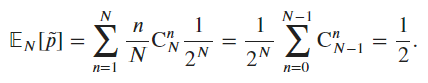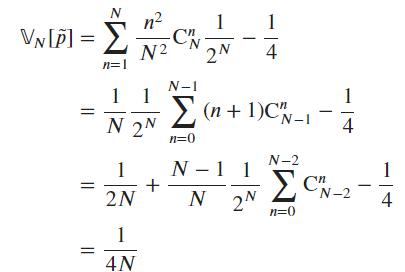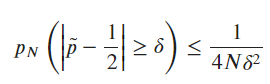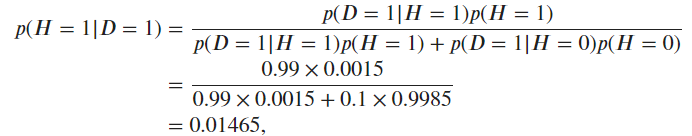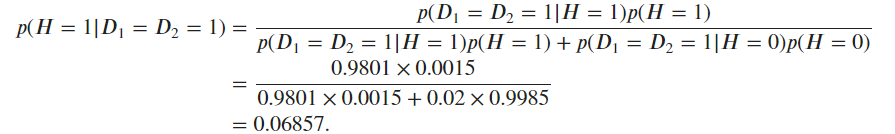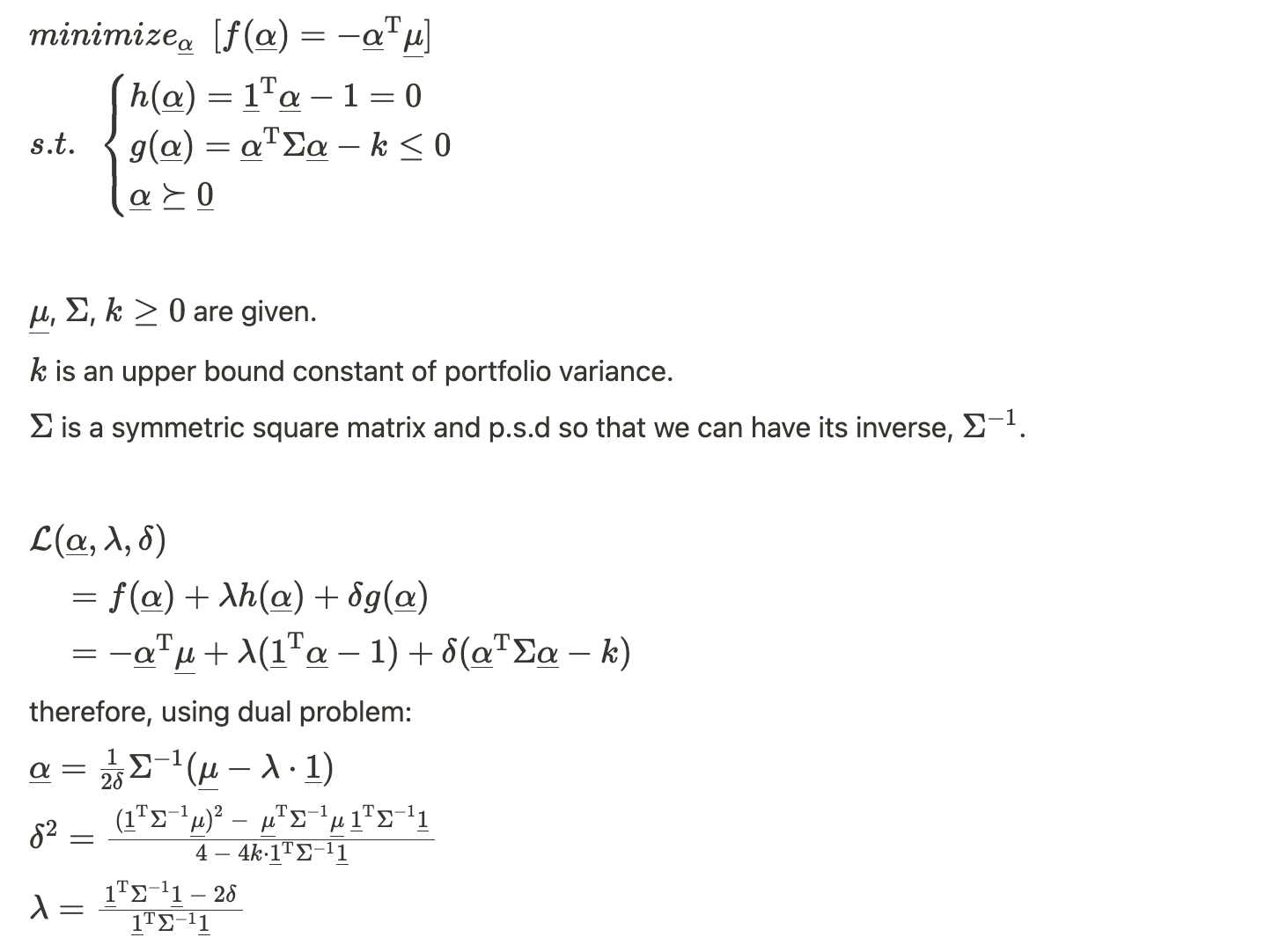You can import Multinomial directly from torch.distributions. ie. from torch.distributions import Multinomial
distribution.sample() takes a sample_size argument. So instead of sampling from numpy and converting into pytorch you can simply say Multinomial(10, fair_probs).sample((3,)) (sample_shape needs to be tuple).
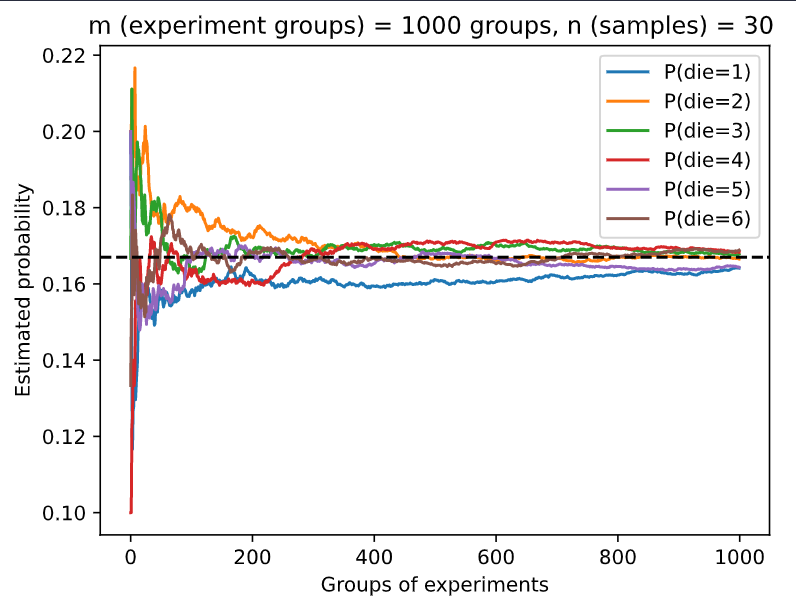
Wonder anyone has encountered the same problem as me related to the code above. In version 0.7 of Dive into Deep Learning, the code works as shown above, with all the probabilities converging to the expected value of 1/6. However, with code in version 0.8.0 of the same book, the curves (see the image on the right) do not look right. Both curves were obtained by running the code from the book(s) without any changes and ran on the same PC. So there might be bugs in version 0.8.0 of the book? Thanks!
Maybe it is just a coincidence that almost 90 groups of experiments is “die = 6”?
It would be more clear if you counts / 1000 # Relative frequency as the estimate.
For Q4:
If we do the test 1 twice, the two tests won’t be independent, since they are using the same method on the same patient. In fact, we will get the same result very possibly.
Is this equivalent to (since D1 and D2 are independent) P(D1=1,D2=1) = P(D1=1) * P(D2=1) ? P(D1=1) has been calculated in equation 2.6.3 and P(D2=1) can be calculated similarly.
I am having a hard time proving this. Am I missing something?
For the last question
If we assume the test result is deterministic, then
P(D2=1|D1=1) = 1
P(D2=0|D1=0) = 1
Doing first experiment twice does not add additional information. Therefore, P(H=1|D1=1,D2=1) == P(H=1|D1=1). You can derive the equation by doing some arithmetic.
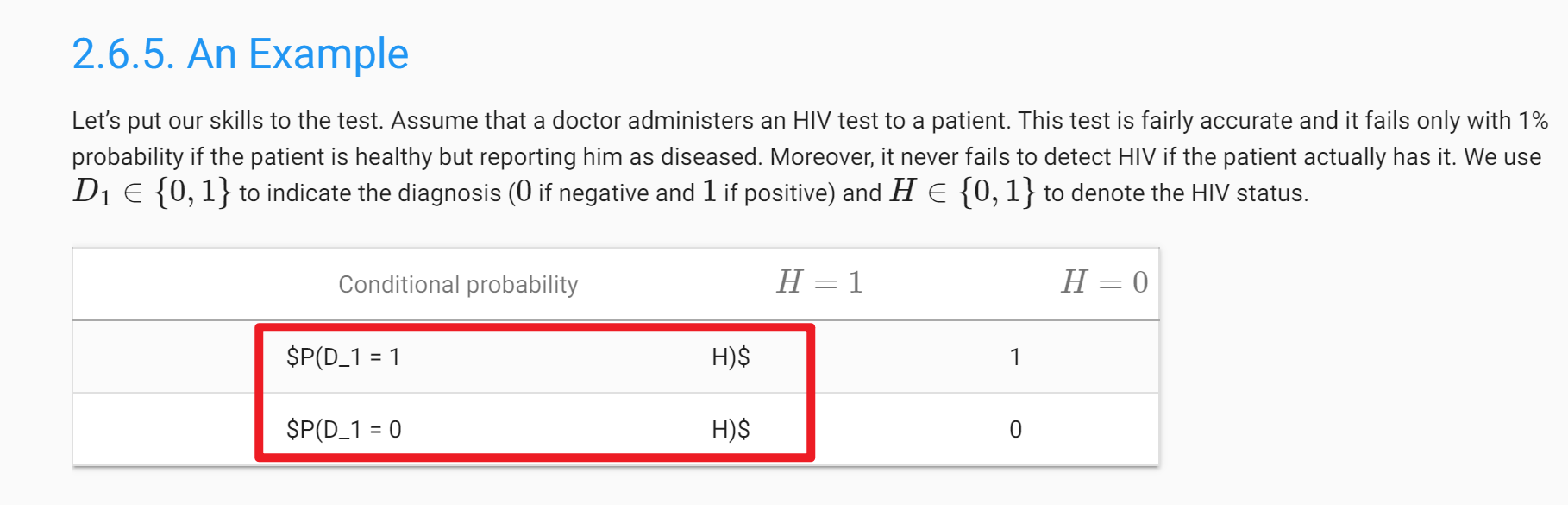
I don’t understand equation 2.6.3 . On the right side, why wouldn’t P(A) on the top cancel out with P(A) on the bottom, and since the other term on the bottom right which is the sum of all b in B for P(B|A) equals 1, wouldn’t that mean it would then just simplify to P(A|B) = P(B|A) which is obviously incorrect?
Yes, the equation is slightly wrong. The updated equation should sum over all possible ‘a’ values in the sample space(a and its complement so that it gets normalized accurately), Reference
Would have been great and more clear to actually see what numbers you multiplied in the example, for someone never doing stats before, it can be hard to comprehend all the formulas without any explanations.
The same answer. Quite conterintuitive, though. I think it is because the joint FPR 0.02 increased a lot compared to the original example 0.0003. So the positive result can still be confusing to patients.
As a note for the authors, the citation of Revels et. al 2016 in 2.6.7 looks wrong. Maybe this was supposed to be Kaplan et al. 2020, or Hoffmann et al. 2022.
Any entirely deterministic process - for example, determining the weight in kilograms of an arbitrary quantity of lithium.
Any process with stochastic components - for example, predicting tomorrow’s stock prices. One can get to a certain point of accuracy if they closely follow news events and filings, and get good at modeling, but there’s always uncertainty as to the exact decisions others will make. One might argue against such processes existing on fatalist grounds!
The variance is equal to p*(1-p) / n. This means the variance scales with 1/n, where n is the number of observations. Using Chebyshev’s inequality, we can bound \hat{p} with P\left(|\hat p - p| \ge k \cdot \sqrt{\frac{p(1-p)}{n}}\right) \le \frac{1}{k^2} (with p=0.5 in our case, assuming the coin is fair). Chebyshev’s inequality gives us a distribution-free bound, but as n grows (typically for n > 30), the central limit theorem tells us that \hat p \approx \mathcal{N} \left(p, \frac{p(1-p)}{n}\right)
I’m not sure if I’m interpreting the phrase “compute the averages” correctly, but I wrote the following snippet:
l = 100
np.random.randn(l).cumsum() / np.arange(1, l+1)
As for the second part of the question - Chebyshev’s inequality always holds for a single random variable with a finite variance. You can apply Chebyshev’s inequality to a specific z_m, but you cannot apply it for each z_mindependently. This is because the z_ms are not i.i.d. - they share most of the same underlying terms!
5. For P(A \cup B), the lower bound is max(P(A), P(B)), and the upper bound is max(1, P(A) + P(B)). For P(A \cap B), the lower bound is max(0, P(A)+P(B)-1) (remember that P(A)+P(B) can be larger than 1) and the upper bound is min(P(A), P(B))
6. One could factor the joint probability P(A, B, C) as P(C|B) * P(B|A) * P(A), but this isn’t simpler. I’m not sure what exactly this question is looking for.
7. We know that the false positive rate for each test must add up to 0.1, and that the joint probabilities must add up to 1. So the mixed probabilities are 0.08, and P(D_1=0, D_2=0 | H=0) = 0.82. For 7.2, I obtained 1.47%. For 7.3, I obtained 6.86%.
8. The expected return for a given portfolio \boldsymbol \alpha are \boldsymbol \alpha^\top \boldsymbol \mu. To maximize the expected returns of the portfolio, one should find the largest entry in \mu_i and invest the entire portfolio into it - \boldsymbol \alpha should have a single non-zero entry at the corresponding index. The variance of the portfolio is \boldsymbol \alpha^\top \Sigma \boldsymbol \alpha. So the optimization problem described can be formalized as: maximize \boldsymbol \alpha^\top \boldsymbol \mu for some maximum variance \boldsymbol \alpha^\top \Sigma \boldsymbol \alpha, where \sum_{i=1}^n \alpha_i = 1 and \alpha_i \ge 0.