有人知道为什么过渡层用平均池化,但不用最大池化吗?
我自己换成了max pooling尝试了一下,发现accuracy没啥变化。
DenseNet121/169/201模型代码,参照DenseNet原文和torchvision源码实现,供参考
import re
import torch
import torchvision
import torch.utils.checkpoint as cp
from torch import nn, Tensor
from typing import List, Tuple
from collections import OrderedDict
from torchvision.models.utils import load_state_dict_from_url
class _DenseLayer(nn.Module):
def __init__(self, in_channels, growth_rate, bn_size,
dropout_rate, momery_efficient: bool):
super(_DenseLayer, self).__init__()
self.momery_efficient = momery_efficient
self.dropout_rate = dropout_rate
# 用于bottleneck前向计算, 标号2表示加载checkpoints的
self.norm1: nn.BatchNorm2d
self.relu1: nn.ReLU
self.conv1: nn.Conv2d
self.norm2: nn.BatchNorm2d
self.relu2: nn.ReLU
self.conv2: Conv2d
# 将bottleneck添加到网络中
self.add_module('norm1', nn.BatchNorm2d(in_channels))
self.add_module('relu1', nn.ReLU(inplace=True))
self.add_module('conv1', nn.Conv2d(in_channels, growth_rate * bn_size,
kernel_size=1, stride=1, bias=False))
self.add_module('norm2', nn.BatchNorm2d(growth_rate * bn_size))
self.add_module('relu2', nn.ReLU(inplace=True))
self.add_module('conv2', nn.Conv2d(growth_rate * bn_size, growth_rate,
kernel_size=3, stride=1, padding=1,
bias=False))
def bottleneck(self, inputs: List[Tensor]):
concated_features = torch.cat(inputs, 1)
bottleneck_ouputs = self.conv1(self.relu1(self.norm1(concated_features)))
return bottleneck_ouputs
@torch.jit.unused
def call_checkpoints_bottleneck(self, inputs: List[Tensor]):
def closure(*inputs):
return self.bottleneck(inputs)
return cp.checkpoint(closure, *inputs)
def forward(self, input: Tensor):
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.momery_efficient:
bottleneck_ouputs = self.call_checkpoints_bottleneck(prev_features)
else:
bottleneck_ouputs = self.bottleneck(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_ouputs)))
if self.dropout_rate > 0:
new_features = F.dropout(new_features, p=self.dropout_rate,
training=self.training)
return new_features
class _DenseBlock(nn.ModuleDict):
def __init__(self, num_layers, in_channels, growth_rate, bn_size,
dropout_rate, momery_efficient):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(in_channels + growth_rate * i, growth_rate,
bn_size, dropout_rate, momery_efficient)
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, x):
# 先把上个denseblock的输入放到一个列表,后面逐渐添加各denselayer输出
features = [x]
# self.items()访问以OrderedDict方式存在当前self._modules中的layers
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return features
class _Transition(nn.Module):#
def __init__(self, in_channels, out_channels):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(in_channels))
self.add_module('relu', nn.ReLU(inplace=True))
# 调整(增加)channels
self.add_module('conv', nn.Conv2d(in_channels, out_channels,
kernel_size=1, stride=1, bias=False))
# 减小feature-maps尺寸
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
def __init__(self, block_config: Tuple[int, int, int, int],
num_classes: int = 1000,
in_channels: int = 64,
growth_rate: int = 32,
bn_size: int = 4,
dropout_rate: float = 0.,
momery_efficient: bool = False):
super(DenseNet, self).__init__()
# 前面初始部分
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, in_channels, kernel_size=7, stride=2,
padding=3, bias=False)),
('norm0', nn.BatchNorm2d(in_channels)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
# 密集部分
num_features = in_channels
for i, num_layers in enumerate(block_config):
denseblock = _DenseBlock(num_layers, num_features, growth_rate,
bn_size, dropout_rate, momery_efficient)
self.features.add_module('denseblock%d' % (i + 1), denseblock)
num_features += growth_rate * num_layers
if i < len(block_config) - 1:
trans = _Transition(num_features, num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
# transition通道减半,更新
num_features = num_features // 2
# 结尾前batchnorm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
self.classifier = nn.Linear(num_features, num_classes)
# 初始化参数
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
out = self.features(x)
out = F.relu(out, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
class Constructor:
def __init__(self, num_classes: int = 1000,
momery_efficient: bool = False,
load: bool = False,
progress: bool = True):
self.num_classes = num_classes
self.momery_efficient = momery_efficient
self.load = load
self.progress = progress
self.model_urls = {
'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth',
'densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth',
'densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth',
}
def _load_state_dict(self, model: nn.Module, model_url: str):
state_dict = load_state_dict_from_url(model_url, progress=self.progress)
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
return model.load_state_dict(state_dict)
def _build_model(self, block_config, moder_url=None):
model = DenseNet(block_config=block_config,
num_classes=self.num_classes,
momery_efficient=self.momery_efficient)
if self.load:
model = self._load_state_dict(model, moder_url)
return model
def DenseNet121(self):
return self._build_model((6, 12, 24, 16), self.model_urls['densenet121'])
def DenseNet169(self):
return self._build_model((6, 12, 32, 32), self.model_urls['densenet169'])
def DenseNet201(self):
return self._build_model((6, 12, 48, 32), self.model_urls['densenet201'])
if __name__ == '__main__':
num_classes = 1000
momery_efficient = True
load = True
progress = True
densenet169 = Constructor(num_classes, momery_efficient, load,
progress).DenseNet169()
print(densenet169)个人感觉(基于神经网络的不可解释性):nn.AvgPool2d(kernel_size=2, stride=2)),这里池化窗口大小为2x2,所以平均池化和最大池化效果差不多。平均池化可以更多的提取到相邻像素的信息。
我觉得从平均池化和最大池化的特性来看,平均池化的特点是保留背景信息让每一个信息对最后的输出都有帮助,最大池化的特点是提取特征只保留特征最明显的信息,当我们费劲心力吧不同层的信息叠在了一起以后用最大池化等于前面都做了无用功。
-
主要原因在于过渡层中Pooling之前涉及维度压缩,为了更好完整地保留和传递信息因而采用了AvgPooling
-
教材中DenseNet于ResNet的卷积层层数及全连接层层数都是一样的,而网络的参数量也主要来自这两个部分。造成差距的主要原因在于卷积层和全连接层在通道数目上的差异。DenseNet通过过渡层不断控制通道数量,每个卷积的输入、输出通道数都没有超过256;反观ResNet,block3中5个卷积层输出通道均为256,block4中5个卷积层输出通道均为512,导致卷积层的参数量大幅增加;此外,在单层参数量最大的全连接层中,DenseNet输入通道数为248,远小于ResNet的512,因此在这一部分也获得了巨大的优势,最终使得DenseNet总体参数量比ResNet有了显著的下降
-
将输入大小同为96的情况下DenseNet的显存占用为 3161MiB / 4096MiB,ResNet为 2725MiB / 4096MiB,可见确实占用更大可以通过引入bottleneck结构来降低显存占用
在稠密块之间添加一个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
请问为什么减半通道数用的是 num_channels // 2 ?
是打错了还是别有用心?
这个是python的取整除法,没有写错。
这里可以注意下新版的torchvision api发生了变化,load_state_dict_from_url转移到了torch中
from torch.hub import load_state_dict_from_url
另:
-
_Transition类继承写错了,应该是继承nn.Sequential。还有一种不改继承的思路,即补上forward函数。 -
_DenseBlock类的forward方法中的return语句错了,应该返回一个Tensor而不是list,正确写法应该为return torch.cat(features, 1)。
这里附上修改后可以正常运行的版本,测试用的fashion net,在输入通道做了些修改
import re
from matplotlib.pyplot import isinteractive
import torch
import torchvision
from torch import nn
import torch.utils.checkpoint as cp
from typing import List, Tuple
from collections import OrderedDict
from torch.hub import load_state_dict_from_url
class _DenseLayer(nn.Module):
def __init__(self, in_channels, growth_rate, bn_size, dropout_rate, memory_efficient: bool):
super().__init__()
self.memory_efficient = memory_efficient
self.dropout_rate = dropout_rate
# 用于bottleneck的forward计算,标号2表示加载checkpoints
# 这里用先标识了每个层的类型
self.norm1: nn.BatchNorm2d
self.relu1: nn.ReLU
self.conv1: nn.Conv2d
self.norm2: nn.BatchNorm2d
self.relu2: nn.ReLU
self.conv2: nn.Conv2d
self.drop: nn.Dropout2d
# 添加bottleneck到网络中
self.add_module('norm1', nn.BatchNorm2d(in_channels))
self.add_module('relu1', nn.ReLU(inplace=True))
self.add_module('conv1', nn.Conv2d(
in_channels, bn_size * growth_rate, kernel_size=1, stride=1, bias=False))
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate))
self.add_module('relu2', nn.ReLU(inplace=True))
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate,
growth_rate, kernel_size=3, stride=1, padding=1, bias=False))
if self.dropout_rate > 0:
self.add_module('drop', nn.Dropout2d(self.dropout_rate))
def bottleneck(self, input: List[torch.Tensor]):
concated_features = torch.cat(input, dim=1)
bottle_neck_outputs = self.conv1(
self.relu1(self.norm1(concated_features)))
return bottle_neck_outputs
@torch.jit.unused
def call_checkpoints_bottleneck(self, input: List[torch.Tensor]):
def closure(*inputs):
return self.bottleneck(inputs)
return cp.checkpoint(closure, *input)
def forward(self, input: torch.Tensor):
# 若输入不是list,则转换为list
if isinstance(input, torch.Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient:
bottleneck_output = self.call_checkpoints_bottleneck(prev_features)
else:
bottleneck_output = self.bottleneck(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.dropout_rate > 0:
new_features = self.drop(new_features)
return new_features
class _DenseBlock(nn.ModuleDict):
'''
stacked dense layers to form a dense block
'''
def __init__(self, num_layers, in_channels, growth_rate, bn_size, dropout_rate, memory_efficient) -> None:
super().__init__()
for i in range(num_layers):
layer = _DenseLayer(in_channels + growth_rate * i,
growth_rate, bn_size, dropout_rate, memory_efficient)
# 层的标识下标是从1开始,计算size时使用0开始会更方便
self.add_module(f'denselayer {i+1}', layer)
def forward(self, x: torch.Tensor):
# 先将上个denseblock放入一个列表,然后逐渐添加各denselayer的输出
# features 会在每个denselayer中的bottlelayer进行concat,然后再进行计算
# 这样通过denselayer中的checkpoints模块函数进行管理,可以实现memory efficient
features = [x]
# self.items()以OrderDict的方式访问self._modules中的layers
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class _Transition(nn.Module):
'''
transition layer
'''
def __init__(self, in_channels, out_channels):
super().__init__()
self.add_module('norm', nn.BatchNorm2d(in_channels))
self.add_module('relu', nn.ReLU(inplace=True))
# 调整channels
self.add_module('conv', nn.Conv2d(
in_channels, out_channels, kernel_size=1, stride=1, bias=False))
# 调整feature map的大小
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
def forward(self, x: torch.Tensor):
out = self.norm(x)
out = self.relu(out)
out = self.conv(out)
out = self.pool(out)
return out
class Densenet(nn.Module):
def __init__(self, block_config: Tuple[int, int, int, int],
num_classes: int = 1000,
in_channels: int = 64,
growth_rate: int = 32,
bn_size: int = 4,
dropout_rate: float = 0,
memory_efficient: bool = False):
super().__init__()
# stage 1: initial convolution
# 适应fashion mnist,改为单通道
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(1, in_channels,
kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', nn.BatchNorm2d(in_channels)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
# stage 2: dense blocks
num_features = in_channels
for i, num_layers in enumerate(block_config):
denseblock = _DenseBlock(
num_layers, num_features, growth_rate, bn_size, dropout_rate, memory_efficient)
self.features.add_module(f'denseblock {i+1}', denseblock)
num_features += num_layers * growth_rate
# 判断是否到了最后一层,如果是最后一层,这里应该接分类层,而不是transition layer
if i != len(block_config) - 1:
# 这里设置通道数目直接减半,feature map H W同时减半
trans = _Transition(num_features, num_features // 2)
self.features.add_module(f'transition {i+1}', trans)
num_features = num_features // 2
# 结尾前的batchnorm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
self.features.add_module('relu5', nn.ReLU(inplace=True))
self.features.add_module('adaptive_pool', nn.AdaptiveAvgPool2d((1, 1)))
self.features.add_module('flat', nn.Flatten())
self.classifier = nn.Linear(num_features, num_classes)
# 初始化参数
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
out = self.features(x)
out = self.classifier(out)
return out
class Constructor:
def __init__(self, num_classes: int = 1000,
memory_efficient: bool = False,
load: bool = False,
progress: bool = True):
self.num_classes = num_classes
self.memory_efficient = memory_efficient
self.load = load
self.progress = progress
# 并不能直接用这些官方模型参数,因为模型上有些细节和官方不一样
# 这里只为了了解官方加载的代码方式而写
self.model_urls = {
'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth',
'densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth',
'densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth',
}
def _load_state_dict(self, model: nn.Module, model_url: str):
state_dict = load_state_dict_from_url(
model_url, progress=self.progress)
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
return model.load_state_dict(state_dict)
def _build_model(self, block_config, model_url=None):
model = Densenet(block_config, self.num_classes,
memory_efficient=self.memory_efficient)
if self.load:
if model_url is None:
model_url = self.model_urls['densenet121']
self._load_state_dict(model, model_url)
return model
def densenet121(self):
return self._build_model((6, 12, 24, 16), self.model_urls['densenet121'])
def densenet169(self):
return self._build_model((6, 12, 32, 32), self.model_urls['densenet169'])
def densenet201(self):
return self._build_model((6, 12, 48, 32), self.model_urls['densenet201'])
from torchinfo import summary
from d2l import torch as d2l
num_classes = 10
memory_efficient = True
load = False
progress = True
densenet121 = Constructor(num_classes, memory_efficient, load,
progress).densenet169().to('cpu')
summary(densenet121, input_size=(256, 3, 224, 224), device='cpu')
# X = torch.randn(1, 1, 224, 224).to('cpu')
# print(densenet121(X).shape)
从功能的角度进行事后解释还是有点没有说服力,因为从另一方面讲,如果作者用的是MaxPool,我们又可以说:最大池化能够选取相邻像素中最具代表性的信息。
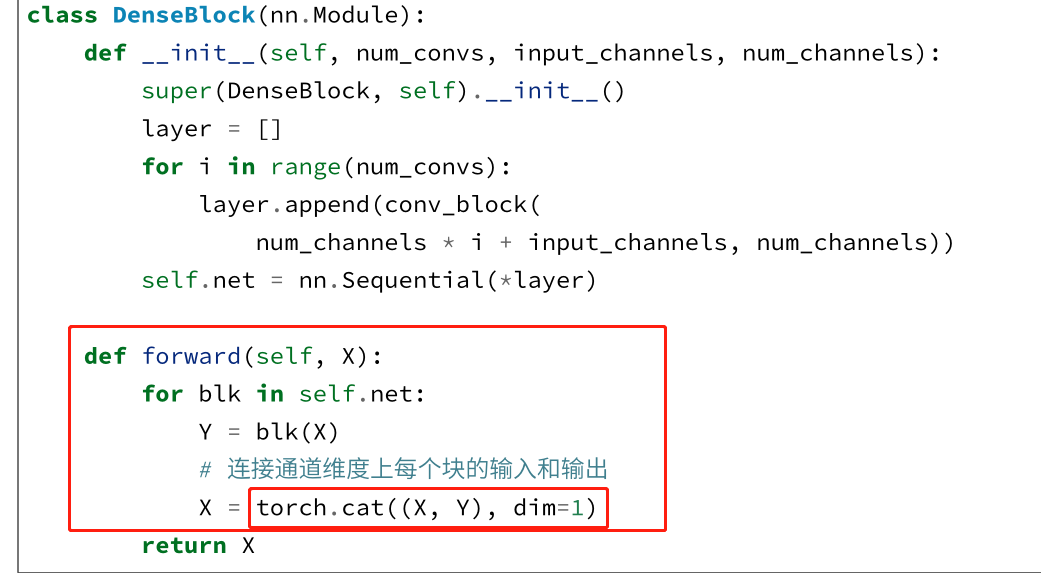
这里的循环每次都在X上继续叠加输出的Y,X保存了前面所有层的输出信息
没错的,就是要让通道数增加,产生的结果合并在第1维
这里理解错了,我以为每个denseblock里面每个conv_block的卷积输出通道不一样,其实是一样的;只是每个conv_block的输入通道不一样,是之前卷积通道数的叠加
我也用了一下最大池化,测试精度几乎差别不大,但训练进度平局池化收敛于1要快些
因为num_channels必须保证为一个整数,但是除二操作的结果可能不是一个整数,因此用整除更保险一些
回答一下最后一题。
导入数据集和数据清洗的工作以及最后模型训练都是跟书本的一样。大致就改了一下模型
本人新手,第一次写回答不知道对不对,还请大佬指教
以下是模型的代码
稠密块体
def conv_block_mlp(input_channels,num_channels):
return nn.Sequential(
nn.BatchNorm1d(input_channels),nn.ReLU(),
nn.Linear(input_channels,num_channels)
)
稠密层
class DenseBlock_mlp(nn.Module):
def __init__(self,num_convs,input_channels,num_channels) -> None:
super().__init__()
layer=[]
for i in range(num_convs):
layer.append(conv_block_mlp(
num_channels*i+input_channels,num_channels
))
self.net=nn.Sequential(*layer)
def forward(self,X):
for blk in self.net:
Y=blk(X)
X=torch.cat((X,Y),dim=1)
return X
过渡层
def transition_block_mlp(input_channels,num_channels):
return nn.Sequential(nn.BatchNorm1d(input_channels),nn.ReLU(),
nn.Linear(input_channels,num_channels),nn.ReLU()
)
模型搭建
b1=nn.Sequential(
nn.Linear(330,512),nn.ReLU(),
nn.Linear(512,1024),nn.ReLU()
)
#b2
#num_channels为当前的通道数
num_channels,growth_rate=1024,128
num_convs_in_dense_blocks=[2,2,2,2]
blks=[]
for i,num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock_mlp(num_convs,num_channels,growth_rate))
# 上一个稠密块的输出通道数
num_channels+=num_convs*growth_rate
# 在稠密块之间添加转换层,使通道数减半
if i != len(num_convs_in_dense_blocks)-1:
blks.append(transition_block_mlp(num_channels,num_channels//2))
num_channels=num_channels//2
net_ = nn.Sequential(
b1, *blks,
nn.BatchNorm1d(num_channels), nn.ReLU(),
nn.Linear(608, 1))
k, num_epochs, lr, weight_decay, batch_size = 5, 10, 0.05, 0, 64
训练出来的结果
折1,训练log rmse0.038386, 验证log rmse0.060085
折2,训练log rmse0.045482, 验证log rmse0.048093
折3,训练log rmse0.042030, 验证log rmse0.051787
折4,训练log rmse0.042017, 验证log rmse0.064240
折5,训练log rmse0.040498, 验证log rmse0.043604
5-折验证: 平均训练log rmse: 0.041683, 平均验证log rmse: 0.053562
模型参数乱写的,log rmse比原本的0.16要低一点,可以说结果好一点,但不知道这是本身模型过于强大,还是我恰好找到了一组不错的参数?
model, optimizer, dataset, resize = densenet121, adam, fashion_mnist, 96
lr, num_epochs, batch_size = 0.001, 10, 64
epoch 9, loss 0.119, train acc 0.956, test acc 0.931