我建议大家本章的相关代码可以参考PyTorch API的架构。主要是这四个类
torch.nn.TransformerEncoderLayer()
torch.nn.TransformerEncoder()
torch.nn.TransformerDecoderLayer()
torch.nn.TransformerDecoder()
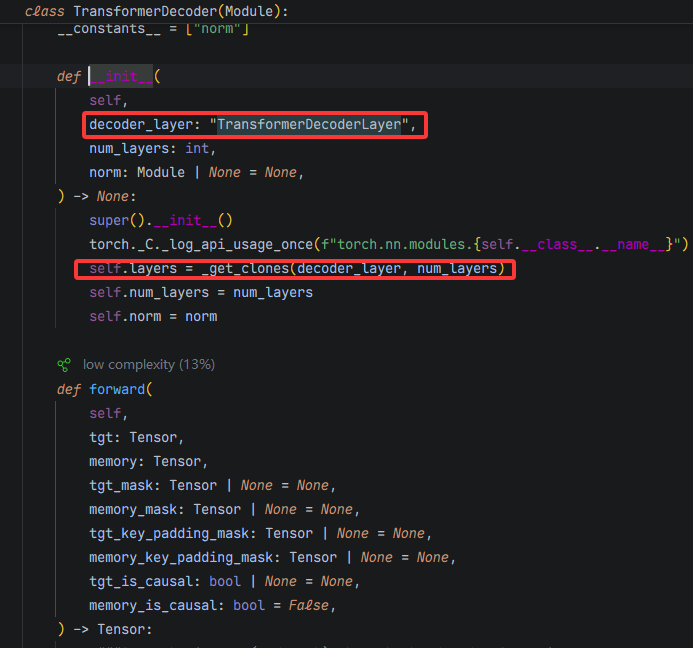
可以发现,从xxcoderLayer到xxcoder的时候,PyTorch是直接把构造好的一个Layer输入到xxcoder。
TransformerDecoder源码如上,可以看到,直接将输入的Layer复制了num_layers个然后保存。这时候是并没有把第i个layer这个信息保存到layer中的。确实也不需要,因为每个layer的工作基本是一样的。
D2L这引入i的原因就是为了在预测的时候,对于每一个Layer_i,在对一个序列运行(预测)到第n次的时候,都要把本次得到的x拼接在前面的n-1个x后,才能得到第n步的kv对(decoderLayer的第1个子层,看架构图很清晰)。
我的做法是直接在TransformerDecoderLayer增加一个字段,保存了这个kv对信息。每一次执行上下文都不一样,因此在Decoder执行init_state方法时,遍历decoderLayer清除这个字段信息即可。以下是我的部分代码:
class TransformerDecoderLayer(nn.Module):
def __init__(self, embed_dim: int,
num_heads: int,
ffn_hiddens: int,
dropout: float = 0,
bias: bool = False):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.masked_attention = nn.MultiheadAttention(embed_dim, num_heads, dropout, bias=bias, batch_first=True)
self.add_norm1 = AddNorm(embed_dim, dropout)
self.attention = nn.MultiheadAttention(embed_dim, num_heads, dropout, bias=bias, batch_first=True)
self.add_norm2 = AddNorm(embed_dim, dropout)
self.ffn = PositionWiseFeedForwardNetwork(ffn_hiddens, embed_dim)
self.add_norm3 = AddNorm(embed_dim, dropout)
self.key_values: Tensor | None = None
self.masked_attn_weights = None
self.attn_weights = None
def forward(self, x: Tensor, state: tuple[Tensor, Tensor]) -> tuple[Tensor, tuple[Tensor, Tensor]]:
(encoder_x, valid_lens) = state
if self.key_values is None:
self.key_values = x
else:
self.key_values = torch.cat((self.key_values, x), dim=1)
batch_size, seq_len, _ = x.shape
attn_mask1 = torch.ones(seq_len, seq_len, device=x.device).triu(
diagonal=1).repeat(self.num_heads * batch_size, 1, 1).bool() if self.training else None
x1, attn1 = self.masked_attention(x, self.key_values, self.key_values, attn_mask=attn_mask1)
self.masked_attn_weights = attn1
x2 = self.add_norm1(x, x1)
x3, attn2 = self.attention(x2, encoder_x, encoder_x,
attn_mask=attn_mask(valid_lens, seq_len, encoder_x.shape[1],
num_heads=self.num_heads))
self.attn_weights = attn2
x4 = self.add_norm2(x2, x3)
x5 = self.ffn(x4)
return self.add_norm3(x4, x5), state
def reset_attention_weights(self):
self.masked_attn_weights = None
self.attn_weights = None
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, decoder_layer: TransformerDecoderLayer, num_layers: int, vocab_size: int, dropout: float = 0):
super().__init__()
self.embed_dim = decoder_layer.embed_dim
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, self.embed_dim)
self.pos_encoding = PositionalEncoding(self.embed_dim, dropout=dropout)
self.layers = nn.ModuleList(copy.deepcopy(decoder_layer) for _ in range(num_layers))
self.dense = nn.LazyLinear(vocab_size)
self._masked_attn_weights: list[Tensor] = []
self._attn_weights: list[Tensor] = []
@property
def attention_weights(self) -> tuple[Tensor, Tensor]:
""""
获取并合并所有解码时间步的注意力权重
:return: 注意力权重张量,形状为 (num_layers, batch_size, queries_num, keys_num)
"""
return attn_merge(self._masked_attn_weights, self.num_layers), attn_merge(self._attn_weights, self.num_layers)
def init_state(self, enc_all_outputs, *args):
for layer in self.layers:
layer.key_values = None
return enc_all_outputs, *args
def forward(self, x, state):
ems = self.embedding(x)
x = self.pos_encoding(ems * math.sqrt(self.embed_dim))
for layer in self.layers:
x, state = layer(x, state)
self._masked_attn_weights.append(layer.masked_attn_weights)
self._attn_weights.append(layer.attn_weights)
return self.dense(x), state
def reset_attention_weights(self):
for layer in self.layers:
layer.reset_attention_weights()
self._masked_attn_weights = []
self._attn_weights = []