https://zh-v2.d2l.ai/chapter_computer-vision/neural-style.html
上个图,对比原图看一下效果
原图(600x333):

处理后(450x300):

1 Like
请问您是怎么保存的output的图片?是使用d2l.plt.savefig吗?,能否分享下您的jupyter
1 Like
def compute_loss(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram):
# 分别计算内容损失、风格损失和全变分损失
contents_l = [content_loss(Y_hat, Y) * content_weight for Y_hat, Y in zip(
contents_Y_hat, contents_Y)]
styles_l = [style_loss(Y_hat, Y) * style_weight for Y_hat, Y in zip(
styles_Y_hat, styles_Y_gram)]
tv_l = tv_loss(X) * tv_weight
# 对所有损失求和
l = sum(10 * styles_l + contents_l + [tv_l])
return contents_l, styles_l, tv_l, l
请问这里 l = sum(10 * styles_l + contents_l + [tv_l]) 为什么要乘10, 将style_weight*10 可以吗
have the same question
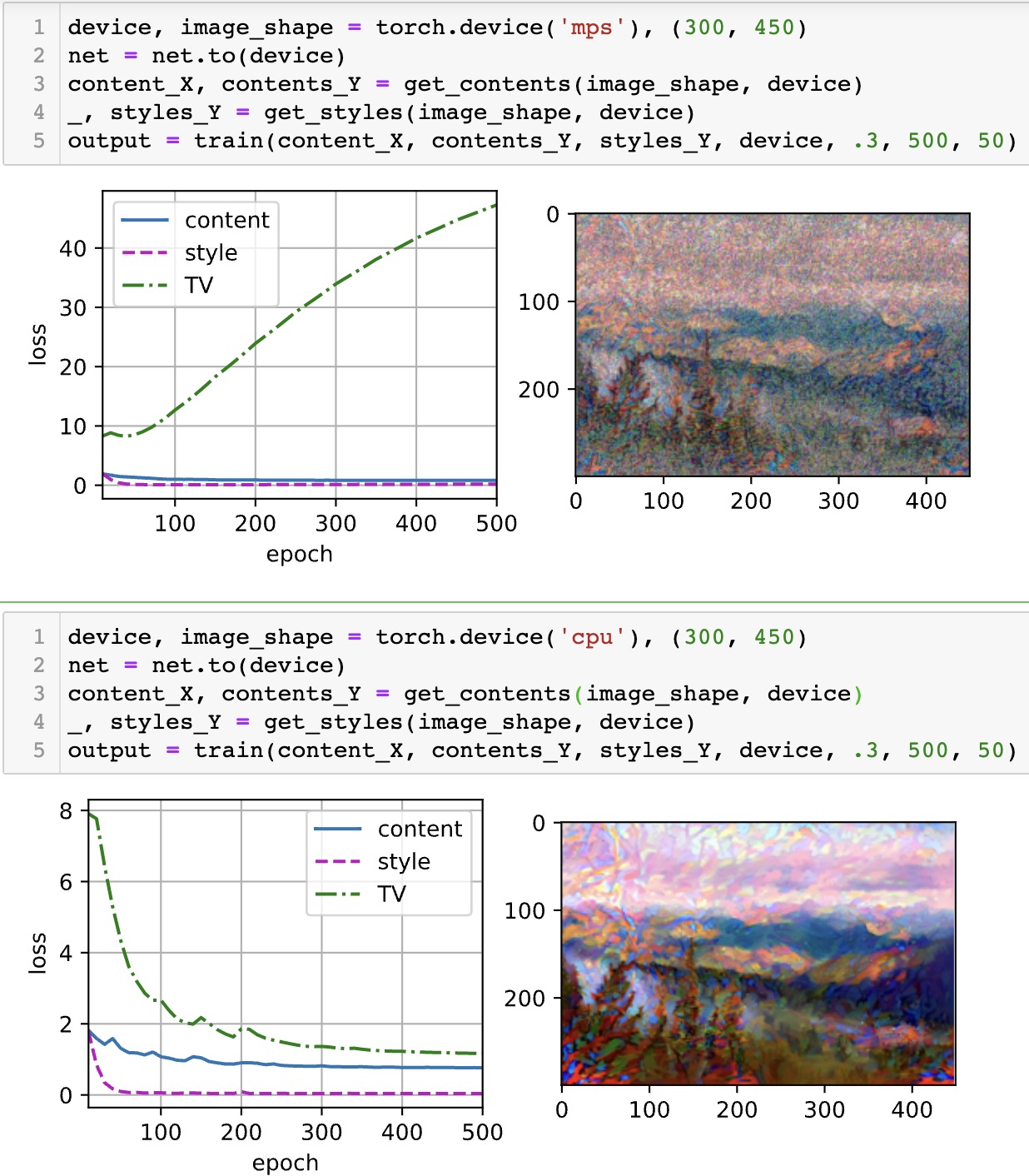
看样子你是没有清空输出就直接跑了,看style content loss的值,感觉是再跑完cpu后接着跑mps的,相当于网络没有清空参数继续训练了500个epoch,你看tv loss反而开始上升了,就感觉是过拟合了
我和你一样问题,感觉是pytorch在m1的gpu芯片上有不少bug。
为什么我初始化合成图像以后,为什么第一轮epoch的内容损失是0?


