是的,应当是query_size/key_size/value_size,在经过W_q/W_k/W_v后,才转为num_hiddens。不过transformer中为了保证参数量一致,取的这几个值是相同的。
这样看确实有点歧义,不过这本书很多代码经常在代码的前面注释形状,我已经习惯了 ![]()
1 Like
这是我的课后练习第一题的结果,看起来好像和前面的例子的输出差不多,不知道对不对
(我突然发现,书里面的加性注意力和点积注意力的权重可视化图是不是有问题(不知道是不是我理解有误)?书里都把权重注意力矩阵reshape为(1,1,2,10), 是不是应该为(2,1,1,10)?,求指点!)
利用valid_lens进行遮掩的时候,是不是应该保留每行中scores最高的几个值呢?但是按照前面章节函数的定义,都是保留索引靠前的scores。
1 Like
不是的,对于key-values可以理解为T吧,query是超参数,在添加attention的seq2seq里面取的是1,因为每预测一个词后续的context要更新。
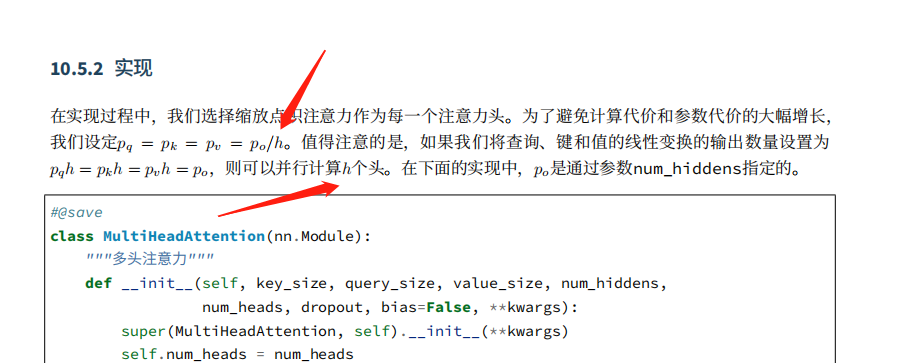
没有错。是h个头。Pq=Pk=Pv=Po/h。
原始输入的QKV就是已经包含了h个head,比如这里
X = torch.ones((batch_size->2, num_queries->4, num_hiddens->100))
因为head指定为5,所以实际每个head对应的输入实际为 torch.ones((batch_size->2, num_queries->4, num_hiddens->20))
之所以把他们放在一起就是为了便于并行加快计算。
所以代码中
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
实际是5个head的线性变化参数都包含在里面了,这也就是所谓的并行。
1 Like
对啊,5个head并行计算,那自注意力头的多头不就是5个嘛?哪来的h个呀?
看他的代码实现,将特征维度拆开来补充多头注意力数量,相当于在批量大小上乘注意力头数h。所以我认为q,k,v并不是简单的复制h份,而是将输入特征拆分为h份,特征维属列空间,不同注意力机制处理输入的特征子空间。最后的concat操作组合了不同特征子空间,与w_o做矩阵乘法相当于每一个查询对应的输出值是不同子空间与不同权重乘积的组合。或者说,原来是Q与K直接点积,注意力直接体现在点积结果,缺点是在完整特征维度考虑相似性,没有考虑局部特征相似性;而现在,将Q与K从特征维拆成了h份,每一份单独点积计算注意力,考虑了局部特征相似程度,最后再concat到一起,便于与W_o相乘,从而为每一个局部特征分配关注权重,这样,不同的查询对应了不同局部特征的关注程度,相比于加权平均来说提升了一个维度,即在局部特征上分配权重求和,这样得到的结果更复杂,也体现了局部特征的重要性(图像识别中感受野过大不利于局部特征提取是一个意思)
3 Likes
初始时是一样的,学习之后不一样,每个参数学到的东西不同,就不一样了。
这里num_heads=5,h就是5呀,没有错。
其实是有一点疑问,length_of_QKV是由词数量和词嵌入张量展平得到(可能经过全连接层形变)那代码中的number_of_QKV是如何产生的?它的实际意义是什么呢?将句张量复制多次得到的并行值?
太优秀了,一下子就理解了多个头怎么并行了,pytorch里的MultiheadAttention也是这么实现的
太强啦 一下子就清晰了 能请教下这个图是用啥画的吗
说下我的看法,大家先不要管transpose_qkv函数。首先明确一点,N个多头的概念,是把query,key,value,分别通过N个全连接神经网络嵌入到另一个维度空间,如3维。为了简化操作,是可以把这N个网络拼接一起的,形成一个3N输出的空间(W_q),在这大网络中,依次每N个节点一组代表之前网络。想明白这点,就可以理解transpose_qkv了,transpose_qkv不是对原始query、key、value变化,二是嵌入后N个query’、key’、value’ 做拆分。最后整体输出的时候transpose_output 再变化回去。
我比较好奇,如果不对values的最后一轴除以num_heads做拆分,然后保留num_hiddens维,使用得到的多头注意力评分对num_heads个values最后一轴做加权和或者加权连接。这样的处理是否有意义,对性能影响又有多少
这里用valid_lens遮掩的意思是把输入中属于填充的那部分遮掩掉,因为这部分没有意义,不应该参与注意力的计算。
num_of_QKV在机器翻译里面其实就是句子的长度吧,也就是之前的num_steps。length_of_QKV指的是特征维度,在实际机器翻译案例里面就是num_hiddens
在自注意力中Qnums KVpairs nums有什么关系,因为QKV可以理解成来自一个token,示例中Q数量是4个,KVpairs数量是6个
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
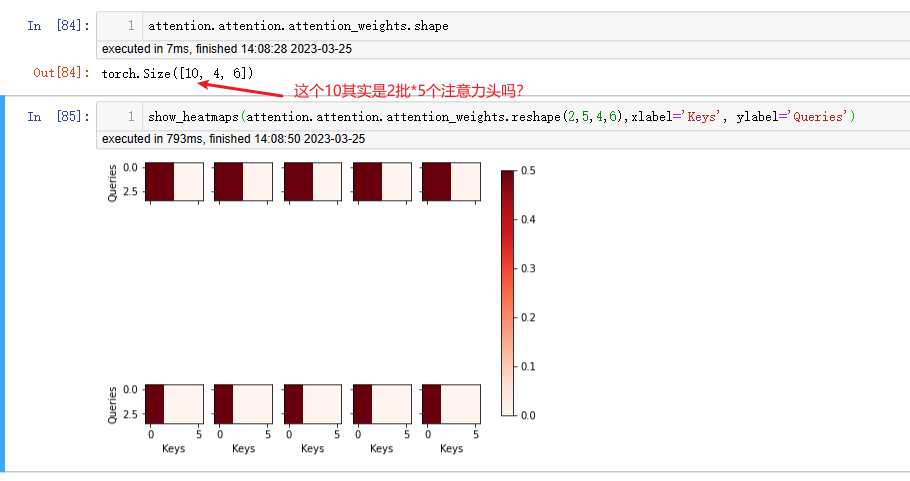
形状的第二个值不应该就是size了吗?