“我们以图像的每个像素为中心生成不同形状的锚框: 比例 为 s∈(0,1], 宽高比 (宽高比)为 r>0。”
这里“比例s”是指宽和高(单个方向)的scale系数(即锚框面积是总面积的s^2倍),“宽高比r"指原图片宽高比的scale系数,对吧?不然无法推出后文写的锚框的宽和高。
我仔细钻研推理了宽高比r的意义和multibox_prior函数,r还是应该是锚框自己的宽高比(这样r才能直接从锚框本身的形状中体现)。
原文
那么锚框的宽度和高度分别是 w * s * sqrt(r)和 h * s / sqrt(r)
是不对的,应该改成
那么锚框的宽度和高度分别是 s * sqrt(w * h * r)和 s * sqrt(w * h / r)
multibox_prior函数的代码中,
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),sizes[0] * torch.sqrt(ratio_tensor[1:]))) * in_height / in_width
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]), sizes[0] / torch.sqrt(ratio_tensor[1:])))
应该是不对的。不管对s和r是何种解读,这里的w的计算都是说不通的。按照" r是锚框自身的宽高比 ”的解读的话,w和h的计算应该如下:
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]), sizes[0] * torch.sqrt(ratio_tensor[1:])))
* math.sqrt(in_height / in_width)
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]), sizes[0] / torch.sqrt(ratio_tensor[1:])))
* math.sqrt(in_width / in_height)
我是非常仔细地看了multibox_prior函数的code。有其他看法的小伙伴欢迎回复我啊~
函数 assign_anchor_to_bbox 中的两个0.5应该换成input argument “iou_threshold”?
另外这个函数名字其实不对,应该是“assign_gtbbx_to_anchor"更合适些
这块我也看了,发现代码的实际逻辑和他的公式不符合,我觉得公式应该是这样的:
a_w = hs * sqrt(r)
a_h = hs / sqrt(r)
a_w / a_h = r
a_w * a_h = h^2 * s^2
可以用这段代码验证:
boxes = Y.view(h, w, 5, 4)
a = boxes[250, 250, 0, :]
print(a)
top_left = a[:2]
down_right = a[2:]
print(top_left, down_right)
a_w = down_right[0] - top_left[0]
a_h = down_right[1] - top_left[1]
print(a_w, a_h)
# a_w / a_h == r
print((a_w * w) / (a_h * h))
# a_w * a_h == h^2 * s^2
print((a_w * w) * (a_h * h), h * h * 0.75 * 0.75)嗯嗯,你是从代码推公式,我能看出你的推断是对的,因为锚框的面积a_w * a_h,居然只跟h和s有关,h^2*s^2,从代码看是这样的。
我就是觉得这里代码错了。锚框的面积和原图片的宽width居然无关吗?这显然不合理。
嗯,其实我觉得 a_w 应该用 ws * sqrt(r) 来算的,这样的话结果就跟 w 和 h 都是有关的了,另外,沐神在讲课的时候说 s 开个根号可能是他的本意,他这里可能也写错了。
不过,这些预处理对最终的预测影响应该不大,反正能够生成不同的锚框就好啦~
感觉这一节真的好难,代码细节要看好久,还没完全看懂呜呜呜  不知道有没有人能详细讲下代码细节~
不知道有没有人能详细讲下代码细节~
个人觉得没有问题吧, w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))
* in_height / in_width # Handle rectangular inputs
。w,h在上边的代码里进行归一化了(steps_h = 1.0 / in_height)。所以公式里的w,h没有了。代码中的in_height / in_width是为了生成边界框的比例与输入图像比例保持一致,比如输入图像是1000100的话,生成的锚框也该是这个比例的。
s是对宽和高的单独放缩,总面积应该是放缩到s^2,r是对于原来的高宽比的放缩,例如原来的高宽比是h/w,添加r后变成了(h/w)*r,我觉得有问题的是这一段代码:
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # Handle rectangular inputs
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
对于w它 * in_height / in_width,我觉得是不需要的,代码的目的就是为了得到框框的左上和右下的坐标,正常的逻辑就是:
左上:(center_x-w*s*sqrt(r)/2,center_y-h*s/sqrt(r)/2)
右下:(center_x+w*s*sqrt(r)/2,center_y+h*s/sqrt(r)/2)
对于x坐标除以w,对于y坐标除以h得:
左上:(center_x/w-s*sqrt(r)/2,center_y/h-s/sqrt(r)/2)
右下:(center_x/w+s*sqrt(r)/2,center_y/h+s/sqrt(r)/2)
而out_grid代码的就是每个像素的中心点(高和宽都是用1.0 / in_height 和steps_w = 1.0 / in_width归一化处理过的 )存的就是center_x/w,center_y/h,所以将 * in_height / in_width 去掉就行:
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
这样经过除以2的处理:
anchor_manipulations = torch.stack(
(-w, -h, w, h)).T.repeat(in_height * in_width, 1) / 2
anchor_manipulations 得到了真正的归一化的偏移量
然后通过乘以bbox_scale=torch.tensor((w, h, w, h)),再将高宽放缩到原来的真实值
如果有什么问题欢迎讨论!
其他都懂了就是这
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),sizes[0] * torch.sqrt(ratio_tensor[1:])))* in_height / in_width到底为什么* in_height / in_width
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h 这里出来的是1,3,5,7…的1d tensor. 但不是每个pixel都是中心吗?为什么会跳一个pixel啊
S就是Size, 即锚框大小占输入图片大小的比率,比如size=0.5, 即输入图像的一半。
r的解释稍有不准,原文说是“宽高比”, 锚框的宽度和高度分别是 wsr√wsr 和 hs/r√hs/r
实际上,r=1时,锚框的宽高比等于原始输入图像的宽高比,即相似形。当r>1时,锚框的宽高比是原始图片宽高比的r倍,即更宽更扁了。而当r<1时,锚框变得更加细长,不管它叫什么了,根据公式来就对了。
1、matplotlib在生成图像的时候,X轴和Y轴坐标的刻度不是一致的,所以s值为X、Y两个轴的比例;
2、h_a * w_a = sshw
w_a/h_a = r
解二元方程组 h_a = s/sqrt(rhw)、w_a = ssqrt(rhw)
由于代码中center_w和center_w已经归一化,hw=1,所以方程结果为h_a = s / sqrt® , w_a = s * sqrt®
3、由于X,Y坐标轴刻度不一致,为了锚框宽高比和视觉一致, w_a = s * sqrt® * h / w
r是指锚框的宽高比与图像的宽高比之比即w’/h’ = w/h*r,s是图像尺寸缩放因子即w’h’=whs^2,联立求解即可得文中的锚框宽高即w’=ws×sqrt( r ),h’=hs/sqrt( r )。
在程序中,由于锚框中心坐标已经沿图像宽高进行归一化,为了得到锚框左上和右下的坐标,也需要对求得的锚框宽高进行归一化以便进行加减即w’’ = w’/w=s×sqrt( r )和h’’ = h’/h=s/sqrt( r ),也就是说程序函数输出的是锚框两点实际坐标与图像宽高之比。
想请问一下在multibox_detection()函数中,为什么要有conf[below_min_idx] = 1 - conf[below_min_idx]这样一句话呢?希望有大佬可以解答一下
我觉得这个是正确的。沐神课QA里面说s应该放进根号里面,所以:
宽度和高度分别是 $$w\sqrt s\sqrt{r}$ 和 $h\sqrt s/\sqrt{r}$$
给生成锚框的代码简单写了个注释,希望指正
# 此函数中,ratio为锚框的真实宽高比
# data: (batch_size, num_channels, height, width)
def multibox_prior(data, sizes, ratios):
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
size_ratio = torch.tensor(ratio, device=device)
offset_h, offset_w = 0.5, 0.5
step_h = 1.0 / in_height
step_w = 1.0 / in_width
# (center_h, center_w): 每个锚框缩放后的中心点的坐标
center_h = (torch.arange(in_height, device=device) + offset_h) * step_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
# center_h = tensor([1, 2, 3, 4])
# center_w = tensor([1, 2, 3])
#
# shift_y = tensor([[1, 1, 1], 即在第0维叠加
# [2, 2, 2],
# [3, 3, 3],
# [4, 4, 4]])
# shift_x = tensor([[1, 2, 3], 即在第1维叠加
# [1, 2, 3],
# [1, 2, 3],
# [1, 2, 3]])
# shift_x = [1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3] ^ T
# shift_y = [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4] ^ T
# (shift_x, shift_y) 即是全部点的坐标
shift_y, shift_x = torch.meshgrid(center_h, center_w)
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 由于ratio为真实比例,因此当 ratio=1 时,应满足 w=h,故要乘以 in_height / in_width
# 又由于上面的 shift_x 和 shift_y 已经缩放到 [0,1] 范围,
# 因此这里不用乘以 in_width 和 in_height
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 每一行对应一个锚框的左上角偏差和右下角偏差
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每一行对应锚框的中心点重复两次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
# 加起来之后,就是锚框左上和右下的真实坐标
output = out_grid + anchor_manipulations
# 第一维是批量大小,要生成这一维
return output.unsqueeze(0)
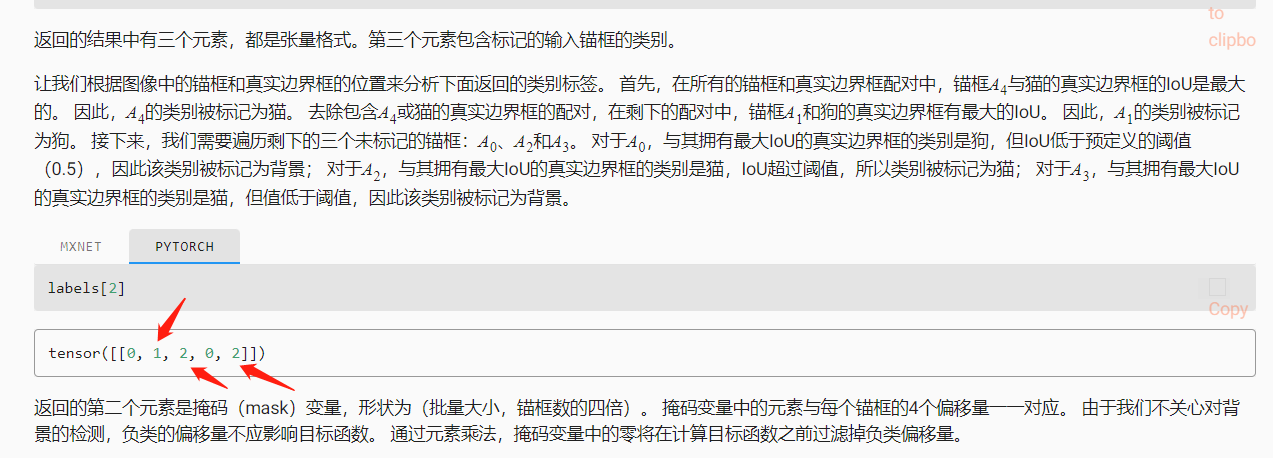
难道这两个判定为猫的锚框和真实边框之间的交并比值是相同的嘛??
我研究了一下代码,sizes比例的公式应该是s^2=(wh)/(HH)。ratios的公式是r=w/h,其中w,h是锚框的宽高,W,H是图像的宽高。这样w=Hsr^0.5,h=H*s/r^0.5。 所以s^2并不是严格的面积比,只有当H=W时才是。
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
这个太巧妙了,Python 太魔法了