When we calculate the derivative of $y_j$ is 0, does it mean that we think $y_j$ has no relationship about $o_j$.
Hi @StevenJokes, $y_j$ is the real label while $o_j$ is the target, i.e. $y_j$ is not a function of $o_j$.
How do we judge whether $a$ is a function of $b$ or not?
Or we just judge by that we haven’t defined it before, rather than whether $a$ has a relationship with $b$ in reality or not.
I think it is a function in reality. But newton’s calculus can’t calculate its derivative, just because the function is discrete.
Please check https://github.com/d2l-ai/d2l-en/issues/1141 quickly, I think it maybe makes all eval wrong.
How do we judge whether $a$ is a function of $b$ or not?
Or we just judge by that we haven’t defined it before, rather than whether $a$ has a relationship with $b$ in reality or not.
Hi @StevenJokes, $y$ is the true label, while $\hat{y}$ is the estimated label. Hence $\hat{y}$ is a function of $o$, while $y$ is not.
I already have understand $y_j$ is the true label, such as one-hot. But the diverce of our thinking is that I think the true label has a certain relationship with $o_j$, so I think $y_j$ is also $o_j$'s function. When we get same $o_j$, we get only one and $y_j$. Doesn’t it conform the defination of function.
But the function is discrete.
As we saw in “Freshness and Distribution Shift”, if production data is different from the data a model was trained on, a model may struggle to perform. To help with this, you should check the inputs to your pipeline.
In 10. Build Safeguards for Models - Building Machine Learning Powered Applications [Book]
Although softmax is a nonlinear function, the outputs of softmax regression are still determined by an affine transformation of input features; thus, softmax regression is a linear model.
Can anyone explain this why is it so? because when we say that a model is linear model , then it means model is linear in the parameter but in softmax regression , we are applying softmax function which is non linear so our model parameter will become non linear.
Just a statistical speaking!
1 Like
exercise 1.1
apparrently i copied the answer above, 1.2 the variance is a vector and the j-th element is exactly the form of above which is softmax(0)_j(1-softmax(0)_j)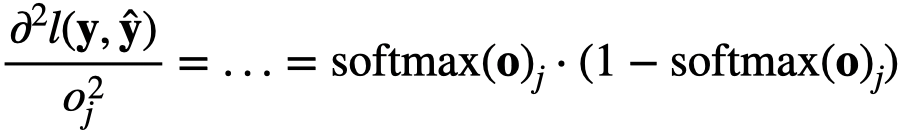
exercise 3.3 use the squeeze theorem and it’s easy to prove
3.4 softmin could be softmin(-x)? i dont know
3.5 pass (too hard to type on the computer)
In formula 3.4.7,
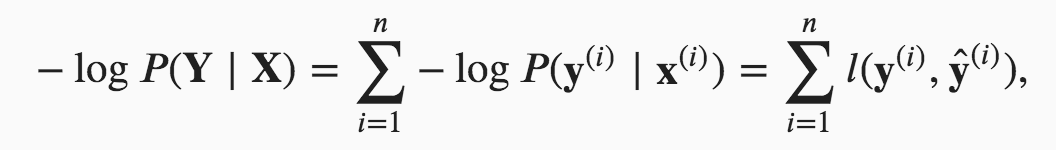
I couldn’t understand why the later 2 equations are equal, could someone explain a bit more to me? Thanks.

Hi @Gavin, great question. A simple answer is:
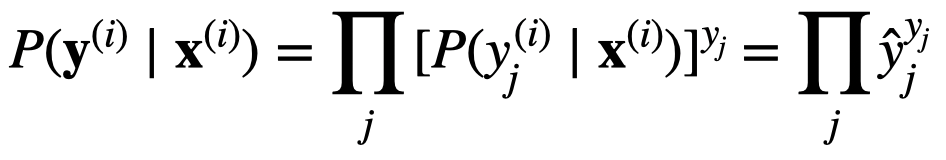
For more details, please check 22.7. Maximum Likelihood — Dive into Deep Learning 1.0.3 documentation
@goldpiggy
The simple answer seems to be Tautology.
I have read URL you give.
But I think it didn’t solve this question.
I can’t find anything in it.
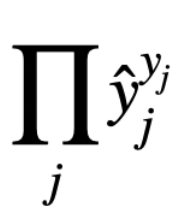
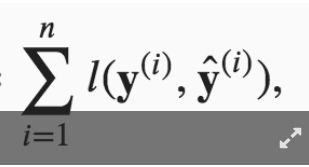 ?
?

