应该是监督学习啊,训练的时候有个tgt_vocab
我也许并不能很好的回答你的问题,我找寻了很久也没有获得想要的答案,我思考了很久总结了一些观点,希望能和大家一起讨论讨论这个问题,以下是个人的一些看法.
我们知道,embedding 是一种缩放(缩小或放大)语义信息到一定维度空间的手段,在这里是输入一个 vocab_size 的 query,然后获得hidden_size维度的 embedding, embedding的好处是可以通过学习使得语义相近的样本在 embedding后距离更相近.
一种可能的解释是:当num_hiddens 增大时,嵌入向量的维度也会相应增大,这会增加模型学习到的单词或符号的语义信息.然而,(num_hiddens 较大时)此时我们想要加入位置编码,就有种有心杀贼无力回天的感觉,我们无法确保在茫茫数据海中(而且数据本身也是服从(0, 1)的分布),提取出位置信息,我认为如果不扩大位置编码提供的位置信息,将无法很好地区分不同位置处的单词或符号.因此,为了更好地结合语义信息和位置信息,一种可行的做法是增加位置编码在嵌入中的比例,但是我们知道的是模型的参数最好能控制在较小的范围(稳定性和收敛速度),不能无限制的根据 num_hiddens 放大这个占比,所以选用了平方根进行一定的缩放(你也可以试试log 缩放).
也许我的理解是错误的,希望如果有人能有正确的结论,请不吝赐教,我十分感谢. ![]()
token是one-hot,经过embedding相当于从词嵌入矩阵W中取特定行,而W被 Xavier初始化,其方差和嵌入维数成反比。也就是嵌入维数越大,方差越小,权重越集中于0,后续再和positional encoding相加,词嵌入特征由于绝对值太小,可能被位置信息掩盖,难以影响模型后续计算。因此需要放大W的方差,最直接的方法就是乘以维度的平方根。
1 Like
你说的只是用到了X的无监督可能是BERT,使用了transformer的encoder部分,基于自监督学习做预训练,然后作为特征提取器用于下游任务。和MLP、RNN一样,transformer只是一种架构,既可以无监督(比如BERT、GPT)也可以有监督(比如ViT)。
中文版的代码没有更新,看d2l的API文档很多写法都变了,有些甚至输入参数数量都变了,这章建议就看个原理,代码实现还是看看英文版吧
你不说我还没注意,不止是代码,章节都不一样,英文版多了不少新内容。
英文版的代码一年前就被重构了,看来中文版出版以后很少维护了。
original:
def init(self, ffn_num_hiddens, ffn_num_outputs, **kwargs):
super(PositionWiseFFN, self).init(**kwargs)
new:
def init(self, ffn_num_hiddens, ffn_num_outputs):
super().init()
我的理解是:如果是[10,32]的话,那么就是[10,32]形状的矩阵会被归一化,但是每个单词的特征维度是32维吧,而不是10x32,因此只需要[32]即可
transformer是监督学习,Decoder的输入部分是groud_truth
你说训练时已经包含了序列信息。。意思是训练习得了?如果是那何必第一个bos时加,这样做不是相当于全局一样了吗?意义在哪
几个问题:
- 首先你的说法第t步时使用t-1步的位置编码是否正确?不是应该使用自身的t步编码吗?训练就 是这样的
- 你提到这个预测时只使用第一步编码,应该是原代码不正确
- 我之前屏蔽了positional encoding,但效果并没有显著变化。即相当于目前代码添加一个常量。所以这个bleu不同训练次数是有变化的,可能不能准确反映更正后positional encoding效果
- 看了你的代码跟原代码差不多意思。我干脆做了更加精简版本(但效果如上所说并不是bleu始终是4/4,有时3.65/4. 注意我说的是4个句子)
emb_norm = self.embedding(X) \
* math.sqrt(self.num_hiddens)
historic_kvs = state[2][0] # uses the first layer is enough
if historic_kvs is None or no_fixed:
X = self.pos_encoding(emb_norm) #⚠️X已经由(n,s)变成(n,s,h)
else: # fixed: 修正*预测时*固定使用第一个token对应的位置嵌入矩阵行向量
# print('training step must not come here!')
cur_step = historic_kvs.shape[1] + 1
emb_norm = emb_norm.repeat(1,cur_step,1 )
X = self.pos_encoding(emb_norm)
X = X[:,-1,:] # restore the target last step
X = X.unsqueeze(0)
'''
11 2 torch.Size([1, 2, 32]) torch.Size([1,1, 32])
'''
# print('11', cur_step,emb_norm.shape,X.shape)
其它代码完全不用变化
“训练时在解码器中并不必考虑样本中翻译后的句子的有效长度,因为预测出来不一样长的惩罚最终会体现在loss中”,这句话不同意。这里本质上和之前基于attention的seq2seq的key,value没有区别,理论上就应该使用真实的dec_valid_len,而不是通过loss去优化参数,因为使用loss依然会使用作为key,value,那为什么不提前把通过dec_valid_len去掉呢?论据之一就是编码器输出的key,value对是带有valid_len的,所以这里self attention的key,value没有理由不使用dec_valid_len,如果按照源代码的逻辑,甚至没必要用arange,训练的时候也用None,效果和arange有什么区别吗?
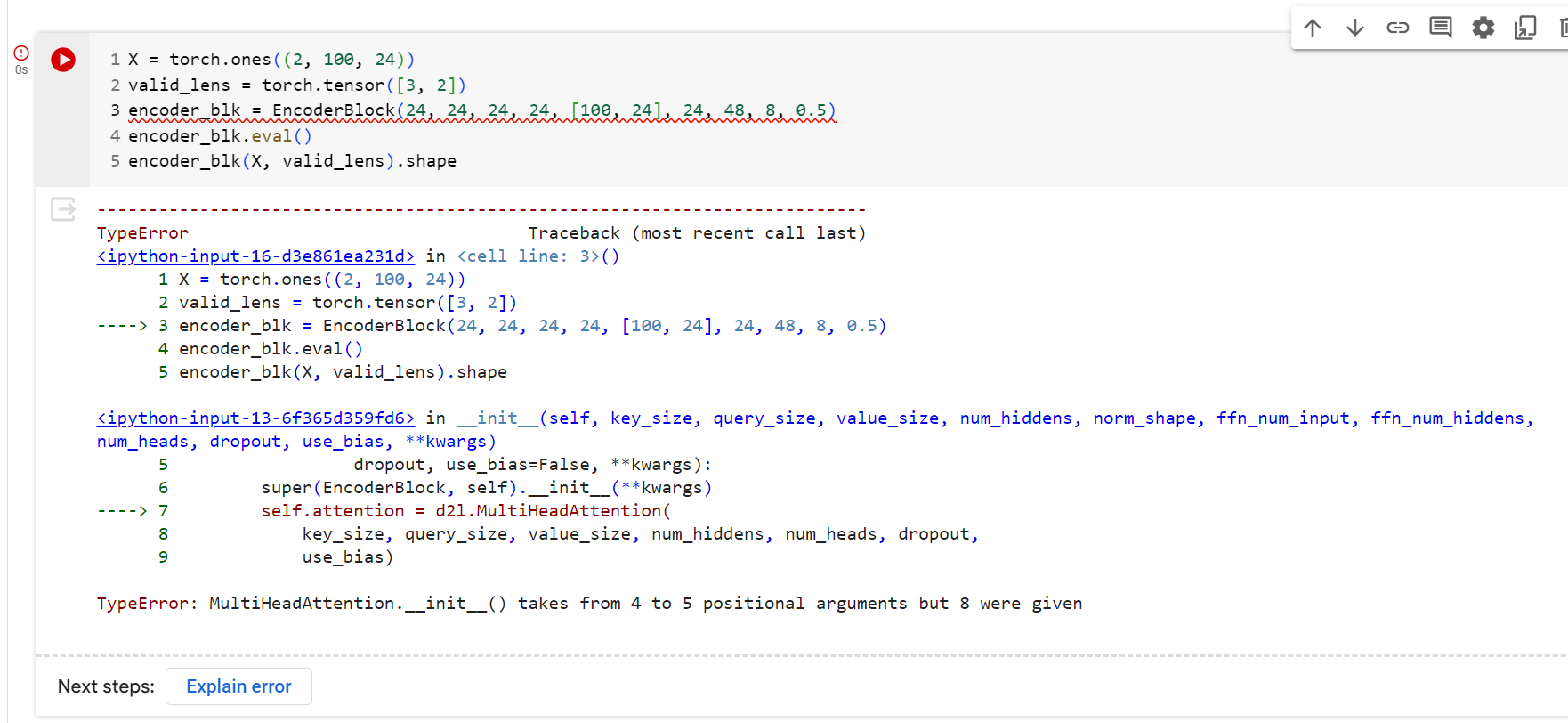
没有大佬能回复下吗? 报错说多头注意力部分有问题,跟D2L 库相关,不懂怎么debug呀~~~谁能棒棒忙吗? 谢谢大佬们~
呃,我是这么处理的,因为源代码是直接通过d2l库进行的引用,从而引发的报错(这个报错很离谱啦),所以我直接把multi-head attention的定义类时的代码给复制过来,放到同一个IPython 的notebook 里面定义,然后在encoder的Class定义里面把multi-head attention哪里的 d2l. 给去掉,然后就可以正常运作了 ,属于笨方法
Cool, 笨办法也是办法,我都没思路, 我去试试,谢谢啦 ![]()
这里的norm_shape可以为list或者int,当为int的时候就是对最后维度(特征维度)进行归一化,为(num_steps,dim)时为最后两个维度进行归一化,就只剩batch维度了。
其实这里就是牵扯到了大家都在讨论的问题,当模型为预测模式时,X的形状为(1,1,num_hiddens)了,layernorm传入两个维度会出错,所以偷懒的话可以在DecoderBlock里面加入一行代码:
if self.eval:
norm_shape = norm_shape[-1]
预测时就不会出错了。但是还是有位置编码的问题没有解决。
# 加性注意力取代缩放点积注意力
class MultiHeadAttention2(nn.Module):
"""Multi-head attention.
Defined in :numref:`sec_multihead-attention`"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention2, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.AdditiveAttention(int(key_size/num_heads), int(query_size/num_heads), int(num_hiddens/num_heads), dropout)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
queries = d2l.transpose_qkv((queries), self.num_heads)
keys = d2l.transpose_qkv((keys), self.num_heads)
values = d2l.transpose_qkv((values), self.num_heads)
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for
# `num_heads` times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# Shape of `output`: (`batch_size` * `num_heads`, no. of queries,
# `num_hiddens` / `num_heads`)
output = self.attention(queries, keys, values, valid_lens)
# Shape of `output_concat`:
# (`batch_size`, no. of queries, `num_hiddens`)
output_concat = d2l.transpose_output(output, self.num_heads)
return self.W_o(output_concat)
使用加性注意力
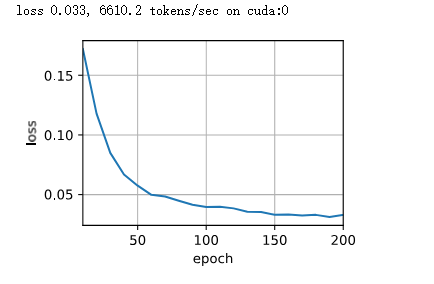
self.W_o忘了要不要保留
求助:多头注意力机制后添加残差连接,是否会因为将所有信息都传入网络,从而导致掩蔽(masking)的作用被破坏
你好,请问我在测试TransformerEncoder模块时,出现 AttributeError: ‘DotProductAttention’ object has no attribute 'attention_weights’的问题该怎么解决
掩蔽主要是针对注意力机制的,防止注意力关注到“未来”或“无效”的信息。在Transformer架构中的3个注意力模块内正确进行掩蔽就可以了。模块外采用残差连接,导致所有信息都向下游传递问题不大。
你可以做个对照实验看看,效果上应该没什么差异