I got the same result as you.I also don’t understand why some discussions assume that the second-order partial derivative equals to variance of softmax when i=j.
Hi @goldpiggy ,
I think in Exercise 3.3, the condition should be \lambda -> positive infinite instead of \lambda->infinite.
Is that right?
Thanks
Sorry guys. here are my wrong answers. I kind of have the feeling that most of this is wrong looking at discussion here. but just putting it here for a sense of completion. But here is my contribution anyway.
Exercises
- We can explore the connection between exponential families and the softmax in some more
depth.
1. Compute the second derivative of the cross-entropy loss l(y, yˆ) for the softmax.
* after applying quotient rule for cross entropy loss the anaswer comes out to be zero.apparentlythis is wrong.
2. Compute the variance of the distribution given by softmax(o) and show that it matches
the second derivative computed above.
* Its close to zero through experiments too. but why should this happen? is second derivative essentially same as variance?
- Assume that we have three classes which occur with equal probability, i.e., the probability
vector is 1/3
1. What is the problem if we try to design a binary code for it?
* We would need at least 2 bits, and 00,01, 10 would be used but not 11. ?
2. Can you design a better code? Hint: what happens if we try to encode two independent
observations? What if we encode n observations jointly?
* we can do it through one hot encoding where the size of array would be the number of observations n
- Softmax is a misnomer for the mapping introduced above (but everyone in deep learning
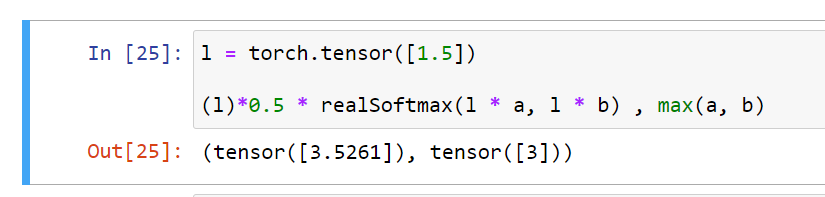
uses it). The real softmax is defined as RealSoftMax(a, b) = log(exp(a) + exp(b)).
1. Prove that RealSoftMax(a, b) > max(a, b).
* verified though not proved

There is a type in the sentence: “Then we can choose the class with the largest output value as our prediction…” it should be y hat at in the argmax rather than y
I’ve got the same result for the second derivative of the loss but I don’t know how to compute the variance or how it relates with the second derivative.
Did you make any progress ?

Think about the relationship between Hessian Matrix and Covariance Matrix
I think because the y in this equation 3.4.10 is an one_hot vector. so the sum of y_js is equal to y_j of the correct label.
I am unsure what this question is trying to get at:
- Assume that we have three classes which occur with equal probability, i.e., the probability vector is (1/3,1/3,1/3).
- What is the problem if we try to design a binary code for it?
- Can you design a better code? Hint: what happens if we try to encode two independent observations? What if we encode n observations jointly?
My guess is simply that binary encoding doesn’t work when you have more than 2 categories, and one hot encoding with possibilities (1,0,0), (0,1,0) and (0,0,1) works better.
However, this doesn’t seem to address the specific probability or the hint given, so I think my guess is too simplistic.
Any further reading suggestion for question 7?
Here are my opinions for the exs:
I still not sure about ex.1, ex.5.E, ex.5.F, ex.6
ex.1
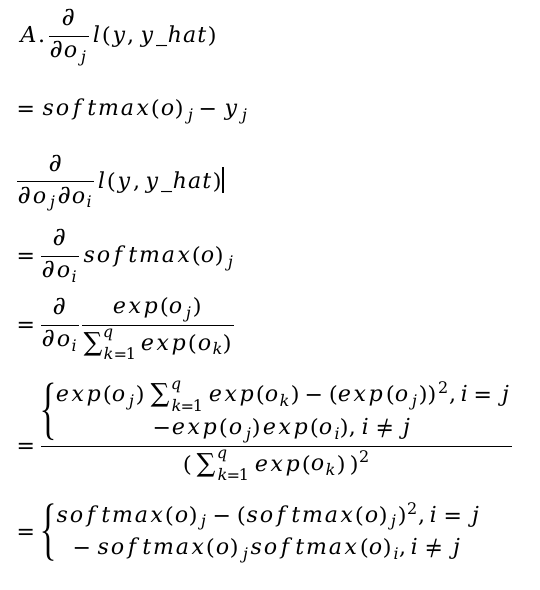
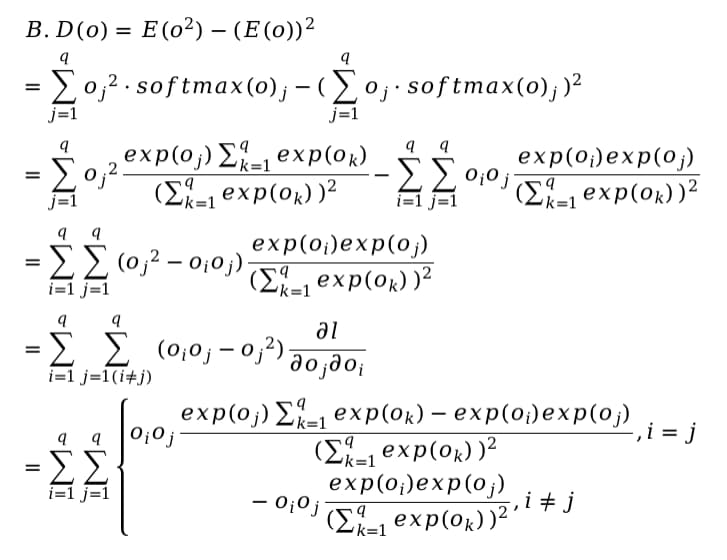
But, what does “match” means in question B?
ex.2
A. If I use binary code for the three class, like 00, 01, 11, then the distance between 00 and 01 is smaller than that between 00 and 11, that is oppose to the fact that the three class is of equal probability.
B. I think I should use one-hot coding mentioned in this chapter, because for any independent observation(which I think is a class), there contains no distance information between any pair of them.
ex.3
Two ternaries can have 9 different representation, so my answer is 2.
This ternary is suitable for electronics because in a physical wire, there will be three distinctive condition: positive voltage, negative voltage, zero voltage.
ex.4
A. Bradley-Terry model is like
![]()
When there are only two classes, softmax just fit this.
B. No matter how many classes there will be, if I put a higher score for class A compared to class B, the the B-T model will still let me chose class A, and after 3 times of comparing, I will chose the class with the highest score, that still holds true for the softmax.
ex.5

ex.6
This is my procedure for question A, but I can’t prove that the second derivative is just the variance.

As for the rest of the questions, I don’t even understand the question.
ex.7
A. Because of exp(−𝐸/𝑘𝑇), if I double T, alpha will go to 1/2, and if I halve it, alpha will go to 2, so T and alpha goes in opposite direction.
B. If T converge to 0, the possibility for any class will converge to 0, and the proportion between two class i and j exp( -(Ei - Ej) /kT) will also converge to 0. Like a frozen object of which all molecules is static.
C. If T converge to ∞, the proportion between two class i and j will converge to 1, which means every class has the same possibility to show up.
1 Like
Exercise 6 Show that g(x) is translation invariant, i.e., g(x+b) = g(x)
I don’t see how this can be true for b different from 0.
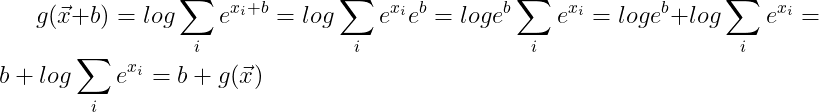
1 Like
Ex1.

Ex6 (issue: (1) translational invariant or equivariant? (Softmax is invariant, but log-sum-exp should be equivariant); (2) b or negative b? Adding maximum can make overflow problem worse).

The same result… I think we may say the log-partition function is translational equivariant rather than invariant. See also this page.
To ex.1, maybe we can take softmax distribution as Bernoulli distribution with a probability of $p = softmax(o)$, so the variance is:
$$Var[X] = E[X^2] - E[X]^2 = \text{softmax}(o)(1 - \text{softmax}(o))$$
I don’t know whether this suppose is right
and my solutions to the exs: 4.1
Does this mean that each coordinate of each y label vector is independent of each other? Also, shouldn’t the y_j of the last 2 equations also have a “i” superscript?
I read the URL given, but it doesn’t clarify too much for this specific case.