在Animator类的add()方法的倒数第二行上面加上
plt.draw(),
plt.pause(0.001)
4 Likes
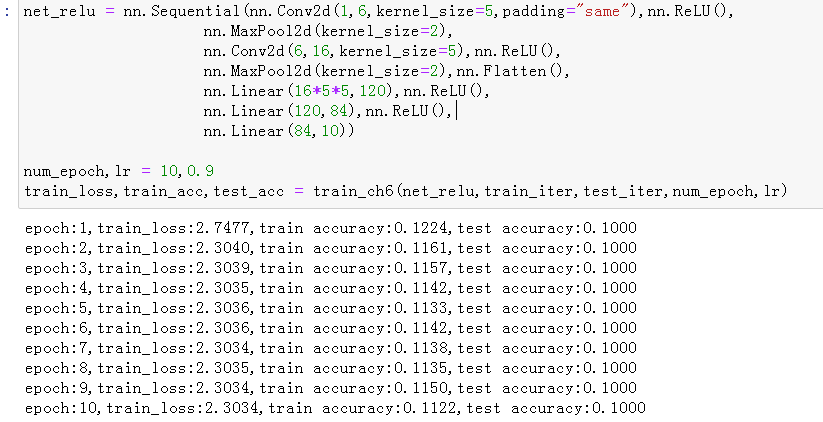
调节了卷积窗口的大小,每层输出的shape会发生变化,需要重新计算新的值
1 Like
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
这里在计算训练损失时,为什么不可以直接用l, 而是要l * X.shape[0]/X.shape[0]?
因为训练得到的l已经是平均值了。。。。。
1 Like
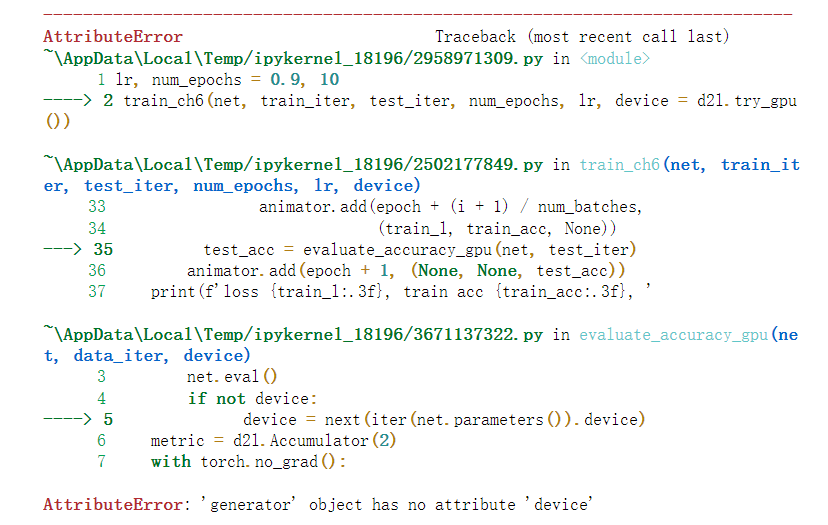
啊 没懂啊 为什么不能直接返回l 乘批量大小再除,不还是原来的损失吗?
请问一下大家,在GPU上跑的时候,但是CPU利用率还是很高,而GPU利用率只是间歇性地跑到60-70%。这是什么原因呢??
把lr调小就可以很快收敛,0.9这个学习率对于ReLU来说太大了。我觉得可能是因为ReLU在0的右邻域内的梯度比sigmoid大得多,所以适用于sigmoid的lr用在ReLU身上容易步子迈太大,走过头,反而不好收敛。
3 Likes
我也遇到同样的问题,请问你现在解决了吗?
使用Relu、maxpooling以及增加卷积核的数量,会有显著的提升。
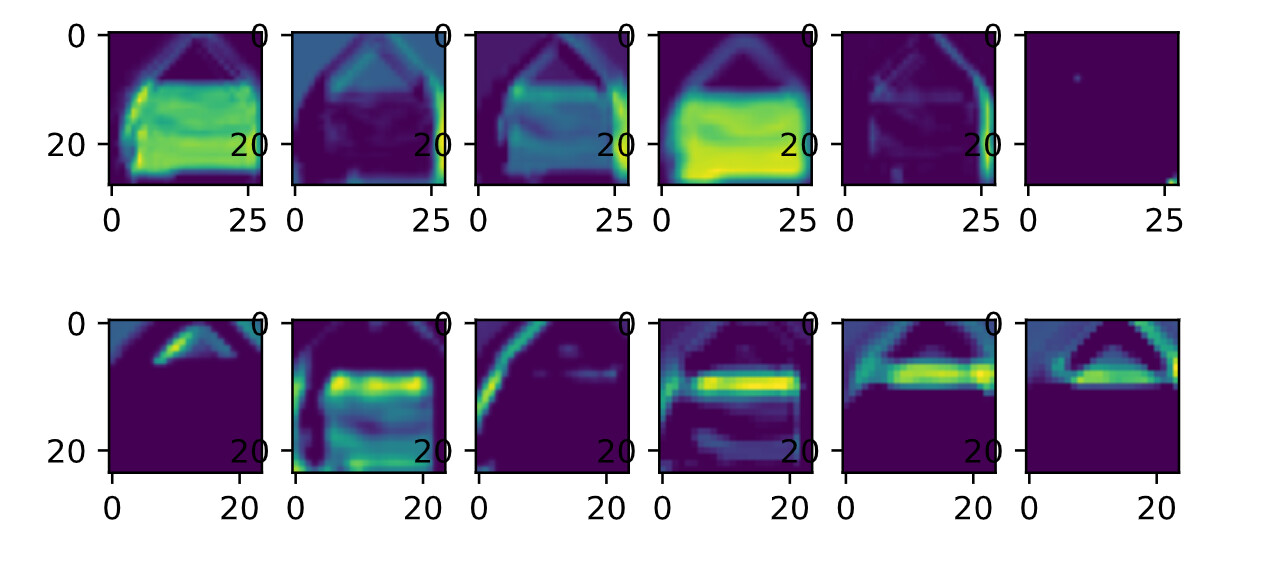
我这跑完要这么久,而且感觉看gpu利用率没有多高
loss0.464,train acc 0.825,test acc 0.808
76627.1 examples/sec on cuda:0

正如soree_yo所说的,你需要
在Animator类的add()方法的倒数第二行上面加上
plt.draw(),
plt.pause(0.001)
然后再train_ch6中,即最后一行添加plt.show()即可解决
In my experience, two linear layers, 20 epoch get the best performance. I can not explain, but I guess it fit
the data very well.
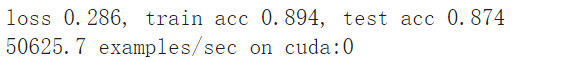
1 Like
需要对李沐老师的Animator类进行一定的修改才能在Pycharm比较好的运行。
我把代码贴在了CSDN上,需要自取:
其中主要修改的是Animator类,将我修改后的Animator类替换李沐老师的Animator类,并在构造的时候使用 animator = Animator(legend=[‘train loss’, ‘train acc’, ‘test acc’])
另外,在最后要显示的时候,调用 animator.show()即可。
Empty Traceback (most recent call last)
File D:\miniconda\envs\d2l\lib\site-packages\torch\utils\data\dataloader.py:1163, in _MultiProcessingDataLoaderIter._try_get_data(self, timeout)
1162 try:
→ 1163 data = self._data_queue.get(timeout=timeout)
1164 return (True, data)
File D:\miniconda\envs\d2l\lib\multiprocessing\queues.py:108, in Queue.get(self, block, timeout)
107 if not self._poll(timeout):
→ 108 raise Empty
109 elif not self._poll():
Empty:
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
Input In [6], in <cell line: 2>()
1 lr, num_epochs = 0.9, 10
----> 2 train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
Input In [5], in train_ch6(net, train_iter, test_iter, num_epochs, lr, device)
17 metric = d2l.Accumulator(3)
18 net.train()
—> 19 for i, (X, y) in enumerate(train_iter):
20 timer.start()
21 optimizer.zero_grad()
File D:\miniconda\envs\d2l\lib\site-packages\torch\utils\data\dataloader.py:681, in _BaseDataLoaderIter.next(self)
678 if self._sampler_iter is None:
679 # TODO(Bug in dataloader iterator found by mypy · Issue #76750 · pytorch/pytorch · GitHub)
680 self._reset() # type: ignore[call-arg]
→ 681 data = self._next_data()
682 self._num_yielded += 1
683 if self._dataset_kind == _DatasetKind.Iterable and
684 self._IterableDataset_len_called is not None and
685 self._num_yielded > self._IterableDataset_len_called:
File D:\miniconda\envs\d2l\lib\site-packages\torch\utils\data\dataloader.py:1359, in _MultiProcessingDataLoaderIter._next_data(self)
1356 return self._process_data(data)
1358 assert not self._shutdown and self._tasks_outstanding > 0
→ 1359 idx, data = self._get_data()
1360 self._tasks_outstanding -= 1
1361 if self._dataset_kind == _DatasetKind.Iterable:
1362 # Check for _IterableDatasetStopIteration
File D:\miniconda\envs\d2l\lib\site-packages\torch\utils\data\dataloader.py:1325, in _MultiProcessingDataLoaderIter._get_data(self)
1321 # In this case, self._data_queue is a queue.Queue,. But we don’t
1322 # need to call .task_done() because we don’t use .join().
1323 else:
1324 while True:
→ 1325 success, data = self._try_get_data()
1326 if success:
1327 return data
File D:\miniconda\envs\d2l\lib\site-packages\torch\utils\data\dataloader.py:1176, in _MultiProcessingDataLoaderIter._try_get_data(self, timeout)
1174 if len(failed_workers) > 0:
1175 pids_str = ', '.join(str(w.pid) for w in failed_workers)
→ 1176 raise RuntimeError(‘DataLoader worker (pid(s) {}) exited unexpectedly’.format(pids_str)) from e
1177 if isinstance(e, queue.Empty):
1178 return (False, None)
RuntimeError: DataLoader worker (pid(s) 15336, 3572) exited unexpectedly
为什么报错了呀
因为学习率太大了啦,lr换成0.1或者用Adam(后面的内容)会有一个显著的提升,学习率过大导致参数一直在目标附近来回震荡而落不下去。
3 Likes
excellent replies! I understand now