lr,batch_size):
for param in params:
param.data-=lr*param.grad/batch_size
#将数值标签转换成相应的文本标签
def get_fashion_mnist_labels(labels):
text_labels=['t-shirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','ankle boot']
return [text_labels[int(i)]for i in labels]
#定义计时器
class Timer:
def __init__(self):
self.times=[]
self.start()
def start(self):
self.tik=time.time()
def stop(self):
self.times.append(time.time()-self.tik)
return self.times[-1]
def avg(self):
return sum(self.times)/len(self.times)
def sum(self):
return sum(self.times)
def cumsum(self):
return np.array(self.times).cumsum().tolist()
#可以在一行里画出多张图像和对于标签的函数
def show_fashion_mnist(images,labels):
use_svg_display()
_,figs=plt.subplots(1,len(images),figsize=(12,12))
for f,img,lbl in zip(figs,images,labels):
f.imshow(img.view((28,28)).numpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
plt.show()
#对多个变量进行累加
class Accumulator:
def __init__(self,n):
self.data=[0.0]*n
def add(self,*args):
self.data=[a+float(b) for a,b in zip(self.data,args)]
def reset(self):
self.data=[0.0]*len(self.data)
def __getitem__(self,idx):
return self.data[idx]
def accuracy(y_hat,y):
if len(y_hat.shape)>1 and y_hat.shape[1]>1:
y_hat=y_hat.argmax(axis=1)
cmp=y_hat.type(y.dtype)==y
return float(cmp.type(y.dtype).sum())
#评价准确率
def evaluate_accuracy(data_iter,net):
if isinstance(net,torch.nn.Module):
net.eval()
metric=Accumulator(2)
with torch.no_grad():
for X,y in data_iter:
metric.add(accuracy(net(X),y))
#评价准确率(使用GPU)
def evaluate_accuracy_gpu(net,data_iter,device=None):
if isinstance(net,nn.Module):
net.eval()
if not device:
device=next(iter(net.parameters())).device
metric=Accumulator(2)
with torch.no_grad():
for X,y in data_iter:
if isinstance(X,list):
X=[x.to(device) for x in X]
else:
X=X.to(device)
y=y.to(device)
metric.add(accuracy(net(X),y),y.numel())
return metric[0]/metric[1]
#神经网络训练函数
def train_ch3(net,train_iter,test_iter,loss,num_epochs,batch_size,params=None,lr=None,optimizer=None):
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n=0.0,0.0,0
for X,y in train_iter:
y_hat=net(X)
l=loss(y_hat,y).sum()
#梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
if optimizer is None:
sgd(params,lr,batch_size)
else:
optimizer.step()
train_l_sum+=l.item()
train_acc_sum+=(y_hat.argmax(dim=1)==y).sum().item()
n+=y.shape[0]
test_acc=evaluate_accuracy(test_iter,net)
print('epoch %d,loss %.4f,train acc %.3f,test acc %.3f'%(epoch+1,train_l_sum/n,train_acc_sum/n,test_acc))
#在动画中绘制数据
class Animator:
def __init__(self,xlabel=None,ylabel=None,legend=None,xlim=None,ylim=None,xscale='linear',yscale='linear',fmts=('-','m--','g-','r:'),nrows=1,ncols=1,figsize=(3.5,2.5)):
if legend is None:
legend=[]
use_svg_display()
self.fig,self.axes=plt.subplots(nrows,ncols,figsize=figsize)
if nrows*ncols==1:
self.axes=[self.axes,]
self.config_axes=lambda :set_axes(
self.axes[0],xlabel,ylabel,xlim,ylim,xscale,yscale,legend
)
self.X,self.Y,self.fmts=None,None,fmts
def add(self,x,y):
#向图表中添加多个数据点
if not hasattr(y,'__len__'):
y=[y]
n=len(y)
if not hasattr(x,'__len__'):
x=[x]*n
if not self.X:
self.X=[[] for _ in range(n)]
if not self.Y:
self.Y=[[] for _ in range(n)]
for i,(a,b) in enumerate(zip(x,y)):
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x,y,fmt in zip(self.X,self.Y,self.fmts):
self.axes[0].plot(x,y,fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
#gpu
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus():
devices=[torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
#用gpu训练模型
def train_ch6(net,train_iter,test_iter,num_epochs,lr,device):
def init_weights(m):
if type(m)==nn.Linear or type(m)==nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on',device)
net.to(device)
optimizer=torch.optim.SGD(net.parameters(),lr=lr)
loss=nn.CrossEntropyLoss()
animator=Animator(xlabel='epoch',xlim=[1,num_epochs],legend=['train loss','train acc','test acc'])
timer,num_batches=Timer(),len(train_iter)
for epoch in range(num_epochs):
metric=Accumulator(3)
net.train()
for i ,(X,y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X,y=X.to(device),y.to(device)
y_hat=net(X)
l=loss(y_hat,y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l*X.shape[0],accuracy(y_hat,y),X.shape[0])
timer.stop()
train_l=metric[0]/metric[2]
train_acc=metric[1]/metric[2]
if (i+1)%(num_batches//5)==0 or i==num_batches-1:
animator.add(epoch+(i+1)/num_batches,(train_l,train_acc,None))
test_acc=evaluate_accuracy_gpu(net,test_iter)
animator.add(epoch+1,(None,None,test_acc))
print(f'loss{train_l:.3f},train acc{train_acc:.3f},test acc{test_acc:.3f}')
print(f'{metric[2]*num_epochs/timer.sum():.1f}example/sec on{str(device)}')
#转换形状
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape : (batch,*,*,...)
return x.view(x.shape[0], -1)
#定义随机初始化模型参数
def init_params(num_inputs):
w=torch.randn((num_inputs,1),requires_grad=True)
b=torch.zeros(1,requires_grad=True)
return [w,b]
#定义L2范数惩罚项
def l2_penalty(w):
return (w**2).sum()/2
#使用4个进程来读取数据
def get_dataloader_workers():
return 4
net=nn.Sequential(
nn.Conv2d(1,6,5,padding=2),
nn.Sigmoid(),
nn.AvgPool2d(2,2),
nn.Conv2d(6,16,5),
nn.Sigmoid(),
nn.AvgPool2d(2,2),
nn.Flatten(),
nn.Linear(16*5*5,120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
X=torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
batch_size=256
train_data=torchvision.datasets.FashionMNIST(root='LeNet',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data=torchvision.datasets.FashionMNIST(root='LeNet',train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_iter=DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True, num_workers=get_dataloader_workers())
test_iter=DataLoader(dataset=test_data, batch_size=batch_size, shuffle=False, num_workers=get_dataloader_workers())
lr,num_epochs=0.9,10
train_ch6(net, train_iter, test_iter, num_epochs, lr, try_gpu())
Q4放在epochs循环里的话,会报错一口气处理20张图像,所以直接停止的错误,放在循环外就没事了。