去掉nn.Softmax(-1)之后,我们的输出就不满足和为1了,甚至会出现负数,请问在预测的时候还是按照所谓的argmax来选择这个样本类别么? 也就是说我们的一系列softmax还有tensor.log,tensor.exp操作都是为了计算损失来优化模型的,这个理解对么? 
这个需要在JupyterNotebook里面跑才能出图像
问题已经解决啦 !好像是matplotlib包和d2l里面的包发生了一些冲突,具体也不太清楚,重新安装了一下就解决了
怎么可以在pycharm中跑出动态图呀,在pycharm就只是可以得到最终的图像?
1 Like
softmax归一并没有自己手写,Module中也没有,因为也不需要,argmax 对 未归一化前的 O向量和归一化后的 Y_hat向量结果一致。 其实Softmax操作应该是在CrossEntropyLoss中实现了,其满足了反向传播的需要,也通过特殊的技巧避免了溢出的问题
3 Likes
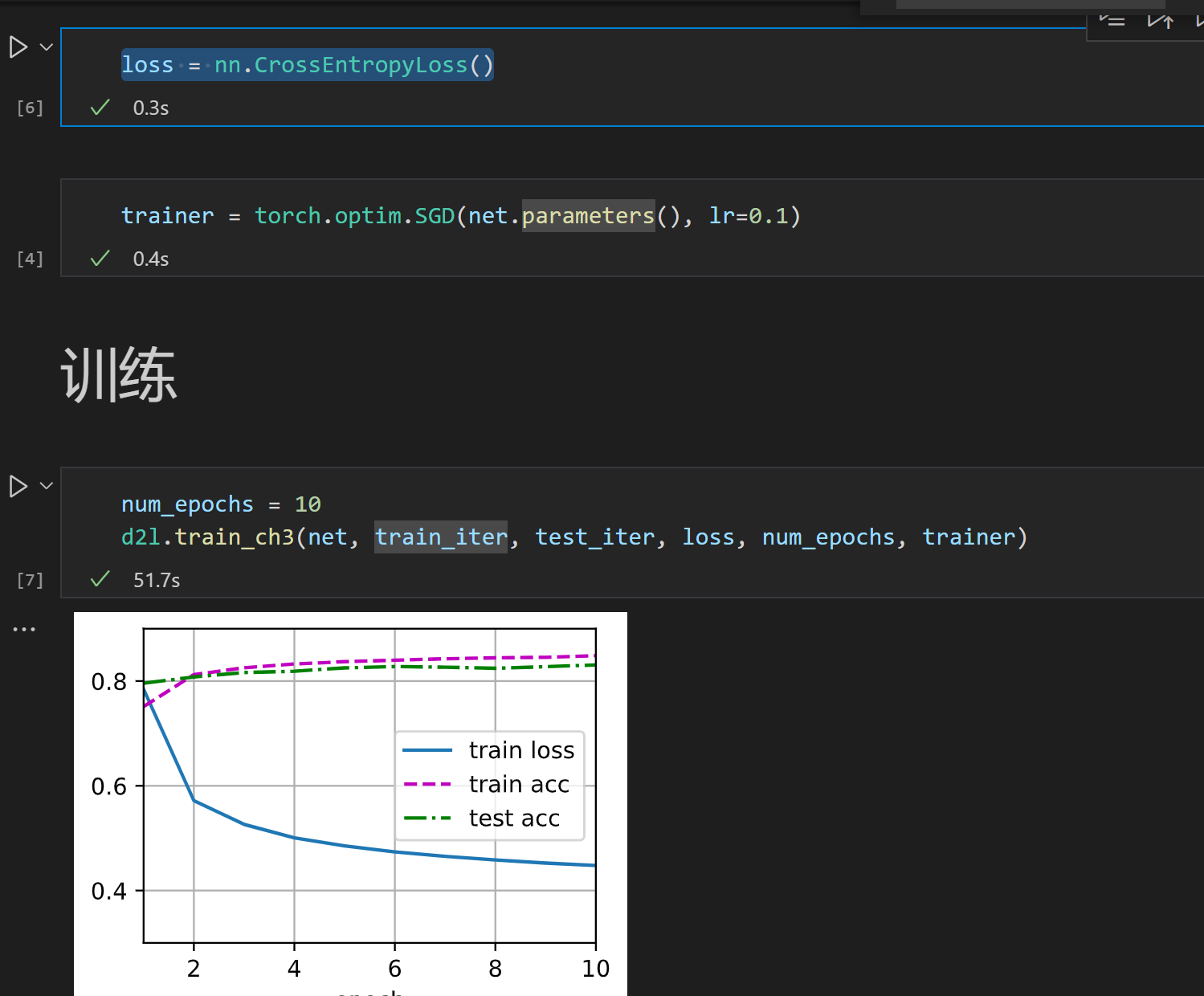
同问,一样的错误,一样没有train loss
我去对比了一下,d2l包中的train_epoch_ch3函数和这个网页教材上实现的train_epoch_ch3函数不同
教材上是使用了mean():
· if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
而在d2l包内实现的方法,使用了sum():
if isinstance(updater, torch.optim.Optimizer):
# Using PyTorch in-built optimizer & loss criterion
updater.zero_grad()
l.sum().backward()
updater.step()
可以从找到d2l包文件里面的torch.py,找到train_epoch_ch3的定义,并将它其中的sum()改为mean()
就应该正常显示train loss
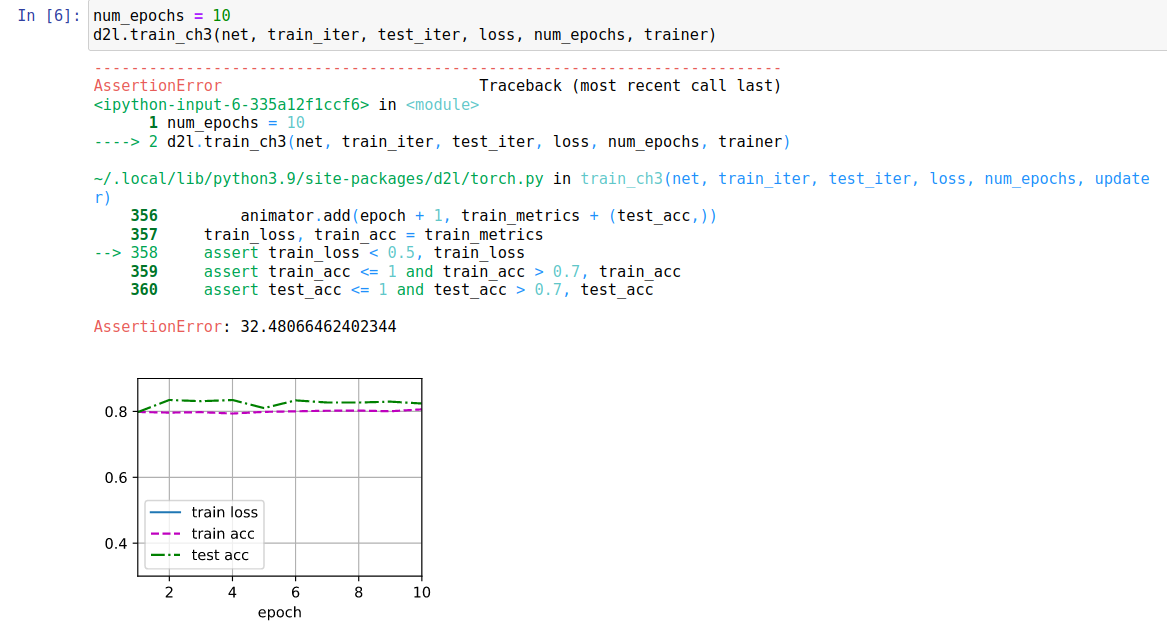
求和的话会导致train loss过大,应该改为教材中的求均值,超出train_ch3中assert的范围
7 Likes
Good catch, minibatch的平均损失,所以应该loss求mean 而不是sum, custom sgd应该用sum 因为 custom sgd 里面写了除以 batch_size
def ini_weights(m):
if isinstance(m, torch.nn.Linear):
torch.nn.init.normal(m.weight, std = 0.01)
m.bias.data.fill_(0)
可以自己添加一下 都是0
1 Like
想请问一下我复制书上的代码train_ch3()总是报错,spawn.py这里面的错误,出好几行报错,想问一下有大家有遇到过吗。 
2 Likes
不知道有没有人和我遇到一样的问题
简洁实现我直接复制代码然后运行,提示
RuntimeError: grad can be implicitly created only for scalar outputs
查了一下应该是loss维度的问题,但我不确定应该如何改进
2 Likes
问题确定了
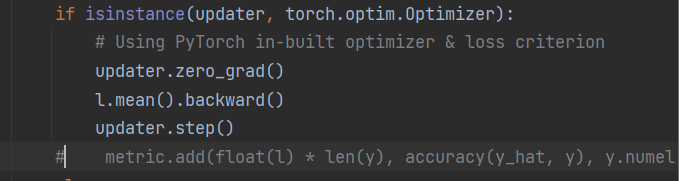
我导入的d2l包与教材&ppt里 train_epoch_ch3函数的写法不同
导入的包里是
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.backward()
updater.step()
metric.add(float(l), accuracy(y_hat, y), y.numel())
没有加.mean(),所以loss维度出现了问题
6 Likes
我的的d2l包里面的函数也没有加.mean(),我把它改成教材里的一样后也是有错误,请问最后问题解决了吗,是怎么解决的呢?
哦哦,我解决了,我把 metric.add(float(l), accuracy(y_hat, y), y.numel()) 给注释掉就跑通了
1 Like
请问在 Softmax回归的简洁实现中:
并没有手动写SOFTMAX()这个函数,net 就是一个简单的nn.Linear(784, 10))。那么pytorch到底是在哪一步给输出加了SOFTMAX()呢?
loss = nn.CrossEntropyLoss(reduction=‘none’)
请问为什么reduction=none对一次取出的256个样本做256个loss值,而不是mean相加做平均呢?
我多次运行的时候就有这个问题,按你说的改就好了,感谢分享