http://zh.d2l.ai/chapter_recurrent-modern/machine-translation-and-dataset.html
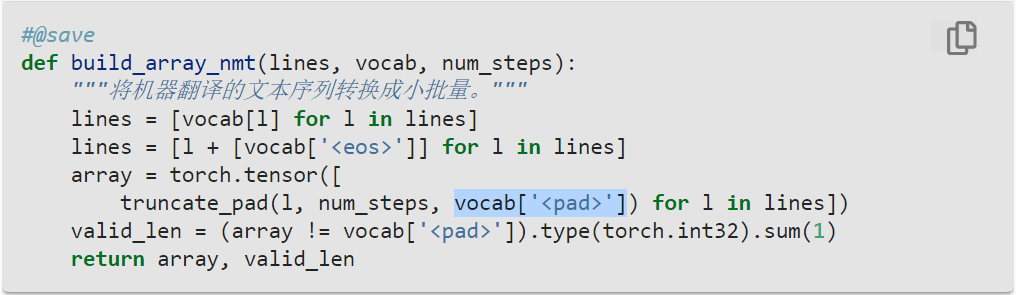
很明显,pad的优先级要高于eos,即遇到了pad自然就知道已经EOS了。
试了下代码 如果长度超过num_steps 就会把EOS删掉。
但是序列长度 就没有超过8的
如果超过8的数据都截断,后面的信息就不考虑了吗?
词元化函数tokenize_nmt(text, num_examples=None)中,num_examples所指定的样本数量有些略微的差别,比如在load_data_nmt()中,指定num_examples=600,则tokenize_nmt返回的source 和 target长度为601,这是由于enumerate函数默认start=0引起的,只需要将for i, line in enumerate(text.split(’\n’)):这一行改为for i, line in enumerate(text.split(’\n’), start=1):即可。
1 Like
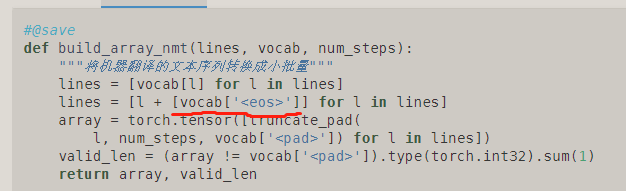
对于源序列,这个是不是不需要加!!!
应该搞反了吧吧吧吧吧吧吧吧吧吧。。。。。。。。。
另外这样反复truncate可能把原来的有用信息抛弃,影响精度。
想法是:可以先对source按序列长度排序(相当于shuffle了),这样每个batch取邻近的小块。而num_steps取小块内最长的,这样 就避免信息丢失。
1 Like