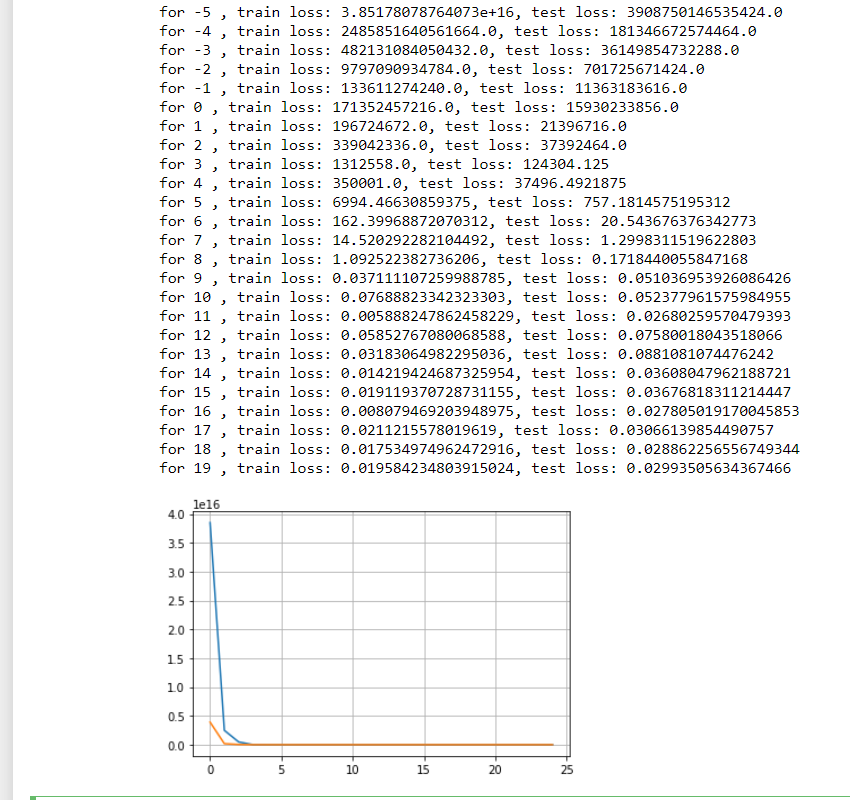
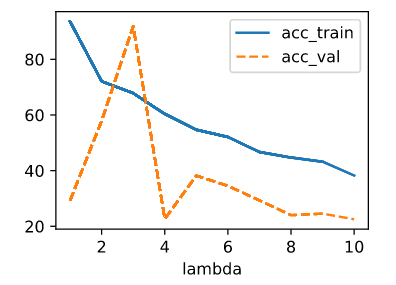
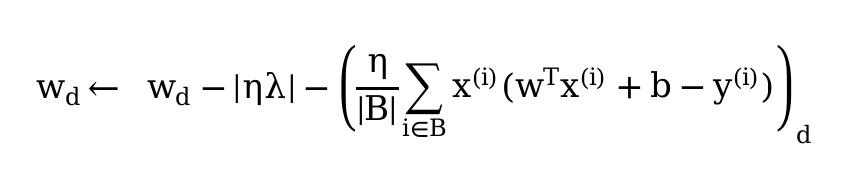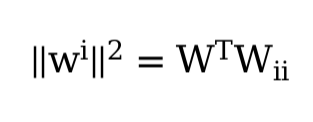It seem that a model with no regularization is better than a model with regularization in my case. Although the norm of the weights is significantly lower in the model with regularization, the plots are better in the unregularized one. Another problem is that the loss in my validation data is lower than the training loss. Here is my code:
import torch
from torch.utils.data import TensorDataset, DataLoader
import matplotlib.pyplot as plt
def synthetic_data(true_w, true_b, n):
X = torch.normal(0, 0.01, (n, len(true_w)))
y = torch.matmul(X, true_w) + true_b
y += torch.normal(0, 0.001, y.shape)
return X, y.reshape((-1, 1))
def load_array(array, batch_size, is_train=False):
''' Change array to a torch data iterator '''
dataset = TensorDataset(*array)
return DataLoader(dataset, batch_size=batch_size, shuffle=is_train)
n_train, n_test, n_inputs, batch_size = 20, 100, 200, 5
true_w = torch.ones((n_inputs, 1)) * 0.01
true_b = 0.05
train_data, train_labels = synthetic_data(true_w, true_b, n_train)
train_iter = load_array((train_data, train_labels), batch_size, is_train=True)
test_data, test_labels = synthetic_data(true_w, true_b, n_test)
test_iter = load_array((test_data, test_labels), batch_size)
# build the model
def linreg(X):
return X@W + b
# initialize the weights
W = torch.normal(0, 1, (n_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# define the loss function
def MSELoss(y_hat, y):
return (y_hat - y) ** 2 / 2
# define the L2 regularization term
def L2_penality(W):
return torch.norm(W) / 2
# Define the optimizer
def SGD(params, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
class Accumulator:
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, index):
return self.data[index]
def evaluate(data_iter):
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
l = MSELoss(linreg(X), y)
metric.add(float(l.sum().item()), len(y))
return metric[0] / metric[1]
# Write the training loop
epochs, lr = 100, 0.003
weight_decay = 0
train_loss = []
val_loss = []
train_metric = Accumulator(2)
for epoch in range(epochs):
for X, y in train_iter:
l = MSELoss(linreg(X), y) + weight_decay * L2_penality(W)
l.sum().backward()
SGD([W, b], batch_size)
train_metric.add(float(l.sum().item()), len(y))
train_loss.append(train_metric[0] / train_metric[1])
train_metric.reset()
# test the validation loss
l = evaluate(test_iter)
val_loss.append(l)
## print("Epoch {}/{} loss: {:.5f} val_loss: {:.5f}".format(epoch+1, epochs, train_loss[-1], val_loss[-1]))
print("Weight Norm: ", torch.norm(W).item())
plt.plot(range(len(train_loss)), train_loss, label='Train loss')
plt.plot(range(len(val_loss)), val_loss, label='Validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Training and validation loss")
plt.legend()
plt.show()
 Thanks for this amazing book.
Thanks for this amazing book.