因为Pytorch对Apple M1芯片的支持的问题,此处的代码直接在使用m1芯片的mac上是无法直接运行的。原因在于torch.argmax()这个函数,运行时会产生一个“-9xxxxxxx”的错误值,可替代的改法是使用torch.max()函数,例如“_,y=y.max(地面=1)”。这个问题在全书多处地方出现,所有使用了argmax()函数的地方都有可能出现。是不是应该指出一下?
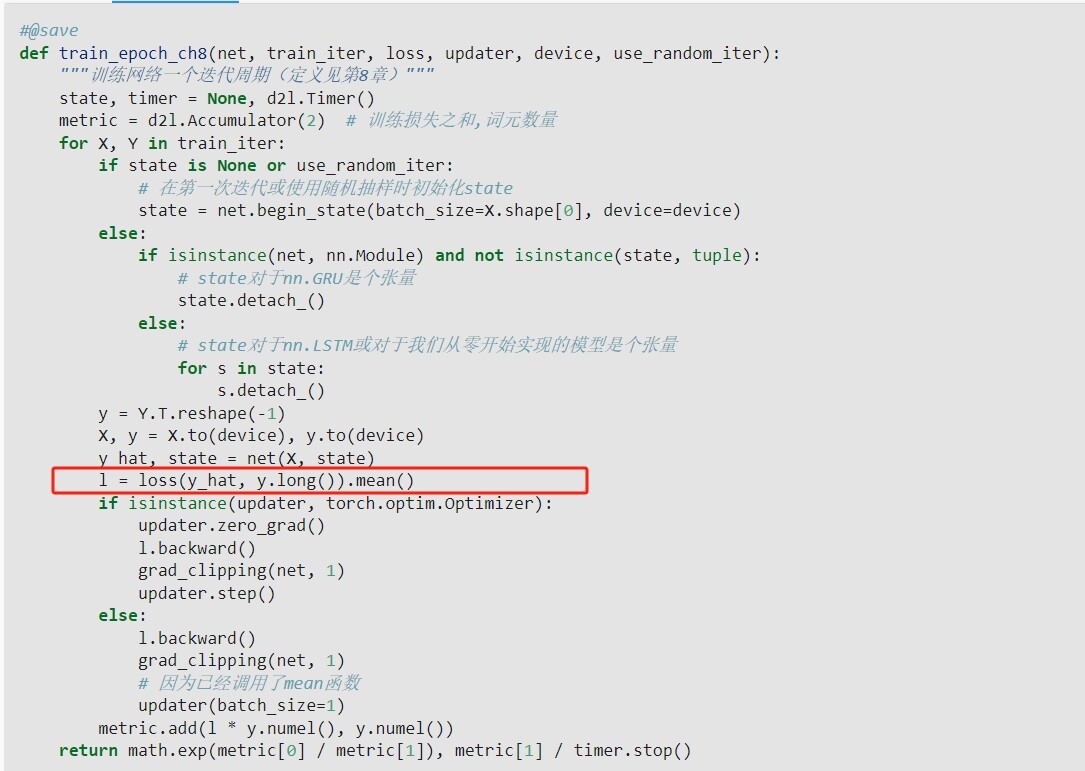
图中的 .mean( ) 不用加,因为下图中建立 loss= nn.CrossEntropyLoss(),默认的就是用 reduction=‘mean’,这将会在求交叉熵时,自动求批量里的每个输出与对应标签的交叉熵的平均值。当然,在此文中y_hat与y的每一行代表的是 时间步数*样本数目,且他们的排列是按照:同一批次里不同样本的同一时间步挨着,比如:一个批次有10个样本,每个样本有时间步5,那么y_hat与y的每行依次是 样本1 ,时间步1 ,样本2, 时间步1…样本9 ,时间步5,样本10 ,时间步5
要求Whh的梯度啊,你地知道Whh变化的快慢,然后才能修正Whh啊,你求state梯度有啥用,你知道state变化快慢,下一步是用他的梯度修正state?求谁的梯度,就是求谁的变化快慢的衡量指标,然后用他变化快慢的这个程度去修正他自己的值
如果输入和输出的行数都不一样,应该怎么做呢。我知道列数不同的时候可以怎么做
交叉熵损失函数会自动把y展成onehot形式
在梯度剪裁的代码里,居然是将每个参数梯度的平方和直接累加在一起,最后统一开根号。
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
我以为应该是对每个参数梯度的平方和独立开根号,然后各自与θ进行对比和进行约束缩放。。
那么这样做是合理的吗?
请教一下 8.5.5 节讲李普希兹连续有什么必要吗?李普希兹连续和梯度裁剪有啥关系?这一段读的我云里雾里,感觉前后无关。
我猜他的意思是
这里用不用随机采样数据集都没多大差别,随机情况下每一个batch训练前将隐状态置0,不会记录上一个batch信息,所以跟batch顺序与否没关系
这里大家要注意了,如果你的get_params函数里面的normal成员函数里最后的那个0.01不乘的话,训练就会失败,损失会非常非常高。这可能再次说明了参数初始化的重要性,并且SGD受参数初始化的影响还是很大的。
在d2l库中,找不到d2l.load_data_time_machine(batch_size, num_steps),这个是什么原因?
1 Like
我觉得你是对的,仔细翻阅文档,在不指定reduction=none的情况下,返还的就是scalar
同样的问题,d2l库里好像少了好几个函数