这个用法是怎么得知的,我看官方文档也没有这种用法
大佬牛逼!!所以正则化方式,lambda的取值在贝叶斯统计上相当于对w的先验分布的分布方式及对应参数的选择 ![]()
特地注册账号回复,好人一生平安 ![]()
![]()
![]()
![]()
![]()
![]()
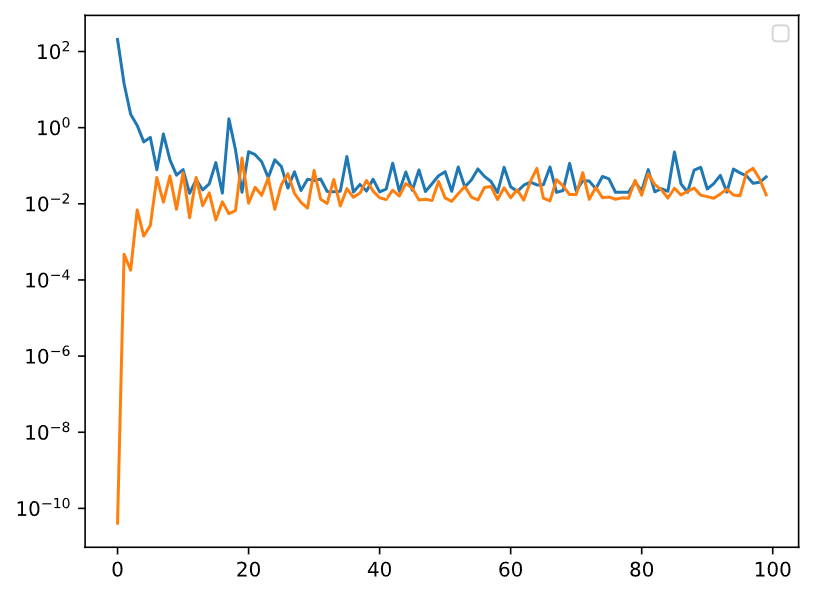
为什么我的weight_decay只要不为0,训练和测试的误差曲线就出现震荡而不是减少?
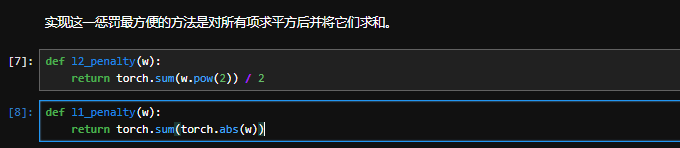
平方范数 = 标准范数^2,个人认为
1111111111
为什么不直接调整lr变化呢,调整lr和权重衰退两种方法有什么区别呢
你好,这是我写的代码,希望能对你有所帮助,我也是新手,希望不会误导你
def train_(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1)) # define net
for param in net.parameters(): # initialize parameters
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
return wd, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss))
def draw(wds):
animator = d2l.Animator(xlabel='lambd', ylabel='loss', yscale='log',
legend=['train', 'test'])
for wd in wds:
wd, loss = train_(wd)
animator.add(wd, loss)
wds = range(0, 100, 10)
draw(wds)
在权重衰减的两个版本的实现中,为什么《从头开始》的loss反向传播时使用的是l.sum().backward; 而使用框架自带的MSELoss计算得到的loss反向传播时使用的是l.mean().backward呢;在什么情况下应该使用sum(),什么情况下应该使用mean()呢
1 Like
从零版的Loss(包括本身的squared error和L2惩罚)乘了1/2系数;简洁版没有。我尝试把简洁版乘上这个系数,结果没啥变化,还是跟从零版结果差异明显。怀疑是trainer.step()方法跟自定义的d2l.sgd()执行上有差异。

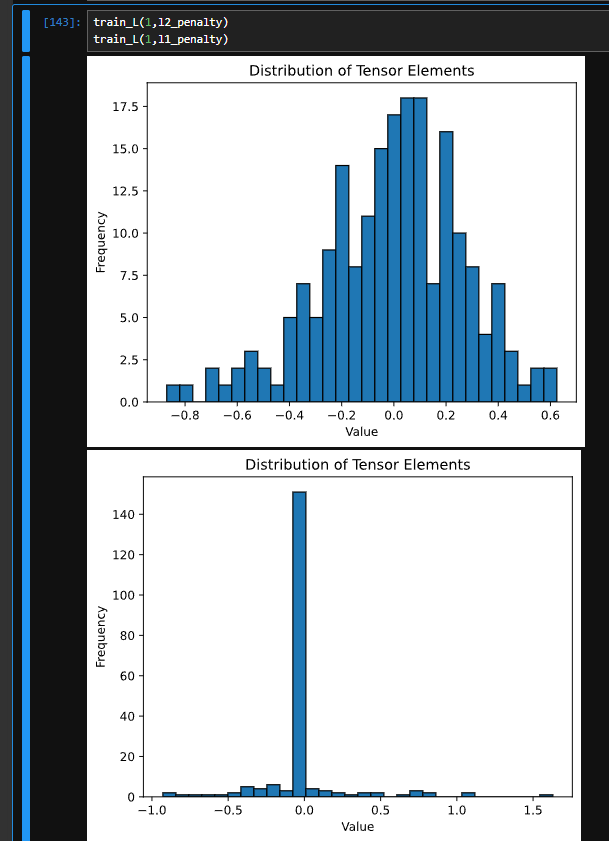
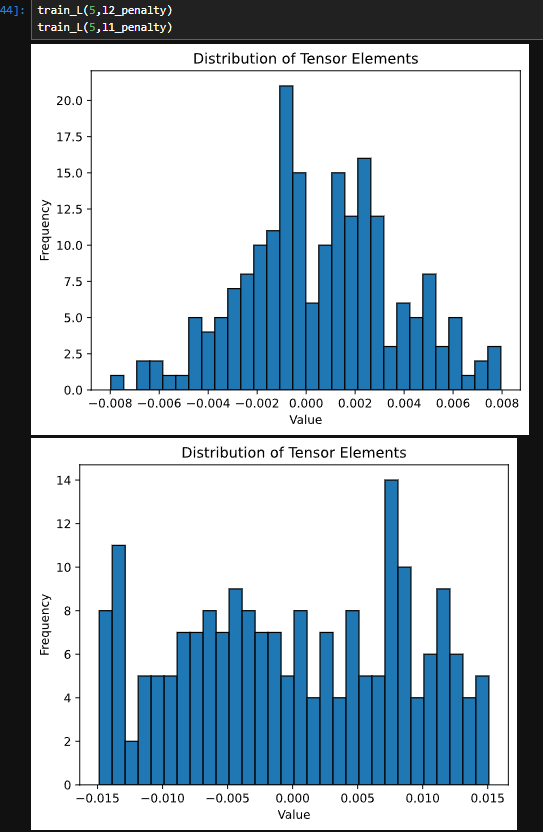
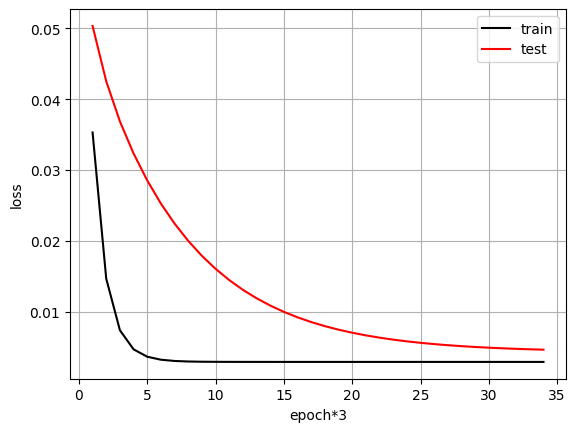
不知道为什么我的学习的特快,学习率已经调成0.0001了,不知道这样正不正常 ![]()
No1 question:
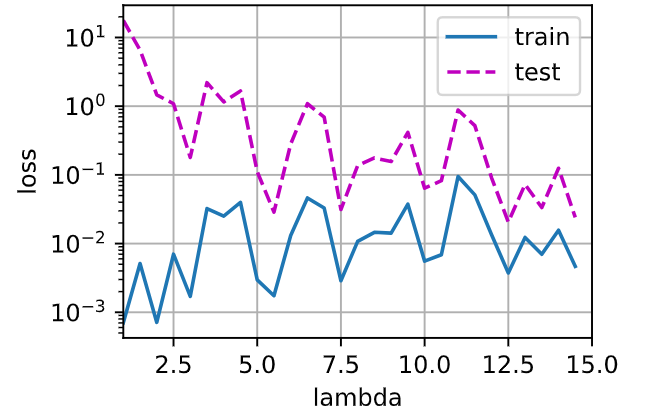
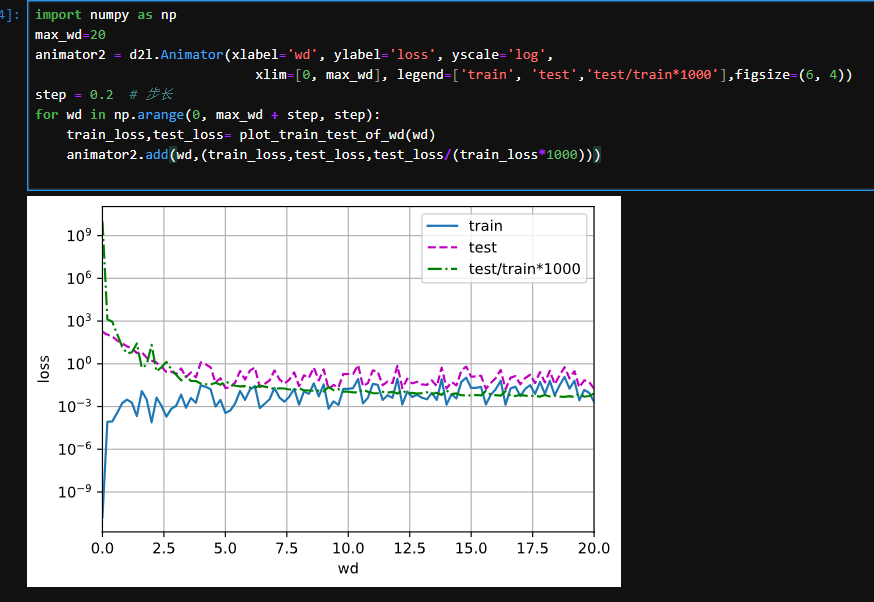
这里是验证了lamba从1到20的变化对结果的影响
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
return d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)
# 不同lamba值的影响
animator = d2l.Animator(xlabel='wds', ylabel='loss', yscale='log',
xlim=[1, 20], legend=['train', 'test'])
for i in range(20):
train_loss, test_loss = train_concise(i)
animator.add(i+1,(train_loss,test_loss))
plt.show()
print('ok')
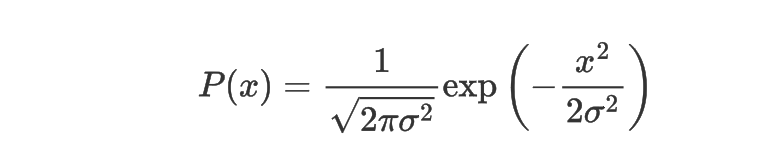
def synthetic_data(w, b, num_examples):
“”"Generate y = Xw + b + noise.
Defined in :numref:`sec_linear_scratch`"""
X = d2l.normal(0, 1, (num_examples, len(w)))
y = d2l.matmul(X, w) + b
y += d2l.normal(0, 0.01, y.shape)
return X, d2l.reshape(y, (-1, 1))
数据是一个正态分布的,并不是一条直线,所以一定会过拟合
其实每次跑结果都不太一样,这也不会是最优解
def train_concise_flambd(wd):
num_epochs,lr = 100,0.003
net = nn.Sequential(
nn.Linear(num_inputs,1)
)
#神经网络参数初始化
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD([{"params":net[0].weight,"weight_decay":wd},
{"params":net[0].bias}],lr=lr)
for epoch in range(num_epochs):
for X,y in train_iter:
trainer.zero_grad()
l = loss(net(X),y)
l.mean().backward()
trainer.step()
return d2l.evaluate_loss(net,train_iter,loss),d2l.evaluate_loss(net,test_iter,loss)
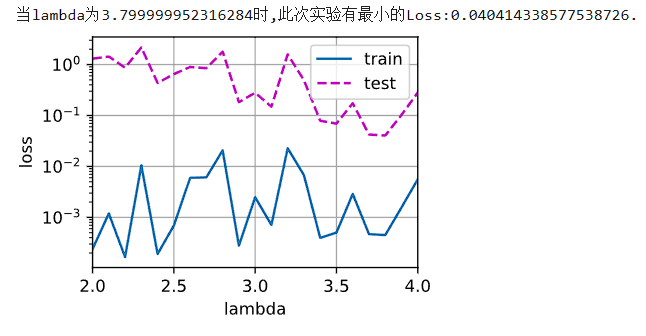
def run():
testLoss = []
wd_min = 2
temp_loss = float('inf')
animator_f = d2l.Animator(xlabel='lambda',ylabel='loss',
yscale='log',xlim=[2,4],legend=['train','test'])
for wd in torch.arange(2,4.1,0.1):
train_loss,test_loss = train_concise_flambd(wd.item())
testLoss.append(test_loss)
if test_loss < temp_loss:
temp_loss = test_loss
wd_min = wd
animator_f.add(wd.item(),(train_loss,test_loss))
return min(testLoss),wd_min
min_test_loss,idx = run()
print(f"当lambda为{idx}时,此次实验有最小的Loss:{min_test_loss}.")
def l1_penalty(w):
return torch.norm(w,p=1)
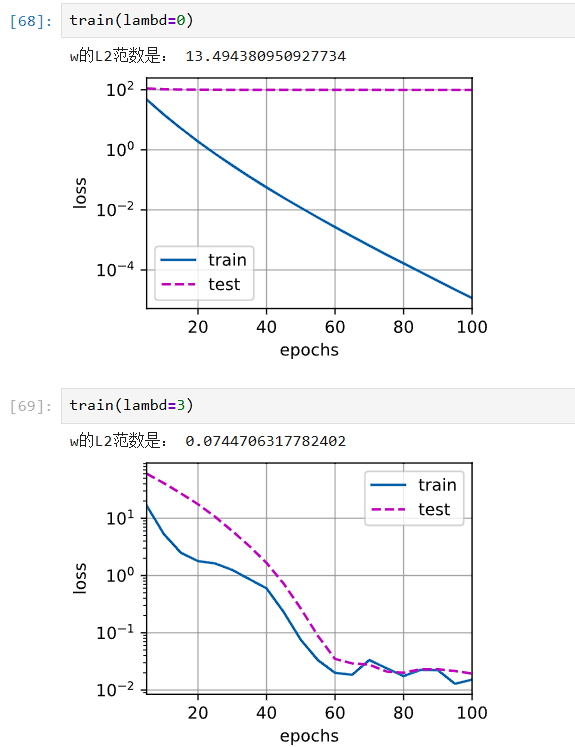
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
# 增加了L2范数惩罚项,
# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量
l = loss(net(X), y) + lambd * l1_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())