http://zh-v2.d2l.ai/chapter_natural-language-processing-pretraining/bert.html

I agree with you, np.repeat( [0,1], 3 ) = [0,0,0,1,1,1]
在下一句预测里面为什么要先flatten encoded_X 啊? 根据后面, 不应该只输入<cls>对应的特征吗?
encoded_X = torch.flatten(encoded_X, start_dim=1) #这里为什么不是 encoded_X[:,0,:] ?
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape
我觉得应该是:
nsp_input = encoded_X[:, 0, :]
print("nsp_input", nsp_input.shape)
# NSP的输入形状:(batchsize,num_hiddens) 只需要输入<cls>的特征
nsp = NextSentencePred(nsp_input.shape[-1])
nsp_Y_hat = nsp(nsp_input)
nsp_Y_hat.shape
1 Like

- 为什么BERT成功了?
因为BERT整合了词的表示依赖于它们的上下文;对上下文进行双向编码,并且架构是任务无关的,从左到右编码上下文。
- 对于上下文敏感的词表示,如ELMo和GPT,词的表示依赖于它们的上下文。
- ELMo对上下文进行双向编码,但使用特定于任务的架构(然而,为每个自然语言处理任务设计一个特定的体系架构实际上并不容易);而GPT是任务无关的,但是从左到右编码上下文。
我也有这个疑问…
而且他说用单隐藏层的感知机, 可是代码中根本没有隐藏层.
我认为,单隐藏层就是nn.Linear。
使用torch.flatten是因为,在这个例子中,X.shape=(2,8,768),也就是有2个句子,每个句子有8个单词,目的是分类这两个句子。但是没有<cls>,所以它认为每个句子的嵌入([1,8*768])就是<cls>。
有的,但是这里的代码结构不好,增加了理解障碍。
很奇怪的,一个专用于nsp的linear被抽到了最后的整合代码里。NSP的MLP除了NextSentencePred函数中的self.output,还包括整合代码中的self.hidden。这样就存在一个隐藏层了。
确实应该这样,不过这部分代码放到了最后整合里,很奇怪。
不是的,不用强行解释。nsp的输入就是<cls>,只不过包括输入选择和隐藏层都放到了整合代码里。
self.output = nn.Linear(num_inputs, 2)
NextSentencePred类中的线性层参数在声明的时候就固定了,展平后的参数对不上。而且<cls>是一定会有的。
1 Like
此处只是简单演示而已,并不是真正写进BERT里面的逻辑。在后面BERTModel类定义forward函数,计算nsp_Y_hat的时候就是拿< cls >的向量去计算的,这样就与理论相同了。
exactly. 不过我反而要问为什么只使用 encoded cls token就足够了?

+1,同样感觉这样更正确,并且也符合文字和ppt的描述。


d2l1.0.3版本可以看英文版的代码,中文版的没有使用新的d2l包。
正如评论区有人说的,这里确实有两处错误:
- 这里的预测MLP应该是有两层,一层是隐藏层,一层是输入层。代码可能是简化了,代表的意思就是输入""token,输出二元判断。
- 注释写的输入是(batch_size, num_hiddens),然而下面的演示,把(batch_size, sentence_length, num_hiddens)按dim=1扁平化了,输入就成了(batch_size, sen_len * num_hiddens)和注释对不上,也和上面写的输入""token对不上。
- d2l包1.0.3版本请看英文版代码。
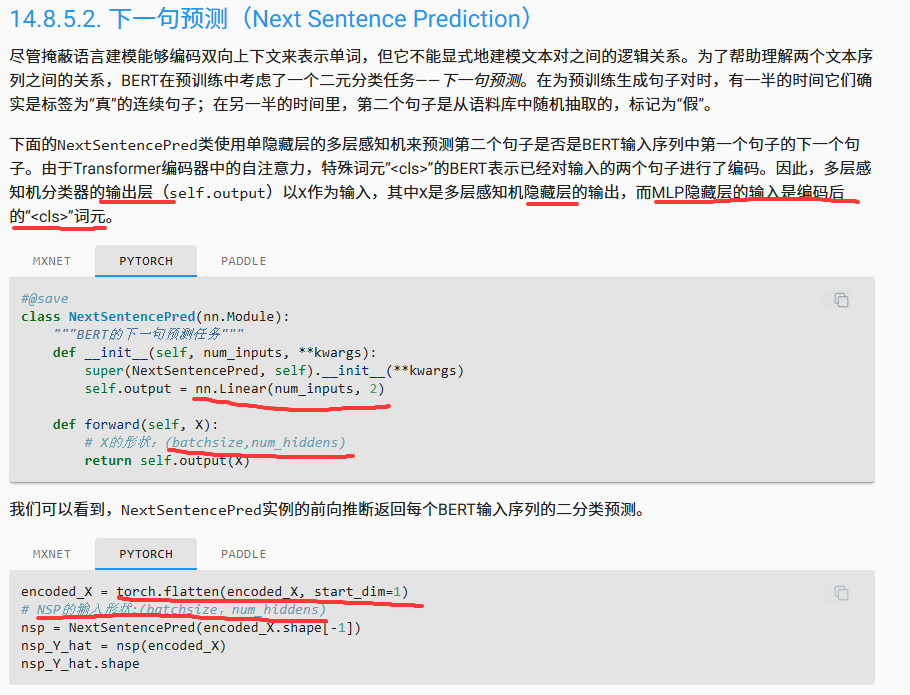
因为这个[CLS]在进来之前还得过一个隐藏层,他把隐藏层写道整合代码BERTModel里面了。至于为什么要flatten,是因为这段代码只是一个示例,他的形状得对才行,所以顺势展平了。