其实这里没问题,只是把多个头的输入的变换矩阵拼成一个大矩阵而已
这里确实是query_size,从w_q的形状就能看出来。
这个多头注意力看了好久终于算看明白了。
其实,小结中“多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。” 这句总结有助于理解代码,本文将Q,K,V分成不同的子空间,对每个子空间进行注意力汇聚,然后再将输出合并,代码实现的很巧妙,精华就是transpose_qkv和transpose_output这两个函数,值得细品
如果 num_hiddens ≠ key_size 那么程序就跑不了,会报矩阵不能相乘,既然这样那为什么还要把这两个参数分离开,明明只有一个自由度
说出了我的疑惑。。。。。。。。。。。。。。。。。。
你这段话非常正确,本质就是把每个query,key,value都切分成num_heads段,对每一段应用注意力机制,从而更好提取局部特征,也就是作者说的子空间。
1 Like
是不是可以这样理解,沐神写的那个代码直接把每个头的全连接层拼在了一起,也就是说那个上边写的num_hiddens其实并不是每个头的num_hiddens,而是这个值 * num_headers,
1 Like
我理解应该是先做完W_q,W_k,W_v后才拆分的多头,再进入transpose_qkv后拆分多头
2 Likes
query,key,value在送入多头之前已经经过了全连接层的编码,因此送入不同的头的数据是不同的

首先,需要陈清的是:多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示,而非将相同的query/key/value经过不同的线性变化级联后再经过线性变化压缩为原长度。
假设有以下具体的参量:
| 名 | 值 | 名 | 值 |
|---|---|---|---|
| batch_num | 2 | num_heads | 5 |
| num_hiddens | 100 | valid_lens | [2,3] |
| query_size | 5 | query_num | 4 |
| key_size | 10 | key_num | 6 |
| value_size | 15 | value_num | 6 |
则有普通注意力机制与多头注意力机制的对比如下:
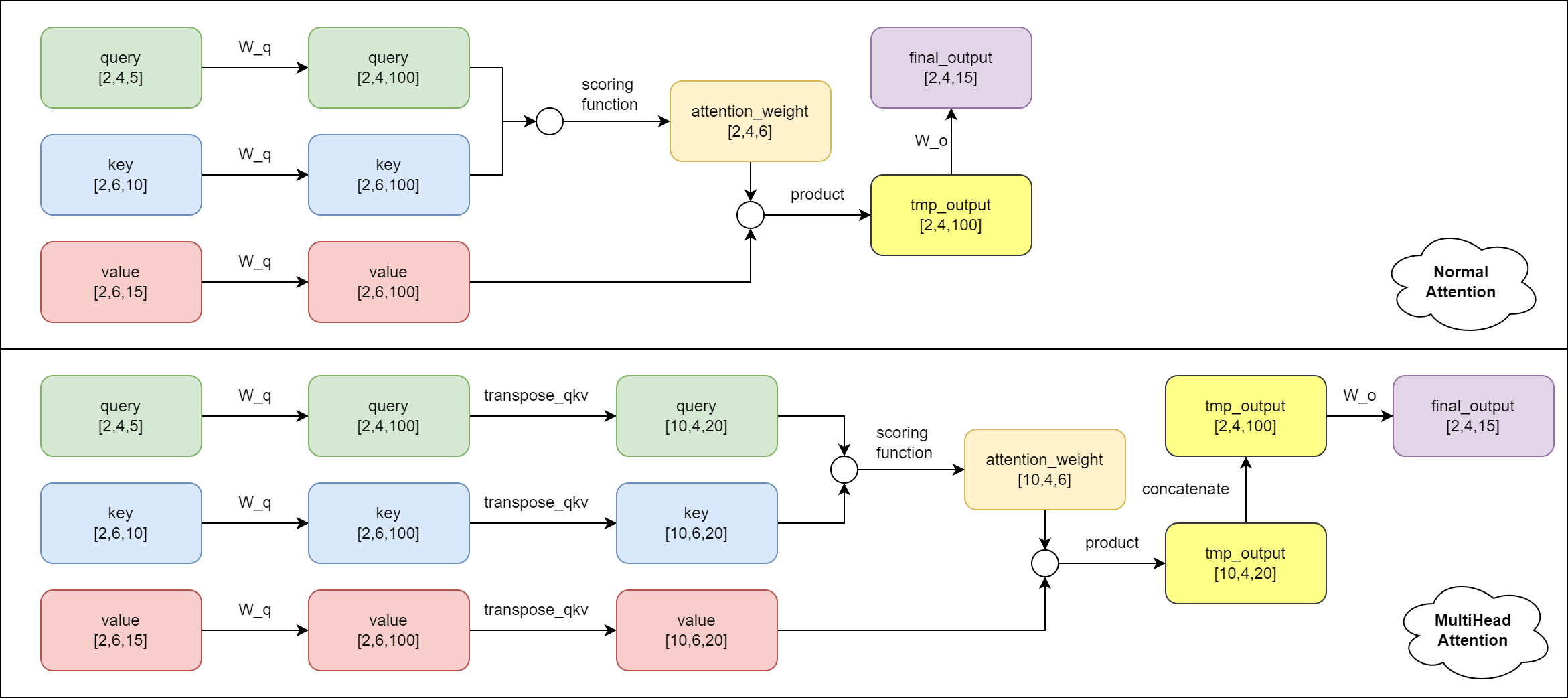
呃,我理解应该是这样的,如若有误,欢迎指正!
2 Likes
请问您是用什么画图软件来绘制这个图的?我也想整理一下
我理解的是 W_q, W_k, W_v其实是把多个头的 weight 并在一起使用的,所以并没有问题。只是代码用同步的方式(把 heads 加入到 batch 的维度当中,避免 for 的串行计算),同时计算多个头。
1 Like
看了几遍才看懂。。这里面的维度变换确实有点复杂。不过看懂用意就知道为什么这么做了。我认为应该是出于并行计算的优势才将所有头的fc参数放在一起,然后再分成基于每个头的q,k,v参数以便进行各个注意力头的输出的计算,这里面的每个注意力头的参数量应该是为num_hiddens/num_heads,然后再将各个头的输出组合在一起经过全连接层线性变换增加各个注意力头输出的融合,不知道我这样理解对不对。。
看似是一个单头注意力,但是经过维度变换成了多头再进行注意力的点积运算也是分每个头去计算的注意力输出
我试过这样直接reshape会把原tensor从最后一个维度开始全部展开再重塑,permute会把轴的顺序打乱再塑形的时候维度展开的顺序就不一样了,所得到的tensor也不一样
假设有 8 个并行的头:
Head 1: 关注局部相邻关系
Head 2: 关注长距离依赖
Head 3: 关注语法结构
Head 4: 关注语义相似性
...
Head 8: 关注其他特定模式
多头注意力的 pythonic 实现,应该易于理解:
多头的并行计算什么的只是矩阵的分块乘法罢了。初始化参数不一样的话经过学习最终参数应该也会不一样,输出也会有差别,就像卷积里的多个卷积核,用随机初始化来赌找到特征的概率。