好棒!懂了。不过3.4.7中,请问为何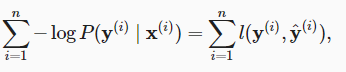 直接就相等了呀。不理解
直接就相等了呀。不理解
4 Likes
这是一种简略的写法,实际上是新定义了一个函数,也就是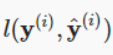 ,使其等于
,使其等于![]()
5 Likes
请问我应该如何发“PR”呢?页面上好像没有找到这个选项,谢谢!
应该在github的界面上发,这里是没有的


###########################################################################
3.4.9公式的第二行到第三行中,为什么yj的求和在第一项中去掉了,在第二项中保存下来了?????
1 Like
第一项后面是k,所以可以直接加了,加起来是1,所以省略
能否用神经网络去拟合pytorch中内置的损失函数BCELOSS,如果能网络结构应该是怎么样的》?
请问3.4.6.2损失函数求梯度为什么是对o_j求导,而不是对参数求导呢?

3.4.7到3.4.8的推导:输入[x1, x2, …, xd]到网络中得到输出[y’1, y’2, …, y’q],注意这里的每个输出y^i都是已经使用softmax归一化的概率。这时我们样本的标签对应为[0, 0, …, 1, …],就假设第i类为1好了,即yi=1,那么这时 p(y=i | X) = y’i。那么我们如何写成一个一般化的式子表示p(y=i | X)的概率呢?不妨这样表示 p(y = i | X) = (y’1 * y1) * (y’2 * y2) * … (y’i * yi) …(y’q * yq)。这样的话我们就可以得出极大似然估计的表达式了,即3.4.7 和 3.4.8。(‾◡◝)
AttributeError: module ‘torch’ has no attribute ‘synthetic_data’
AttributeError: module ‘torch’ has no attribute ‘set_figsize’
我在运行代码时出现这样报错有大佬可以帮我解析一下吗?抱歉我是个编程小白
楼上很多对3.4.7怎么推到3.4.8的讨论,我个人一开始没理解用极大似然怎么推出这个条件概率值的表达式,但是看了一下@zxhd863943427的推导也理解了:
极大似然是通过改变模型的参数θ,使得观测的事件发生的概率最大,这里θ就是估计的y的概率分布,所以要改变y的分布的值(特指yj情况下的y*)来使得发生事件(指这里的一个个样本,相互对立假设下概率值直接相乘)的概率最大,上述概率都是指给定x下的条件概率。
我就补充这个理解吧,具体计算再去看@zxhd863943427写的回答应该能看得更懂一些。(有错请指正我,概统已经是一年前学的了)
关于线性层和非线性层,不知道我理解的对不对,请大家批评指正。
这个模型包含了一个全连接层(线性)和一个softmax层(非线性)。
深度学习中只有线性层的情况下是无法作用于复杂问题的,而有了softmax层作为非线性层,就可以不加relu或者sigmoid层,也可以跑出正确的结果。
我的理解是,P(y’i | x’i) 描述的是一个概率,它的结果是一个标量而不是向量,所以 log P(y’i | x’i) 与 y_hat 'i 之前是无法划等号的。
根据 3.4.1 中的内容可知,每种类别对应的独热编码是唯一的,即第 n 个分量为 1 的 y 只有一个。或者说,独热向量 y 描述的是一个事件A,若 y 的第 n 个分量为 1 ,则事件 A 表示输入的 x 为第 n 类。
所以,假设 向量 y’i 的第 n 个分量为 1 ,它的概率应该为 P(y’i | x’i) = P(y_n | x) = y_hat_n
希望对你有帮助
我也有这个感觉,为什么第一版读起来很流畅
同样的疑惑,看到这块内容,感觉这里的公式表述不是很严谨,容易让人理解成一个向量。
我推出来也是这个答案,看起来大家应该都差不多