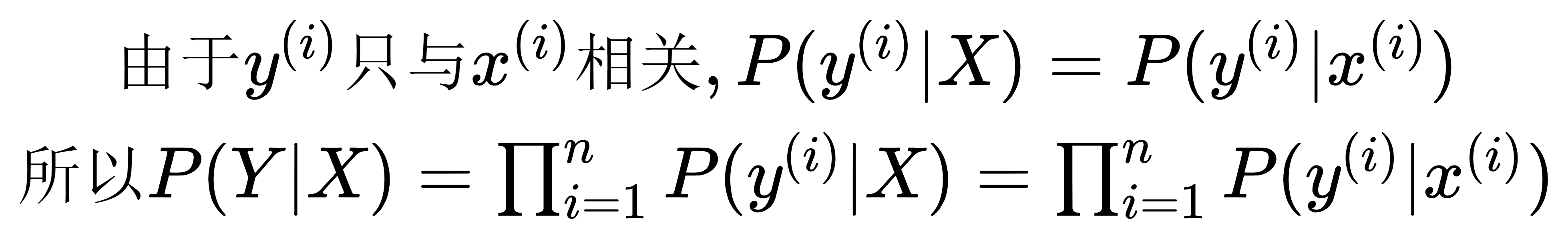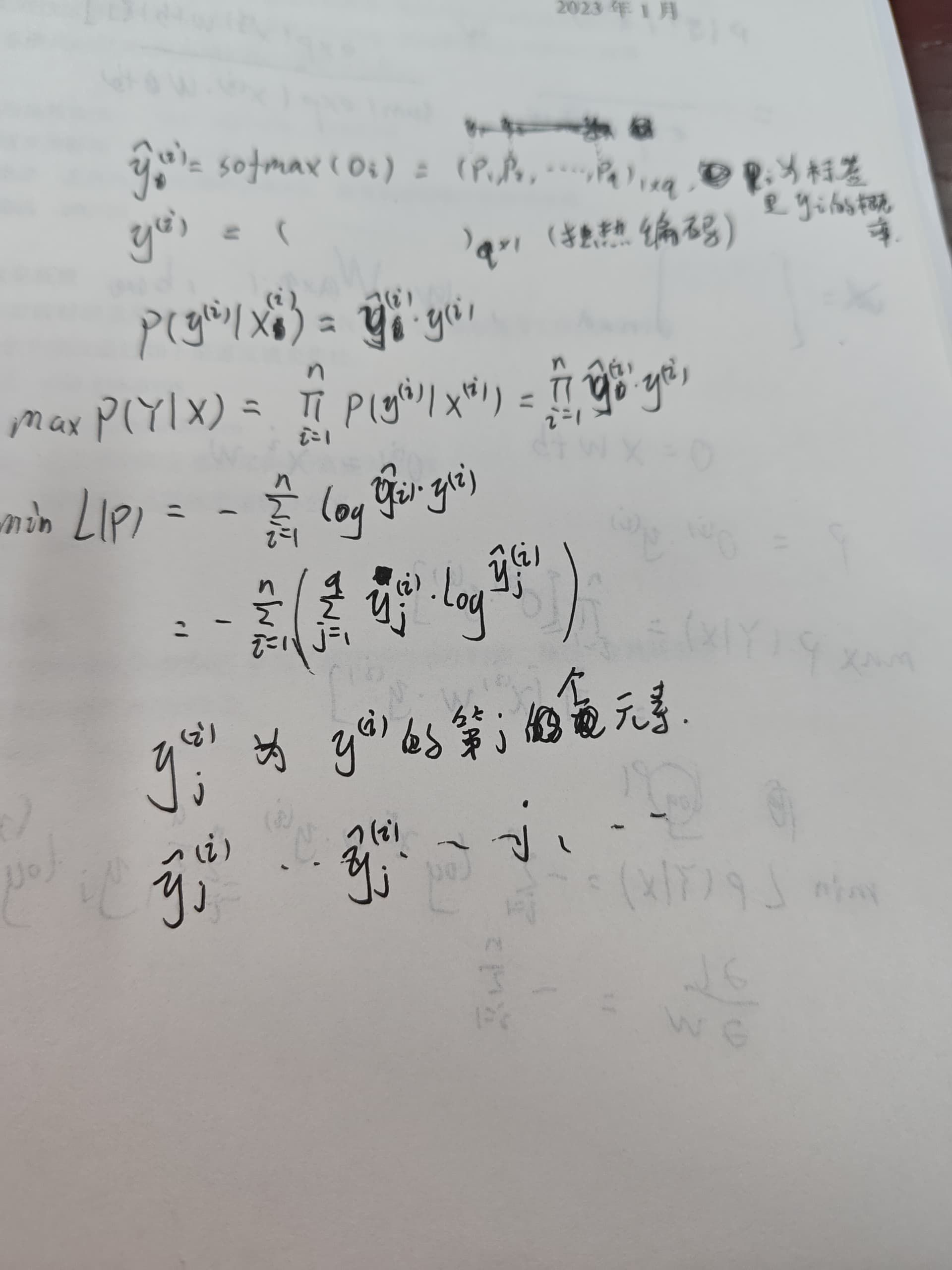zppet
对比着第一版,阅读了本节,总觉得读起来很“卡”,不如第一版来的自然而易于理解(不仅是文字翻译上的“卡”,整个行文逻辑也不如第一版)。
第一版(3.4. softmax回归)读起来像中国话,第二版看起来像是由英语翻译过来的,特别别扭。
不知道是不是我自己阅读理解的水平问题。 
对比着第一版,阅读了本节,总觉得读起来很“卡”,不如第一版来的自然而易于理解(不仅是文字翻译上的“卡”,整个行文逻辑也不如第一版)。
第一版(3.4. softmax回归)读起来像中国话,第二版看起来像是由英语翻译过来的,特别别扭。
不知道是不是我自己阅读理解的水平问题。

Thanks @zppet for your feedback, 由于时间限制,这一版有点仓促。 如果哪些语句可以改进,请发 PR 做 d2l 的 contributor!
3 replies



喔,这个对熵和交叉熵的形容,有点过于妙了
关于本节中的式(3.4.6)和式(3.4.7)中的数学符号P改成符号L是否更好?因为我相信这里应该强调的是似然\可能性(likelihood)而不是概率(probability),既然我们这里讨论的是最大似然估计。
3.4.6等式两边同时取log啊,乘法就变加法了

Y是独热向量,无论是哪一个Yj,只有Yj=1,其他都是0, 所以最后总和是1

第一个yj 是真实y的独热编码的第j位 不是0 就是1

老实说,感觉是机器翻译一样。。。
读起来非常生涩,估计是我水平不够= =




报告一个错误,然而“我们”

3.4.6中的公式log不写底数看起来好奇怪,感觉应该写ln,后面求导直接用的ln

大佬,能看看你的过程吗,我不会做哈哈……

对咱俩的答案一样,没问题?这个还有20的限制吗

3.4.7建议解释下,看的一脸懵逼,下面的回复解释的也不太清晰

这一节分类标签,(鸡,猫,狗),上下文不一致。

请问“课后联系”的代码在哪里可以下载?或者文档也可以


这部分不少人读不懂,感觉不是很通透,希望解答下

@richard001 @shayneliu @aaronshi2017

@goldpiggy 顺便一提,我能把这个插入到源文件中吗?我觉得目前的解释有点过于精炼了……
5 replies

应该在github的界面上发,这里是没有的

我尝试做了一下第一题和第三题,也不知道对不对,我把这一章其它题目自己做的过程放在我的知乎里了《动手学深度学习》第三章,本人水平有限,做题过程也许有错,但是希望对大家有些许帮助~


###########################################################################
3.4.9公式的第二行到第三行中,为什么yj的求和在第一项中去掉了,在第二项中保存下来了?????
2 replies
第一项后面是k,所以可以直接加了,加起来是1,所以省略

能否用神经网络去拟合pytorch中内置的损失函数BCELOSS,如果能网络结构应该是怎么样的》?
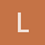


3.4.7到3.4.8的推导:输入[x1, x2, …, xd]到网络中得到输出[y’1, y’2, …, y’q],注意这里的每个输出y^i都是已经使用softmax归一化的概率。这时我们样本的标签对应为[0, 0, …, 1, …],就假设第i类为1好了,即yi=1,那么这时 p(y=i | X) = y’i。那么我们如何写成一个一般化的式子表示p(y=i | X)的概率呢?不妨这样表示 p(y = i | X) = (y’1 * y1) * (y’2 * y2) * … (y’i * yi) …(y’q * yq)。这样的话我们就可以得出极大似然估计的表达式了,即3.4.7 和 3.4.8。(‾◡◝)

AttributeError: module ‘torch’ has no attribute ‘synthetic_data’
AttributeError: module ‘torch’ has no attribute ‘set_figsize’
我在运行代码时出现这样报错有大佬可以帮我解析一下吗?抱歉我是个编程小白

楼上很多对3.4.7怎么推到3.4.8的讨论,我个人一开始没理解用极大似然怎么推出这个条件概率值的表达式,但是看了一下@zxhd863943427的推导也理解了:
极大似然是通过改变模型的参数θ,使得观测的事件发生的概率最大,这里θ就是估计的y的概率分布,所以要改变y的分布的值(特指yj情况下的y*)来使得发生事件(指这里的一个个样本,相互对立假设下概率值直接相乘)的概率最大,上述概率都是指给定x下的条件概率。
我就补充这个理解吧,具体计算再去看@zxhd863943427写的回答应该能看得更懂一些。(有错请指正我,概统已经是一年前学的了)

关于线性层和非线性层,不知道我理解的对不对,请大家批评指正。
这个模型包含了一个全连接层(线性)和一个softmax层(非线性)。
深度学习中只有线性层的情况下是无法作用于复杂问题的,而有了softmax层作为非线性层,就可以不加relu或者sigmoid层,也可以跑出正确的结果。


我的理解是,P(y’i | x’i) 描述的是一个概率,它的结果是一个标量而不是向量,所以 log P(y’i | x’i) 与 y_hat 'i 之前是无法划等号的。
根据 3.4.1 中的内容可知,每种类别对应的独热编码是唯一的,即第 n 个分量为 1 的 y 只有一个。或者说,独热向量 y 描述的是一个事件A,若 y 的第 n 个分量为 1 ,则事件 A 表示输入的 x 为第 n 类。
所以,假设 向量 y’i 的第 n 个分量为 1 ,它的概率应该为 P(y’i | x’i) = P(y_n | x) = y_hat_n
希望对你有帮助

我也有这个感觉,为什么第一版读起来很流畅

同样的疑惑,看到这块内容,感觉这里的公式表述不是很严谨,容易让人理解成一个向量。

我推出来也是这个答案,看起来大家应该都差不多

兄弟写的很详细,我想的是如果把你第一题第二问中的o换成y会不会简洁一些,而且题干中要求使用二阶导数表示。还有第一题第一问,为什么前面对oj求二次导,后面又对oi求导了?没看明白

我恰恰认为用惊讶很好啊,非常通俗易懂啊。。。

想问一下,为什么要对 O_i 求导呢?有什么意义



应该是因为链式法则的缘故。求梯度最终是要对参数求导的,但是对参数求导的过程中必定要经历损失函数对o_j求导,然后o_j再对参数求导的过程。
因为q维向量y是一个单位向量,所以y的元素y_j的取值要么是0要么是1且只有一个1,所以y_j的求和是1
3.4.8这个跳跃我觉得挺逆天的, 生怕别人看得懂还是咋地

确实 我都得对着英文原版看,翻译水平真的好差,

我还以为只有我看得蛋疼原来大家都蛋疼 ![]()
中文版文字表达前面看得还好,现在越看越像机翻
内容总有莫名其妙的跳脱,对基本功和推理能力要求太高,有时看着看着得停下来消化半天

从新看了一下第一版这一章节,第二版确实没有第一版清晰

这样的公式推导应该是个特例,本质上应该是单个样本的信息量等于交叉熵

滥用n,看得一头雾水,滥用n,看得一头雾水


的确,第一版读的顺畅,内容过度也更自然。
关于3.4.7,在3.4.6中,因为概率向量是一个(0,1,0)的向量,因此发生y_j的概率P就是标签乘以预测值即y_i×y_hat,比如类别2,预测(0.1,0.2,0.7),那么准确预测的概率就是1×0.2,带入3.4.7的中间部分就可以得到信息熵公式

感觉这一小节的顺序有点凌乱,从3.4.7到3.4.8那一步转变很生涩。
通读下来,其实应当是先要介绍信息熵的概念,然后再来介绍 softmax 的损失函数,这样的顺序会更加让人读懂一些。当然,如果能顺带着讲一下 KL散度 的定义(其实信息熵那一小节已经简单介绍了这个概念),让后讲一下 softmax 和 logistic 损失函数的关系就更好了。

1.两边取对数,把“积乘”变成积分, abc取对数后变成 log (a+b+c)
2.最大似然估计,需要让值尽可能大,确定最优的x,两边都*-1后,变成需要让值尽可能的小,确定最优的x
one-hot 向量 所有概率总和为1, 不是0就是1,把通过softmax函数后预测值\hat_y为底数,指数为0的项 \hat_y^0 = 1 指数为1的项 \hat_y^1= \hat_y 所有指数项相乘 ,所有项相乘结果为y, 这是预测y概率分布向量, 取对数后, Log \hat_y ^ y 把真数提取出来
y Log \hat_y, (就如同 log 100 = 2 * log 10 = 2*1 = 2)

读完之后,再来看评论,发现有相似感受的读者。的确,这版的表达别扭!

就是求完导数之后去凑softmax(oj)就行,就是注意那个求和里只需要对exp(oj)那一个量进行求导,不要漏了


请问这里(也就是3.4.7式的第二个等于号)确实是定义的意思吗,书上定义的等号有些地方不写def真的让人难懂

真是的结果 和 模型生成的结果,是相似的,但是不完全一样,那么损失函数就会有梯度,就是有差异,才会有梯度,要不然梯度就是0了

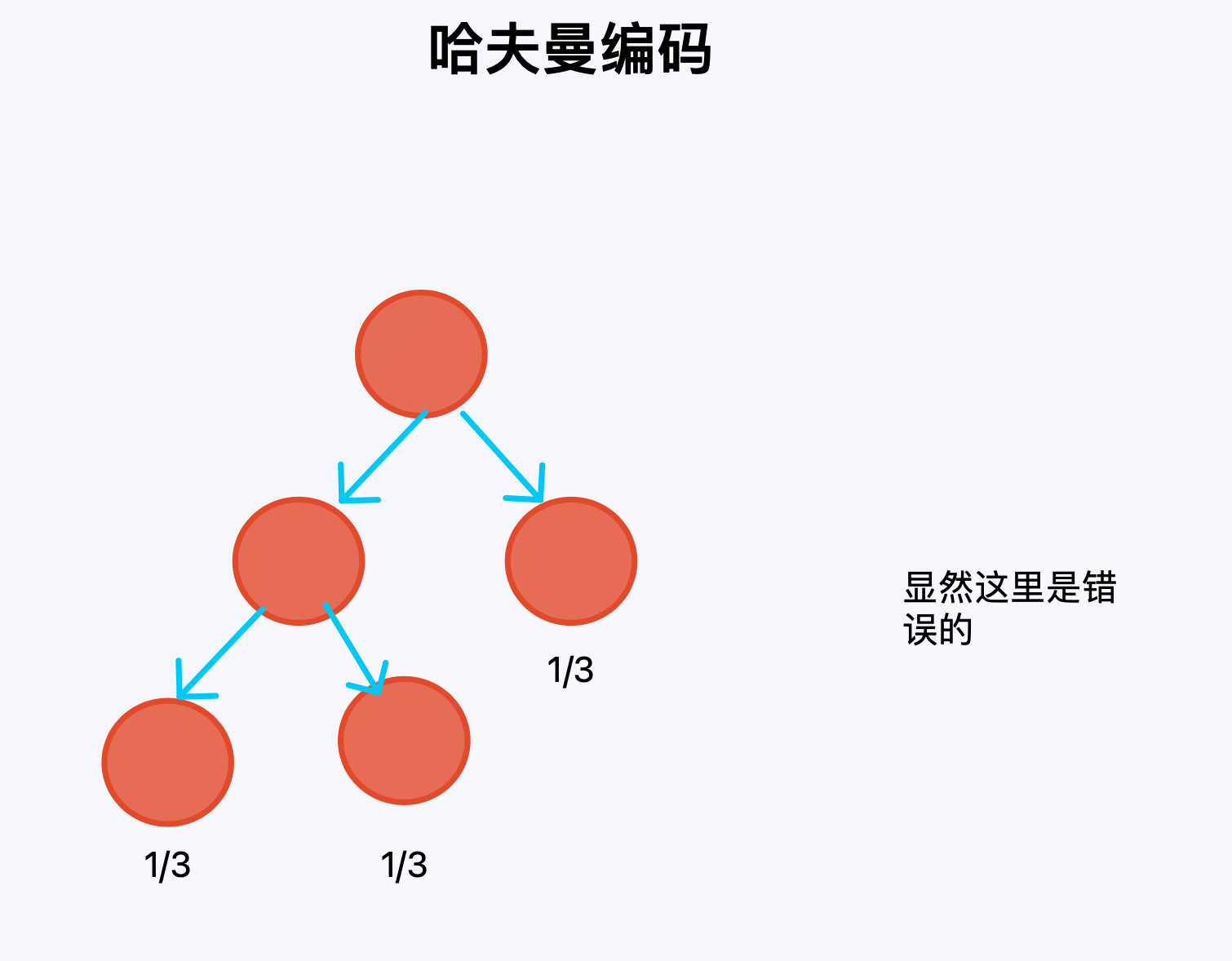
补充一下,哈夫曼编码可以简单理解为一颗二叉树,从树根开始,向左走记0,向右走记1,走到叶子的时候记录叶子结点的编码。
下面这个树中,从左到右的编码依次为00,01,1.


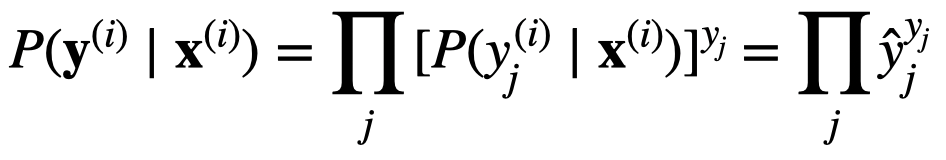

关于解释softmax中交叉熵损失函数的由来,
预测概率之所以可以被看成当前值在已知数据下的概率,应该是与极大似然的思想有关

同感,第二版读起来很别扭,甚至有些分散我的注意力 ![]()

这书看了一会,有点看不下去了,全是公式和推导,很容易陷入到复杂的细节中。真正的关注点应该是思想,比如softmax的核心是分类,有哪些优势等

我觉得不用改,惊讶的比喻非常妙,恰恰反映出了作者的独特见解。“信息量”这个翻译专业却又古板,跟我们我们本科信息论的说法一致,学的时候就味同嚼蜡,不如惊讶好理解。
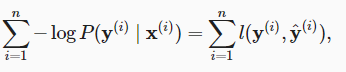 直接就相等了呀。不理解
直接就相等了呀。不理解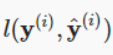 ,使其等于
,使其等于