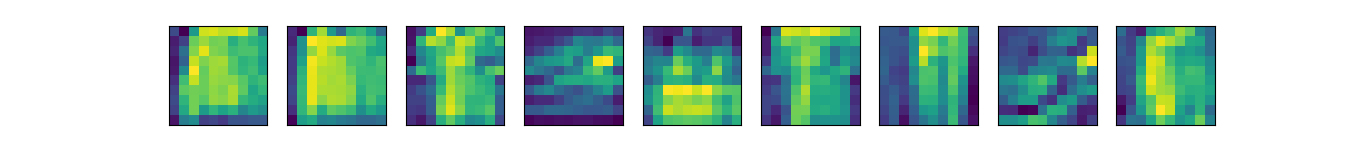Q1: 将平均汇聚层替换为最大汇聚层,会发生什么?
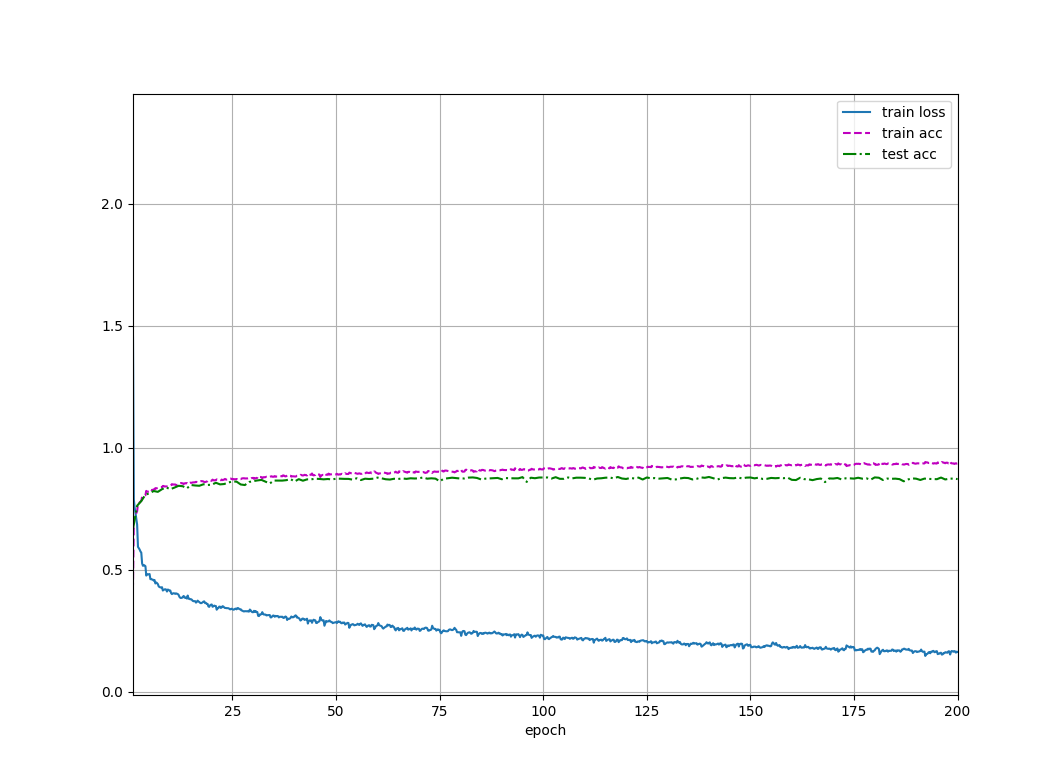
A1: 简单进行了对比,可以看到相较于Max Pooling,Avg Pooling的过拟合程度更小,同时测试集的分类准确率要高一些。
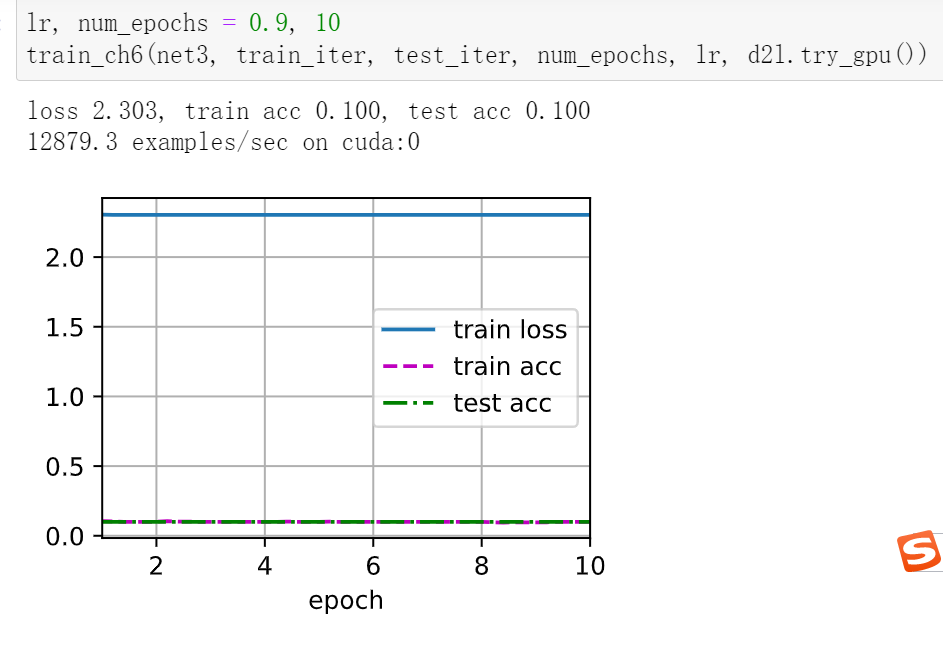
Avg Pooling, epoch 10, lr 0.9: loss 0.465, train acc 0.825, test acc 0.793
Max Pooling, epoch 10, lr 0.9: loss 0.432, train acc 0.838, test acc 0.776
Avg Pooling, epoch 20, lr 0.9: loss 0.356, train acc 0.867, test acc 0.857
Max Pooling, epoch 20, lr 0.9: loss 0.316, train acc 0.883, test acc 0.849
Q2: 尝试构建一个基于LeNet的更复杂的网络,以提高其准确性。
# 模型构造如下
changed_net = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=5, padding=2), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
# nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
# nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(16, 32, kernel_size=3, padding=1), nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
# nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(32 * 3 * 3, 128), nn.Sigmoid(),
nn.Linear(128, 64), nn.Sigmoid(),
nn.Linear(64, 32), nn.Sigmoid(),
nn.Linear(32, 10)
)
网络结构如下
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 8, 28, 28] 208
ReLU-2 [-1, 8, 28, 28] 0
AvgPool2d-3 [-1, 8, 14, 14] 0
Conv2d-4 [-1, 16, 14, 14] 1,168
ReLU-5 [-1, 16, 14, 14] 0
AvgPool2d-6 [-1, 16, 7, 7] 0
Conv2d-7 [-1, 32, 7, 7] 4,640
ReLU-8 [-1, 32, 7, 7] 0
AvgPool2d-9 [-1, 32, 3, 3] 0
Flatten-10 [-1, 288] 0
Linear-11 [-1, 128] 36,992
Sigmoid-12 [-1, 128] 0
Linear-13 [-1, 64] 8,256
Sigmoid-14 [-1, 64] 0
Linear-15 [-1, 32] 2,080
Sigmoid-16 [-1, 32] 0
Linear-17 [-1, 10] 330
================================================================
Total params: 53,674
Trainable params: 53,674
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.19
Params size (MB): 0.20
Estimated Total Size (MB): 0.40
----------------------------------------------------------------
Avg Pooling, epoch 20, lr 0.6: loss 0.308, train acc 0.885, test acc 0.863
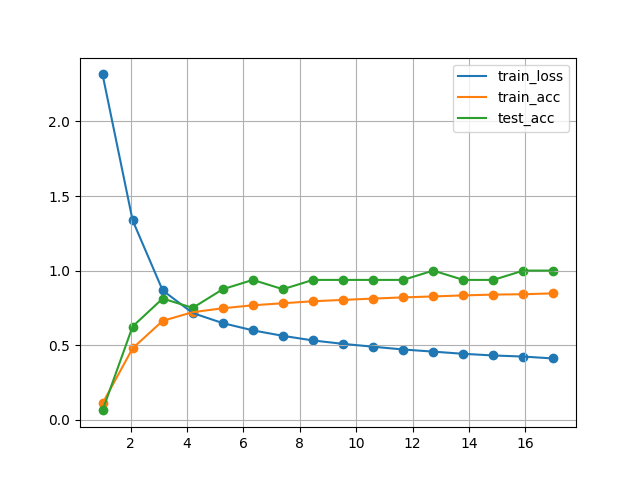
Q3: 在MNIST数据集上尝试以上改进的网络。
# 使用Mnist数据集
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.MNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.MNIST(
root="../data", train=False, transform=trans, download=True)
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=d2l.get_dataloader_workers())
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=True,
num_workers=d2l.get_dataloader_workers())
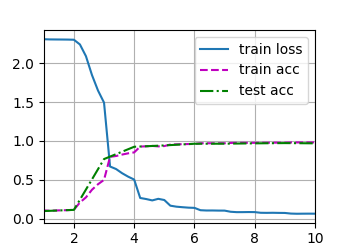
最终结果:Avg Pooling, epoch 10, lr 0.6: loss 0.064, train acc 0.981, test acc 0.970
Q4: 显示不同输入(例如毛衣和外套)时,LeNet第一层和第二层的激活值。
在train_ch6中的X, y = X.to(device), y.to(device)和 y_hat = net(X)之间,添加如下代码
x_first_Sigmoid_layer = net[0:2](X)[0:9, 1, :, :]
d2l.show_images(x_first_Sigmoid_layer.reshape(9, 28, 28).cpu().detach(), 1, 9)
x_second_Sigmoid_layer = net[0:5](X)[0:9, 1, :, :]
d2l.show_images(x_second_Sigmoid_layer.reshape(9, 10, 10).cpu().detach(), 1, 9)
# d2l.plt.show()
经Sigmoid1(上)和Sigmoid2(下)之后的图像分别如下: