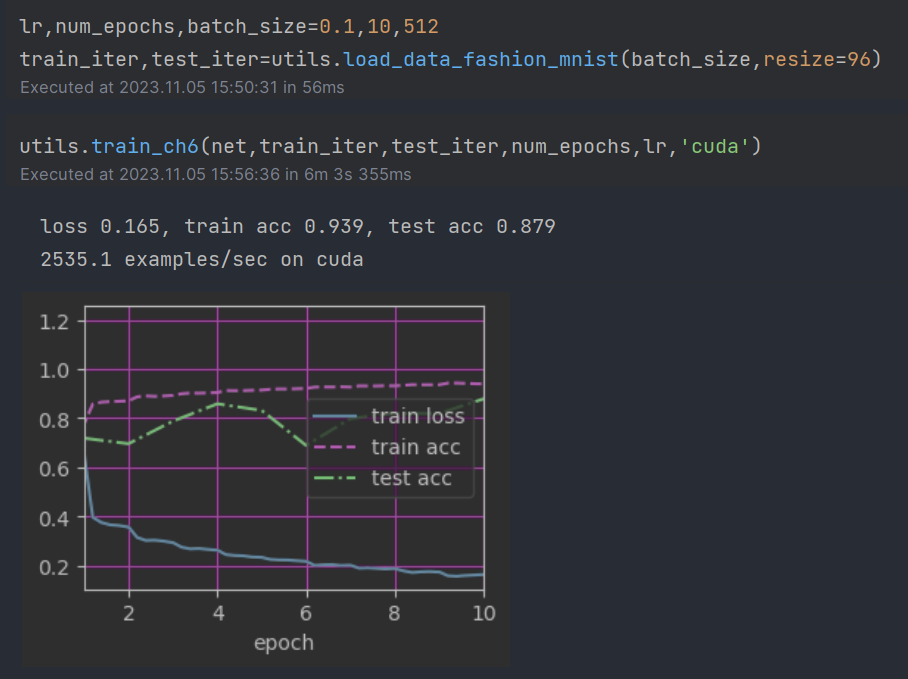
我遇到了一个问题,就是我仅仅将batch_size从256变成了512,test_acc却出现了剧烈的动荡,其中第一次训练的test_acc也只有0.82,远低于书中的结果,请问这是什么原理呀,我以为batch_size仅仅影响一次读入的数量,不影响最后的精度
我觉得应该从平均汇聚层和最大汇聚层的作用上来理解,汇聚层的作用是减少卷积层对网络结构的过度敏感,最大汇聚层只选择当前影响最大的元素,而平均汇聚层吸收了局部范围内的所有的元素特征。而过渡层的作用是减少通道数量,但是在减少的过程中应该要考虑所有通道学到的东西,因此这样看来平均汇聚层更合适些。
3.1试不了一点,简单把resize的值改成224,直接把我8g显存干爆了 ![]()
你好,2、3题的答案是否矛盾?如果不是,是什么原因导致DenseNet参数量小但占用更大呢?
尽管 DenseNet 通过特征复用减少了参数数量,但由于特征图拼接导致通道数累积、反向传播需要保存所有中间特征图以及拼接操作增加计算复杂度,导致其显存或内存消耗较高。因此,DenseNet 在内存使用方面比 ResNet 更为昂贵,特别是在处理高分辨率输入时显得尤为明显。
欢迎参观:
Submit My Work
import torch
import torch.nn as nn
import torch.nn.functional as F
class Bottleneck(nn.Module):
def __init__(self, in_channels, growth_rate):
super().__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv1 = nn.Conv2d(in_channels, 4 * growth_rate, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(4 * growth_rate)
self.conv2 = nn.Conv2d(4 * growth_rate, growth_rate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat([out, x], 1)
return out
class Transition(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.bn = nn.BatchNorm2d(in_channels)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.pool = nn.AvgPool2d(2, stride=2)
def forward(self, x):
out = self.conv(F.relu(self.bn(x)))
out = self.pool(out)
return out
class DenseNet(nn.Module):
def __init__(self, block_config, growth_rate=32, num_classes=1000):
super().__init__()
self.features = nn.Sequential()
# Initial convolution
self.features.add_module('init_conv', nn.Conv2d(3, 2 * growth_rate,
kernel_size=7, stride=2, padding=3, bias=False))
self.features.add_module('init_norm', nn.BatchNorm2d(2 * growth_rate))
self.features.add_module('init_relu', nn.ReLU(inplace=True))
self.features.add_module('init_pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# Build dense blocks
num_channels = 2 * growth_rate
for i, num_layers in enumerate(block_config):
block = nn.Sequential()
for j in range(num_layers):
layer = Bottleneck(num_channels + j * growth_rate, growth_rate)
block.add_module(f'dense_{i}_layer_{j}', layer)
num_channels += num_layers * growth_rate
self.features.add_module(f'dense_block_{i}', block)
if i != len(block_config) - 1: # Add transition except last block
trans = Transition(num_channels, num_channels // 2)
self.features.add_module(f'transition_{i}', trans)
num_channels = num_channels // 2
# Final layers
self.final_bn = nn.BatchNorm2d(num_channels)
self.classifier = nn.Linear(num_channels, num_classes)
# Weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(self.final_bn(features))
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def densenet121(**kwargs):
return DenseNet(block_config=[6, 12, 24, 16], growth_rate=32, ** kwargs)
def densenet161(**kwargs):
return DenseNet(block_config=[6, 12, 36, 24], growth_rate=48, ** kwargs)
def densenet169(**kwargs):
return DenseNet(block_config=[6, 12, 32, 32], growth_rate=32, ** kwargs)
def densenet201(**kwargs):
return DenseNet(block_config=[6, 12, 48, 32], growth_rate=32, ** kwargs)
我试了一下,平均池化比最大池化有0.01的精度提升,精度从0.90提升到0.91了
话说第5题,要应用densenet的设计思想到多层感知机上,densenet是将相加的结果改成类似列表的分开,多层感知机有类似的全连接相加的结构,难道是从这里下手吗?
能不能直接将densenet应用到房价预测上?