#Q3
Data Augmentation后用SGD训练更稳健
#@练习2
import random
class replace_load_array:
def __init__(self, data, batch_size):
self.data = data
self.n = int((data[0].shape[0]/batch_size))
self.batch_size = batch_size
def __iter__(self):
for i in range(self.n):
rand_num = random.randint(1,self.n)
yield self.data[0][self.batch_size*(rand_num-1):self.batch_size*rand_num], \
self.data[1][self.batch_size*(rand_num-1):self.batch_size*rand_num]
def __len__(self):
return self.n
def get_data_ch11_2(batch_size=10, n=1500):
data = np.genfromtxt(d2l.download('airfoil'),
dtype=np.float32, delimiter='\t')
#print("data",data,data.shape)
data = torch.from_numpy((data - data.mean(axis=0)) / data.std(axis=0))
data_iter = replace_load_array((data[:n, :-1], data[:n, -1]),
batch_size)
return data_iter, data.shape[1]-1
data_iter, _ = get_data_ch11_2(10)
trainer = torch.optim.SGD
train_concise_ch11(trainer, {'lr': 0.01}, data_iter)
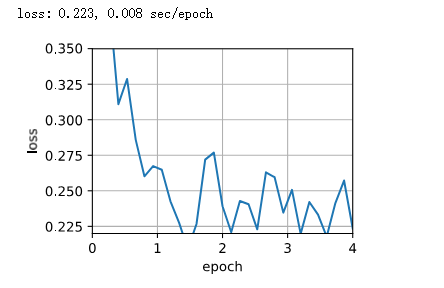
从零开始实现里面计算sec/epoch是不是写错了,计算一次时间的条件是n%200==0。也就是每训练200个data point计时一次。本来当batch size能整除200的时候也没什么问题,结果仍然具有可比性。但是当使用GD bs=1500的时候就出bug,必须得n=3000才能满足n%200==0