没有,是把网络输出的未归一化的预测传到Loss,在里面过Softmax做Cross-Entropy
2 Likes
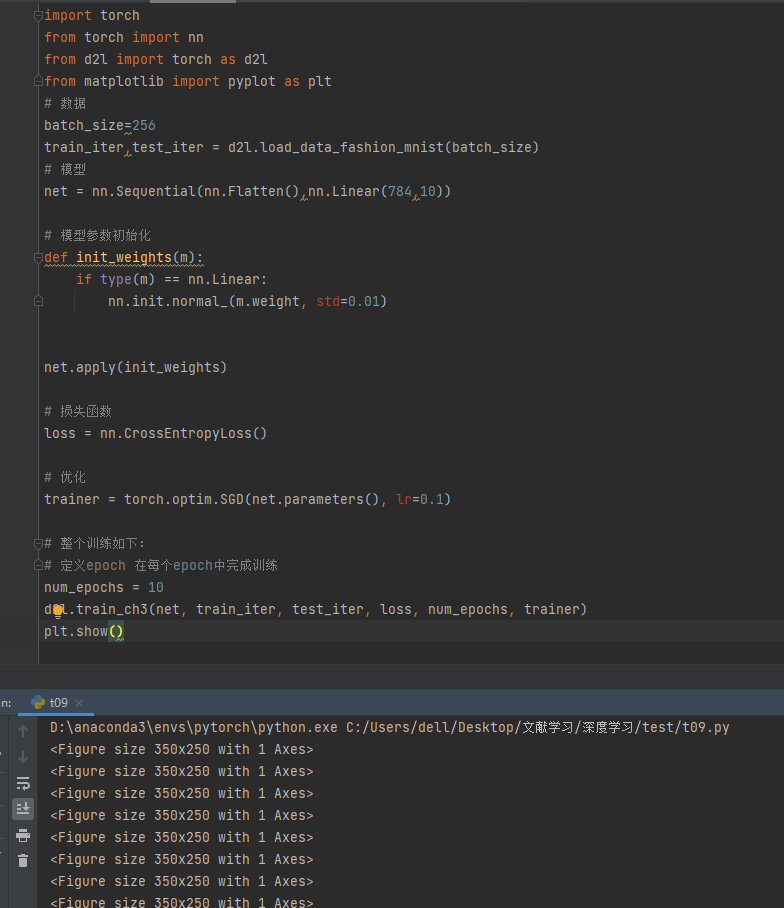
求助,我在colab上实现然后画出了learning curve,然后将notebook下载到本地打开后图像不显示了。用vscode打开能显示,但是jupyter服务里面打开图像不显示,只有这么一行输出。

运行时报错:RuntimeError: DataLoader worker (pid(s) 8528, 8488) exited unexpectedly
将参数 num_workers 全部置为0 num_workers=0
之后可以成功运行,但我不知道为什么
应该是在调用交叉熵损失函数的时候默认使用softmax激活函数
第二个问题:
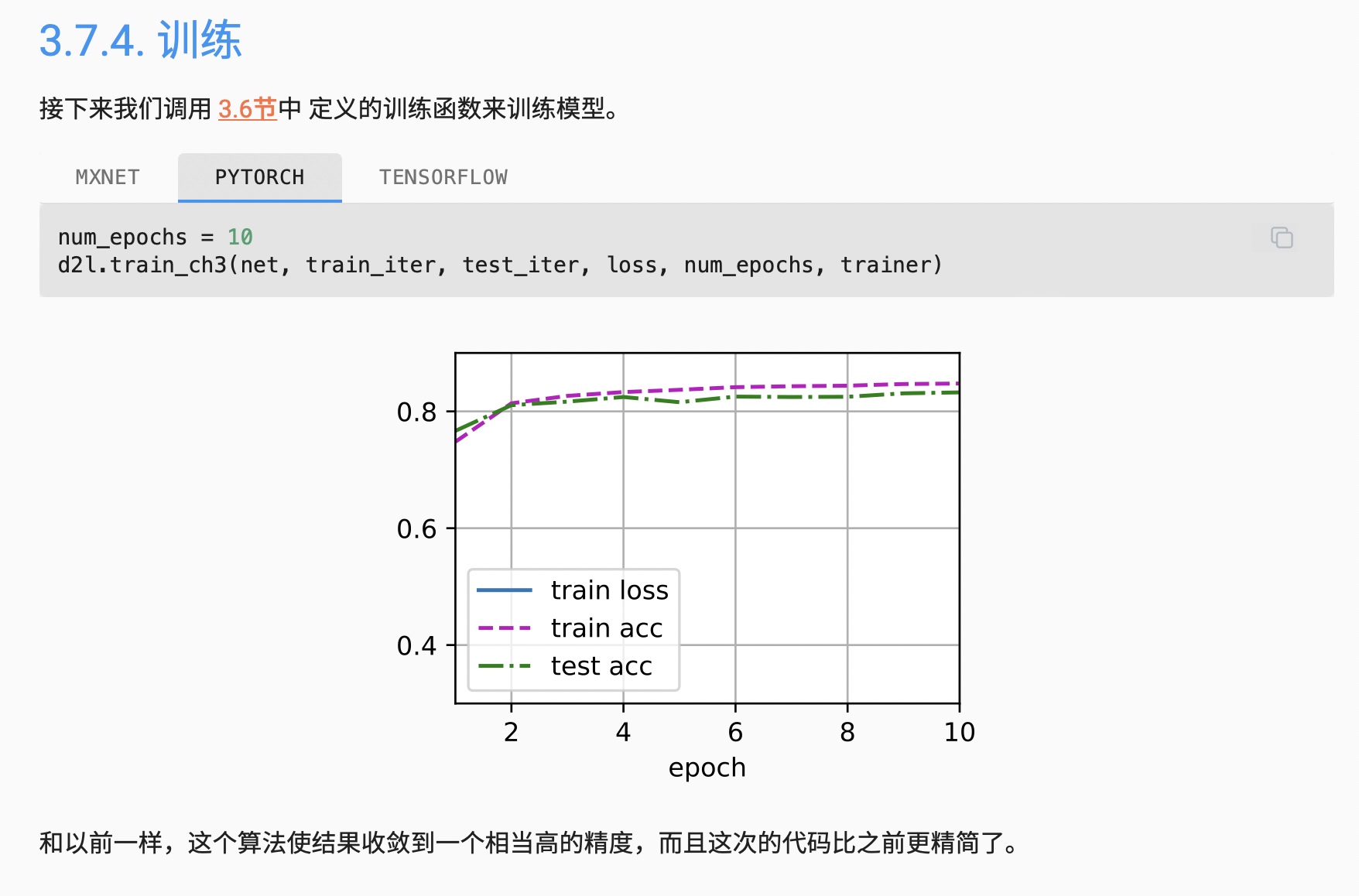
当epoch很大的时候,测试acc反而降低了,应该是可能过拟合了。
1 Like
大佬们好,问一个问题,在softmax的反向传播中,我已经推导出Loss对o的导数是 - y_i + softmax(o_j)
那么请问下一步如何更新w和b的值呢?
请大佬们不吝赐教,非常感谢!
需要看一下你要更改哪一层的w和b值,就SGD来说,按照w_=w - 梯度*步长。
这个题目是对O求的偏导,O=wx+b,还需要O对w求偏导,然后带入前向计算中算出来的y,O值可以得到梯度。
1 Like
非常感谢大佬的讲解,学习了您的回答后,我的理解如下:
对于一个单层的神经网络(Y_hat = softmax(O) , O=wx+b),使用SGD进行优化,求得loss对O的偏导为 -y + softmax(O) , O对w的偏导为x,那么根据链式求导法则,loss对w的偏导为 (-y + softmax(O) ) * x。
不知道是否可以这样理解呢?再次感谢!
是的没错,你很聪明!如果印射关系是o=wx+b的话,o对w的偏导确实是x。链式法则反向传播以后梯度确实是(-y + softmax(O) ) * x
以此类推的话,如果o=wx2+b(x2表示x的二次方)的映射关系,o对w的偏导是x2。那么就是(-y + softmax(O) ) * x2.
这里正向传播里x,o,y我们都可以算出来,那么反向传播的时候就能算出来梯度,用梯度去更新w就好了。
然后我也是跟大家一起学习的新手,不是什么大佬,期望跟你一起学习中进步。
4 Likes

是随机的,但不能是全零,全零进行不了梯度下降。
Hi @zhaofei2048,
We tested the get_dataloader_workers() with 4 num_workers on a windows machine (windows 11). The code ran perfectly fine. Could you share more details about the error you are facing and the environment to configure so that we can reproduce the problem on our end?
看公式3.7.2,还是会减去最大值来防止溢出的。
偏执初始化为0没问题啊,不知道你说的进行不了梯度下降指的是什么?
1 Like
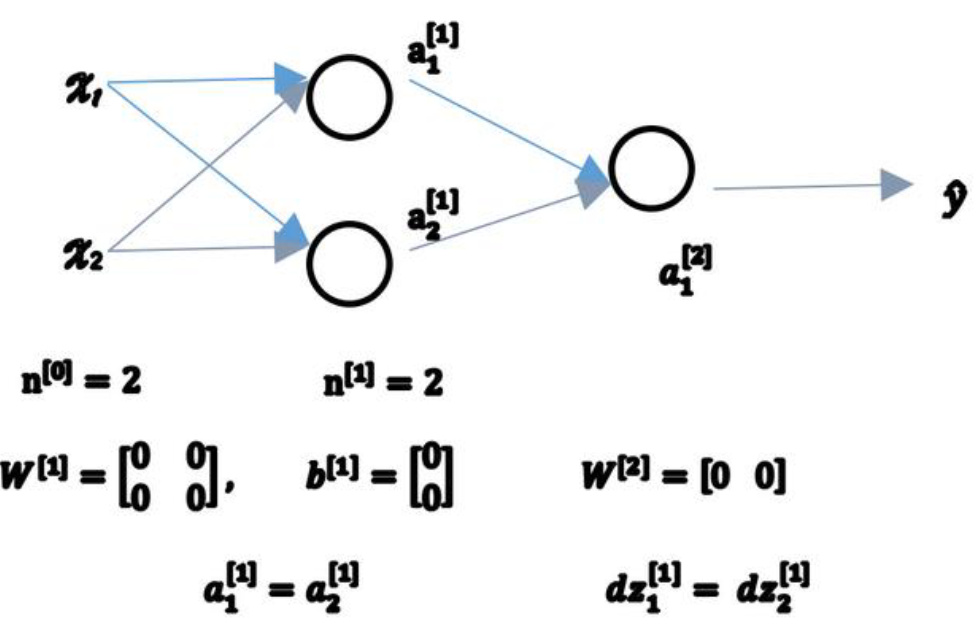
推理没有问题,但是在代码中如果全部初始化为0,训练依然可以完成,而且效率还更高。这个不知道是为什么。
大概思考了一下,因为实际计算过程中,梯度是由损失方程的导数得出。当权重被初始化为0时,损失方程loss(net(X,w,b), y)=loss(0,y), 而求导过程(假设线性回归)
由此可见,尽管权重都被初始化为0,但每个元素的梯度下降跟输入变量相关,所以梯度并不一样。这个也可以简单实验如下
import numpy as np
X=np.array([-1.6037177 , -0.81341785])
y=np.array([ 3.7554219 ])
w=np.zeros((2,1))
b=np.zeros((1,1))
#假设mse loss
y_hat = w*X+b
loss = (y_hat - y)**2/2
# refer to 3.1.10
w+=(y*X).reshape(w.shape)
# next w
print(w)
# [[-6.02263657]
# [-3.05472721]]
4 Likes
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
这个函数是没有默认参数值,在调用时没有为参数m指定值,整个3.7节一直没有未初始化函数指定m,能说说吗?