https://zh.d2l.ai/chapter_recurrent-neural-networks/rnn-scratch.html
1 Like
-
在不裁剪梯度的情况下运行本节中的代码。会发生什么事?
-
我试着把train_epoch_ch8里的gradient_clip函数打成注释,并打印loss,好像loss没有明显的暴增,最后的困惑度也在1左右。这是正常现象吗?
函数train_epoch_ch8中,当updater非optimizer实例时,为什么updater(batch_size=1),这里的batch_size不应该为X.shape[0]吗。
这里批次数据等于1是因为d2l.sgd函数中对步长使用batch_size进行了归一化,也就是说d2l.sgd函数当初是针对没有平均的目标函数使用的,由batch_size长度的全体loss.sum()当然要在梯度更新的时候除以batch_size,如果是nn.CrossEntropyLoss()就已经平均过的loss值就没必要再除掉batch_size,所以设置为1。当然,这里又加了mean()操作可能是怕目标函数没有平均,保个险。在我看来如果是nn.CrossEntropyLoss()的话就没必要再mean了
2 Likes
为什么对state进行了detach,难道不需要对状态相关的参数矩阵如Whh等进行更新吗
我认为在每次新的输入进去进行计算时,产生了新的计算图,此时隐状态又加到新的计算图里面了,就可以正常基色梯度了。之所以将每次输入产生的最后一个隐状态detach掉,是为了不将它从前一次的计算图中继续向下分支,这样的话反向传播时会计算到前一次的输入,这样计算变得复杂。detach之后每次的梯度计算都集中在该次小批量的输入中,计算会快一点。
4 Likes
请问在后面的updater.zero_grad()里不会自动把梯度清0,然后在loss.backward里自动释放了当前计算图吗?(我是查资料了解到的)如果会的话那为什么还要人为detach掉后面会被释放的计算图呢?
也就是我们常说的梯度爆炸吧,我的理解就是因为梯度不裁剪,会一点点累积,从而导致指数级增长
请问在预测前的预热次数与最终输入模型的隐状态之间有什么关系呢?是预热的次数越多越好吗?
去掉梯度裁剪后,训练时,困惑度指标抖动剧烈。
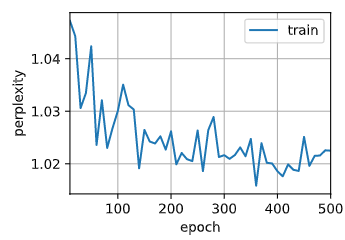
1 Like
每次backward都要清0的,不然就相当于全部序列的梯度计算叠加在一起。backward不是释放计算图吧?它是反向求梯度。detach的是state,因为只需要前一个state传到后一个序列就可以让他们断(detach掉)了,不需要让前后state链一直连着,这样会增大计算量。
1 Like
预热应该就是把序列信息提前加入隐状态,预测次数应该适中就行
1 Like
在train_epoch_ch8函数中,我发现shape of y是(num_steps * batch_size),但是shape of y_hat是(num_steps * batch_size, len(vocab)),在这个前提下,直接使用loss(y, y_hat)应该不行吧?
3 Likes

net没有重新初始化吧…(为什么回复必须得20字以上?!)
1 Like
顺序分区时,后期会梯度爆炸的,随机采样的不会

这里的use_random_iter虽然是True, 但是之前的train_iter定义的时候调用的load_time_machine没有指定use_random_iter参数,这是不是意味着实际上并没有使用随机采样?是否需要重新定义train_iter?
1 Like
我觉得也是,最后一段代码要用随机抽样的话应该要这样才对:
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps, use_random_iter=True)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),
use_random_iter=True)
1 Like
这样算不算部分更新weights,即不是精确计算