https://zh-v2.d2l.ai/chapter_computer-vision/semantic-segmentation-and-dataset.html
module ‘torchvision’ has no attribute ‘io’,代码错误怎么解决?
您好,在图像标准化时,我们使用的 mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],这样会导致标准化后图像的像素非常大,这样做还能达到标准化的目的吗?比如,这是我打印的某个图像B通道的像素值:
[[ 548.1004, 556.8340, 530.6332, …, 565.5677, 268.6245,
155.0873],
[ 373.4279, 382.1616, 395.2620, …, 1015.3493, 823.2096,
600.5022],
[ 386.5284, 377.7947, 369.0611, …, 1093.9519, 1085.2184,
1076.4847],
…,
[ 535.0000, 508.7991, 294.8253, …, 155.0873, 172.5546,
181.2882],
[ 696.5720, 617.9694, 355.9607, …, 238.0568, 211.8559,
190.0218],
[ 539.3668, 600.5022, 316.6594, …, 146.3537, 128.8865,
137.6201]]
torch的代码里好像缺少了图像归一化的过程,导致最终的收敛结果不太好。解决方案是 在数据类的归一化过程中手动将图像从 [0, 255] 调整到 [0, 1]: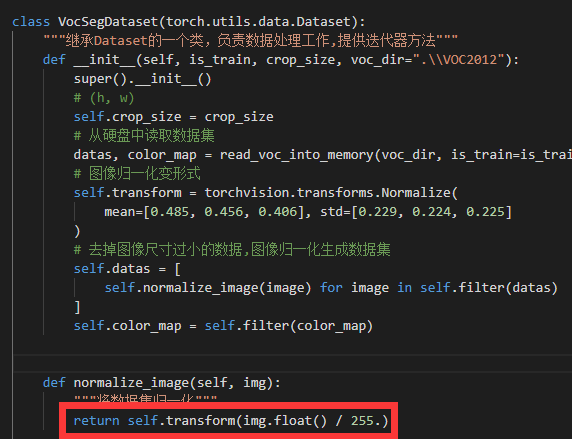
2 Likes
Thanks for pointing this bug. We’ll fix it in master now.
您好,我在使用DataLoader读取voc_train时,陷入无限读取状态(近1小时也没有读取完)。 请问对于这个问题有什么办法么?
环境为python 3.9.10,PyTorch 1.11.0
1 Like
应该是设置的通道数有问题
把通道数改成0就好了
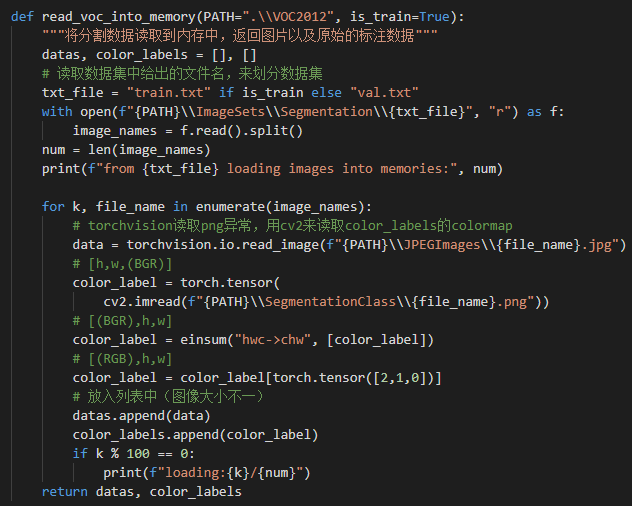
有没有大佬解释下(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]是个什么算法 ![]() 有点没懂 1维的RGB值*256加上二维RGB值的和乘256再加三维的RGB值。就是自己定义的一个转换算法是吗
有点没懂 1维的RGB值*256加上二维RGB值的和乘256再加三维的RGB值。就是自己定义的一个转换算法是吗
应该是的,为了进行RGB->index的转换,最终得到一个RGB->index的映射表
train_iter = torch.utils.data.DataLoader(voc_train, batch_size, shuffle=True,
drop_last=True,
num_workers=d2l.get_dataloader_workers())
for X, Y in train_iter:
print(X.shape)
print(Y.shape)
break
以上这组代码我运行了几个小时也没有运行完输出,请问真的需要很久吗?
参考进制转换。二进制转十进制,八进制转十进制,类比256进制转十进制
1 Like
Traceback (most recent call last):
File “D:/muli/maokuang1.py”, line 6, in
d2l.DATA_HUB[‘voc2012’] = (d2l.DATA_URL + ‘VOCtrainval_11-May-2012.tar’,
AttributeError: module ‘torch’ has no attribute ‘DATA_URL’
大家有遇到这个问题吗 请问如何解决
Did you solve it? It keeps running, is the data reading too slow? Can you tell me how to fix this?
相当于建立了一个RGB三元组到一个正整数的一一对应
如果是Windows环境的话,尝试把多进程关掉读取数据集
把num_workers这项参数去掉就可以了,不需要多线程读取。
1 Like
read_voc_images函数里的for循环中的索引 i 似乎没用,故enumerate是不是多余的呢?
不论是按照老师的代码下载数据集还是到数据集官网上进行下载,下载的速度都很慢,请问有什么提升下载速度的办法吗?
用colab,在线下载很快。一定要下载到本地就配置代理端口。