https://zh.d2l.ai/chapter_recurrent-neural-networks/rnn-concise.html
1 Like
请问RNNModel类,begin_state函数中的注释nn.GRU 以张量作为隐藏状态、 # nn.LSTM 以张量作为隐藏状态,怎么理解?
我觉得是写错了, nn.LSTM和自己手写的都是以元组 (H,) 作为返回
1 Like
请问, 循环神经网络的简洁实现的输出层代码
output = self.linear(Y.reshape((-1, Y.shape[-1])))
是在哪里计算的啊
这里用的就是pytorch自带的 torch.nn. Linear吧
我在看里面的参数时,发现这个rnn中有4个参数,两个weight权重,两个bias,按照前面讲的,在rnn中不应该只有一个Wxh,一个Whh还有一个bias吗,另外在输出层才有另外的bias啊?help me please
1 Like
这些参数都是要优化算法学习的参数,你可以使用rnn.state_dict()查看这些参数。使用的时候仅仅输入相应的维度即可。
1 Like
源码写了Second bias vector included for CuDNN compatibility. Only one bias vector is needed in standard definition.
3 Likes
发现不可以用softmax欸,一旦用softmax,loss就会卡住不动,然后生成的全是类1,也就是空格,有没有大佬知道为什么,我这个大冤种今天卡了一整天就是因为这个
是不是用的functional里的softmax,然后dim写错了?
在训练途中batch size是每次训练样本大效,num_steps是句子长度,在训练过程中是否使用了全部样本呢。
state = torch.zeros((1, batch_size, num_hiddens))
这里初始化隐状态为0,反向传播计算梯度的时候不会导致更新值一直为0的情况吗?
是在 loss 前加了一层 softmax 实现吗,好像这里用的余弦交叉熵自带 softmax;我也不确定是不是这个问题。CrossEntropyLoss — PyTorch 2.0 documentation
因为这个子类继承了其父类的module的属性,所以self.linear就是nn.linear吧,我是这样理解的
GRU 没有像 LSTM 那样的细胞状态(cell state),它只有一个隐藏状态,LSTM有两个, torch.zeros 分别初始化这两个张量,并将它们组合成一个元组。
X = torch.rand(size=(num_steps, batch_size, len(vocab)))为什么不是batch_size作为第一维度吗
你好,
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
这里的备注是不是应该写成 # nn.RNN、nn.GRU以张量作为隐状态
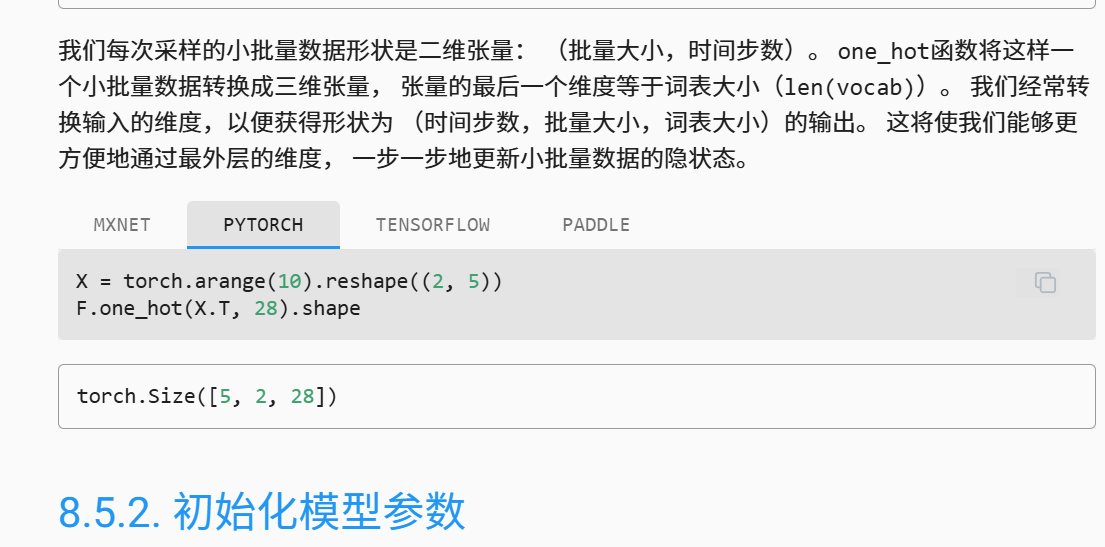
self.linear 是实例化的一个 全连接层,输入维度为hiddens,输出维度为词向量大小,这里是直接转换成全连接层要求的二维张量,且维度1上的神经元数跟hidden是性相同,然后就输出啦
请问为什么predict_ch8的预热过程中是把prefix的一个个字符依次送给网络而不是一个完整的纯存在vocab中的单词元?
还有每次训练时要把state给detach掉的目的是什么,不进行此操作会怎么样?