兄弟写的很详细,我想的是如果把你第一题第二问中的o换成y会不会简洁一些,而且题干中要求使用二阶导数表示。还有第一题第一问,为什么前面对oj求二次导,后面又对oi求导了?没看明白
在兄弟贴中补充一下第二题我的浅薄理解:第一问将概率编码为二进制,特别是概率相等情况下,由于存在小数二进制编码问题从而存在精度问题,对于1/3无法用二进制编码精确表示,那么为了保证概率之和为一,编码后的概率将不再相等。第二问,使用哈夫曼编码两个独立的观测数据会发生什么?联合编码n个观测值呢?我觉得哈夫曼编码虽然能解决无损问题,但对于多个观测值需要建立庞大的编码表。这个问题关键应该在于独立性和联合性,我猜测这种编码同时存在无损概率表示,且满足独立可乘性质。然而这种编码是什么已经超出我的知识范围了。。。
我恰恰认为用惊讶很好啊,非常通俗易懂啊。。。
1 Like
想问一下,为什么要对 O_i 求导呢?有什么意义
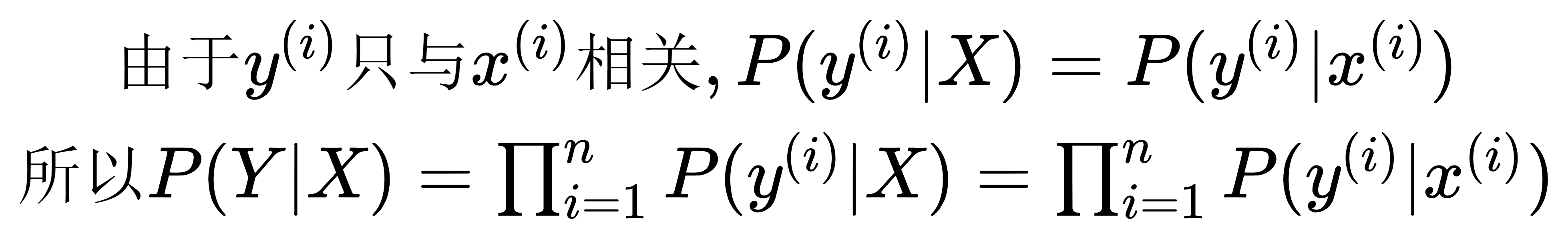

应该是因为链式法则的缘故。求梯度最终是要对参数求导的,但是对参数求导的过程中必定要经历损失函数对o_j求导,然后o_j再对参数求导的过程。
因为q维向量y是一个单位向量,所以y的元素y_j的取值要么是0要么是1且只有一个1,所以y_j的求和是1
3.4.8这个跳跃我觉得挺逆天的, 生怕别人看得懂还是咋地
确实 我都得对着英文原版看,翻译水平真的好差,
我还以为只有我看得蛋疼原来大家都蛋疼 ![]()
中文版文字表达前面看得还好,现在越看越像机翻
内容总有莫名其妙的跳脱,对基本功和推理能力要求太高,有时看着看着得停下来消化半天
1 Like
从新看了一下第一版这一章节,第二版确实没有第一版清晰
这样的公式推导应该是个特例,本质上应该是单个样本的信息量等于交叉熵
滥用n,看得一头雾水,滥用n,看得一头雾水

的确,第一版读的顺畅,内容过度也更自然。
关于3.4.7,在3.4.6中,因为概率向量是一个(0,1,0)的向量,因此发生y_j的概率P就是标签乘以预测值即y_i×y_hat,比如类别2,预测(0.1,0.2,0.7),那么准确预测的概率就是1×0.2,带入3.4.7的中间部分就可以得到信息熵公式
感觉这一小节的顺序有点凌乱,从3.4.7到3.4.8那一步转变很生涩。
通读下来,其实应当是先要介绍信息熵的概念,然后再来介绍 softmax 的损失函数,这样的顺序会更加让人读懂一些。当然,如果能顺带着讲一下 KL散度 的定义(其实信息熵那一小节已经简单介绍了这个概念),让后讲一下 softmax 和 logistic 损失函数的关系就更好了。
1.两边取对数,把“积乘”变成积分, abc取对数后变成 log (a+b+c)
2.最大似然估计,需要让值尽可能大,确定最优的x,两边都*-1后,变成需要让值尽可能的小,确定最优的x
one-hot 向量 所有概率总和为1, 不是0就是1,把通过softmax函数后预测值\hat_y为底数,指数为0的项 \hat_y^0 = 1 指数为1的项 \hat_y^1= \hat_y 所有指数项相乘 ,所有项相乘结果为y, 这是预测y概率分布向量, 取对数后, Log \hat_y ^ y 把真数提取出来
y Log \hat_y, (就如同 log 100 = 2 * log 10 = 2*1 = 2)