你好,tensor张量区分应该是没有区分行向量和列 向量的吧。
a = torch.tensor([1,2])
a,a.T
(tensor([1, 2]), tensor([1, 2]))
你好,tensor张量区分应该是没有区分行向量和列 向量的吧。
a = torch.tensor([1,2])
a,a.T
(tensor([1, 2]), tensor([1, 2]))
直接使用linreg可以,赋值给net变量,可能是约定俗成。因为后面的net大家都会默认当作是一个模型(模型容器),这样就不仅单指一个线性回归模型了吧
貌似之所以在后面除是有一个trick在的,在实际应用中,sklearn包有个类似的操作都是在后面除的,可以加速计算,但是具体为什么我忘记了。但是好像pytorch更新之后直接在loss这里进行均值了而不用在后面做了,所以确实在损失这里求平均便于理解。
至于l l.sum() l.mean()各种形式混乱,一个是因为书上文档的更新和代码库不一致,阅读起来和实践起来有出入;
一个是用d2l里的sgd是后除batch_size,前面loss就要求和,而用了torch里的sgd就又不用了;
然后还有就是写书期间torch里crossentropyloss里面变成了默认取均值。
种种变化和不一致,就让l的形式非常混乱。但是搞清楚loss的形式以及sgd需求的形式,一一对应处理就好,不必纠结形式。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f’epoch {epoch + 1}, loss {float(train_l.mean()):f}’)
为何再次运行后loss就固定不变了
epoch 1, loss 0.000050
epoch 2, loss 0.000050
epoch 3, loss 0.000050
ImportError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/IPython/core/formatters.py in call(self, obj)
332 pass
333 else:
→ 334 return printer(obj)
335 # Finally look for special method names
336 method = get_real_method(obj, self.print_method)
12 frames
/usr/local/lib/python3.7/dist-packages/matplotlib/backends/backend_svg.py in ()
16 import matplotlib as mpl
17 from matplotlib import _api, cbook, font_manager as fm
—> 18 from matplotlib.backend_bases import (
19 _Backend, _check_savefig_extra_args, FigureCanvasBase, FigureManagerBase,
20 RendererBase)
ImportError: cannot import name ‘_check_savefig_extra_args’ from ‘matplotlib.backend_bases’ (/usr/local/lib/python3.7/dist-packages/matplotlib/backend_bases.py)
因为他已经训练到一个符合要求的水准了,除非你重置一下w和b
#初始化参数权重w,偏置b=0
w=torch.normal(0,0.01,size=(2,1),requires_grad=True)
b=torch.zeros(1,requires_grad=True)
你好,我也遇到了这个问题,请问是怎么解决的呀?
我觉得就是重命名一个接口把,net指代一切算法,这样你训练的代码就不用调整了,只要把net指向对应的算法即可
因为python的机制不用于C的函数传参,python传进去的是参数本身也可以说是C++中参数的引用,因此在函数中对参数进行操作会影响函数域外的变量
运行如下代码来检验
class Tes(object):
def __init__(self):
self.num = 10
pass
pass
def func(inc: Tes) -> Tes:
inc.num += 10
print(id(inc))
return inc
def func2(inc):
inc += 10
print(id(inc))
return inc
a1 = Tes()
print(id(a1))
a2 = func(a1)
print(id(a2) == id(a1)) #此输出为True 对于非python基础类型的成立
b1 = 9999
print(id(b1))
b2 = func2(b1)
print(id(b2) == id(b1)) #此输出为False
这里是为了在计算的时候确保是进行按元素减法
batch_size为标量 所以除法是没问题的
这里可能存在疑问的是当param是w时,其是一个(2,1)的张量 ,其导数也是一个同shape的张量,可以看一下之前的自动求导部分,标量对于矩阵张量求导结果是一个转置的矩阵,即(1,2)的矩阵,这里并不会影响后续计算,据猜测是发生了转置操作以适配原有的w的shape,但是我在进行代码测试时发现此时竟然产生了广播操作
a = torch.ones((2, 1))
b = torch.ones((1, 2)) * 0.6
c=a-b
print(f'被减数shape为{a.shape}\n'
f'减数的shape为{b.shape}\n'
f'结果的shape为{c.shape}\n'
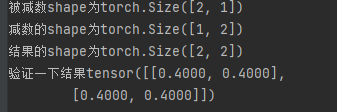
参数的梯度值和参数本身,其shape是一致的,那么也就不存在之前的广播,但是这又和沐神3之前PPT上的分子布局不同。先埋个坑 等我回来填
test1=torch.randn((1,2),requires_grad=True)
test2=torch.mm(test1,test1.T)
test2.shape
test2.backward()
test1.grad.shape == test1.shape
data_iter的最后一次取的样本个数可能小于batch size,那这样的话在sgd的时候还是除以batch size是不是不合适?感觉还是在计算loss的时候直接给出均值好一点
我也想知道,如果不导入dl2,会影响学习吗?或者代码实现吗?
因为优化算法中用了‘-=’,pytorch规定tensor带require_grad 不能进行“+=”或者“-=”(in-place操作),如果不进行in-place操作而是写成param =param-lr * param.grad / batch_size会导致param地址变动,后面对导数清零的时候就会报错,因为此时w.grad已经是’Nonetype’了
用with torch.no_grad():封装可以暂时关闭计算图,也就是在语句内进行的张量运算不改变已有的计算图,这样就可以进行in-place操作了
然而这段代码有除此之外的写法吗?求高人指点
我当时情况是x1>x2就交换两元素值。也可以理解,如果两个元素交换值之后,梯度确实依然可以计算,但这个梯度相对的就不再是原来的值了,所以会报错
param 有维度的情况下
param -= lr* param.grad
会原地修改param的值
比如:
a = lst[0] # 传的函数数值
a += 1
print(a,lst)
a = lst # 传递引用
a = a*2
print(a,lst)
经过我的测试
梯度的shape与其本身一直是保持一致的 我还测试了向量对矩阵进行求导,最后变量的梯度仍保持原来的shape,那么我们就可以认识 变量的梯度是与其同shape的一个成员。
沐神之前讲的应该是没有进行求和之前的梯度的计算,但是在pytorch中求导都是对输入进行i求和后再进行求导
在绘制features和labels的散点图时,为什么要使用labels.detach().numpy()呢?将detach().numpy()去掉也不会报错呀?比如这样:d2l.plt.scatter(features[:, (1)], labels, 1);