
我理解为11.3.8式子,就是上式对符号ε求导
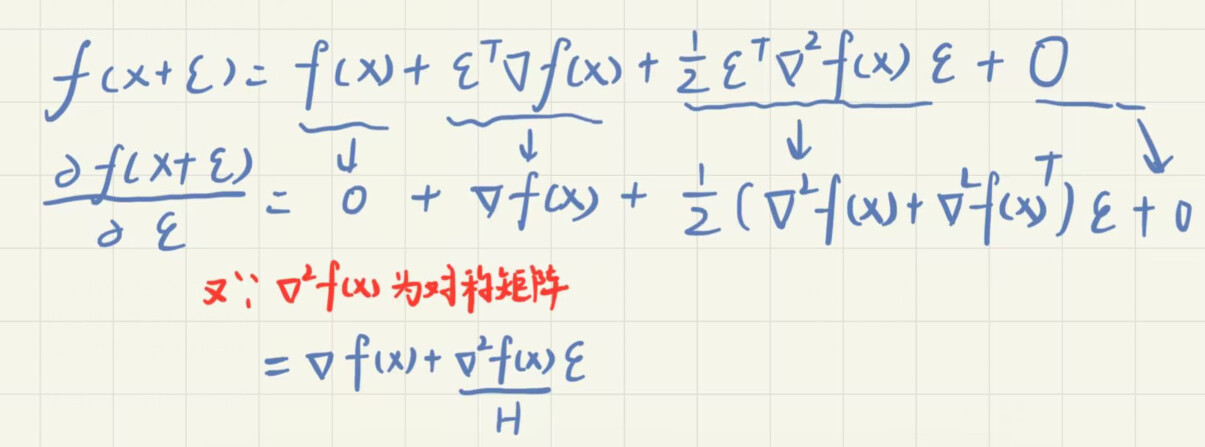
这里写的不好, 其实应该是g(ε) = f(x+ε); 则g(ε) - g(0) = f(x+ε) - f(x) = 展开的那一串. 此时若f(x+ε)达到了极小值点, 即g(ε) 达到了极小值点, (# 注意!!! 我们此时ε才是变量, x是常量), 对ε求导, 就可以得到后面的式子了.
这里面有个问题, 就是凸优化中没有规定何为"恒定"收敛速度, 在文中给出的例子, 牛顿法是二阶收敛的, 一般只有线性, 超线性, 次线性以及r阶收敛, 没有听说过恒定收敛这个词.
在预处理中,
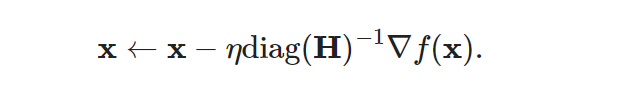
这个公式是如何做到为每个变量选择不同的学习率的?
这一节都没什么评论是不是很多人都看不懂。。我也是。。有没有数学大神出来完整解释一下
贴一下AI的回答:
核心思想:用二次函数局部近似目标函数,然后通过求解这个二次函数的极小值点来更新当前解。
对于一个多元函数 f(x),在当前点 xk 处进行二阶泰勒展开:
为了找到这个近似二次函数的极小值点,我们对其求导并令导数为零:
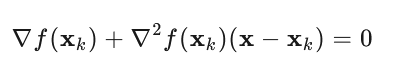
解得牛顿法的更新公式:
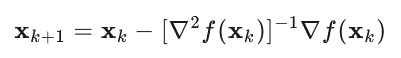
我的理解是如果曲线变化很快,那么f(x)‘和diag(H)会都是较大的值,f(x)’/diag(H) 计算后会整体变小;同样的当曲线平缓,那么f(x)‘和diag(H)会都是较小的值,f(x)’/diag(H) 计算后会整体变大
更形象一点就是 5/5 = 1;0.5/0.5 = 1
这样就相当于 为每个变量选择不同的学习率
对牛顿法的解析
$$f(\mathbf{x} + \boldsymbol{\epsilon}) = f(\mathbf{x}) + \boldsymbol{\epsilon}^\top \nabla f(\mathbf{x}) + \frac{1}{2} \boldsymbol{\epsilon}^\top \nabla^2 f(\mathbf{x}) \boldsymbol{\epsilon} + \mathcal{O}(|\boldsymbol{\epsilon}|^3).$$
上式可以理解为,x固定,使用$\epsilon$进行横轴上的位移去寻找使得$f(x+\epsilon)$最小时的$\epsilon$,此时x当做常量,只有$\epsilon$变化,令$g(\epsilon)=f(x+\epsilon)$,所以就可以对$\epsilon$求导。
$$g(\epsilon) = f(x+\epsilon) = f(\mathbf{x}) + \boldsymbol{\epsilon}^\top \nabla f(\mathbf{x}) + \frac{1}{2} \boldsymbol{\epsilon}^\top \nabla^2 f(\mathbf{x}) \boldsymbol{\epsilon} + \mathcal{O}(|\boldsymbol{\epsilon}|^3).$$
要找到$f(x+\epsilon)$的最小值,那么就是找到$g(\epsilon)$的最小值,也就是$g(\epsilon)$的一阶导为0.
也就可以得到下面的式子了:
$$\nabla f(\mathbf{x}) + \mathbf{H} \boldsymbol{\epsilon} = 0 \text{ and hence }
\boldsymbol{\epsilon} = -\mathbf{H}^{-1} \nabla f(\mathbf{x}).$$
其实$\epsilon = - \frac{f’(x)}{f’'(x)}$。
例如函数$f(x)=x^2$,$f’(x)=2x$,$f’‘(x)=2$,那么从当前$x$需要走$\epsilon = - \frac{f’(x)}{f’'(x)}=-\frac{2x}{2}=-x$步就可以达到最小值点$x+\epsilon=x-x=0$。
确实当$x=0$, $x^2$为最小值0,非常牛顿。
但是牛顿法对非凸问题没那么有效;且要计算二阶导,参数多的时候计算量超大,多变量一阶导数为向量,二阶导为矩阵,还要求其逆,计算复杂度直接到$O(d^3)$。
请问关于收敛速度这一块的内容有推荐的书或博客嘛