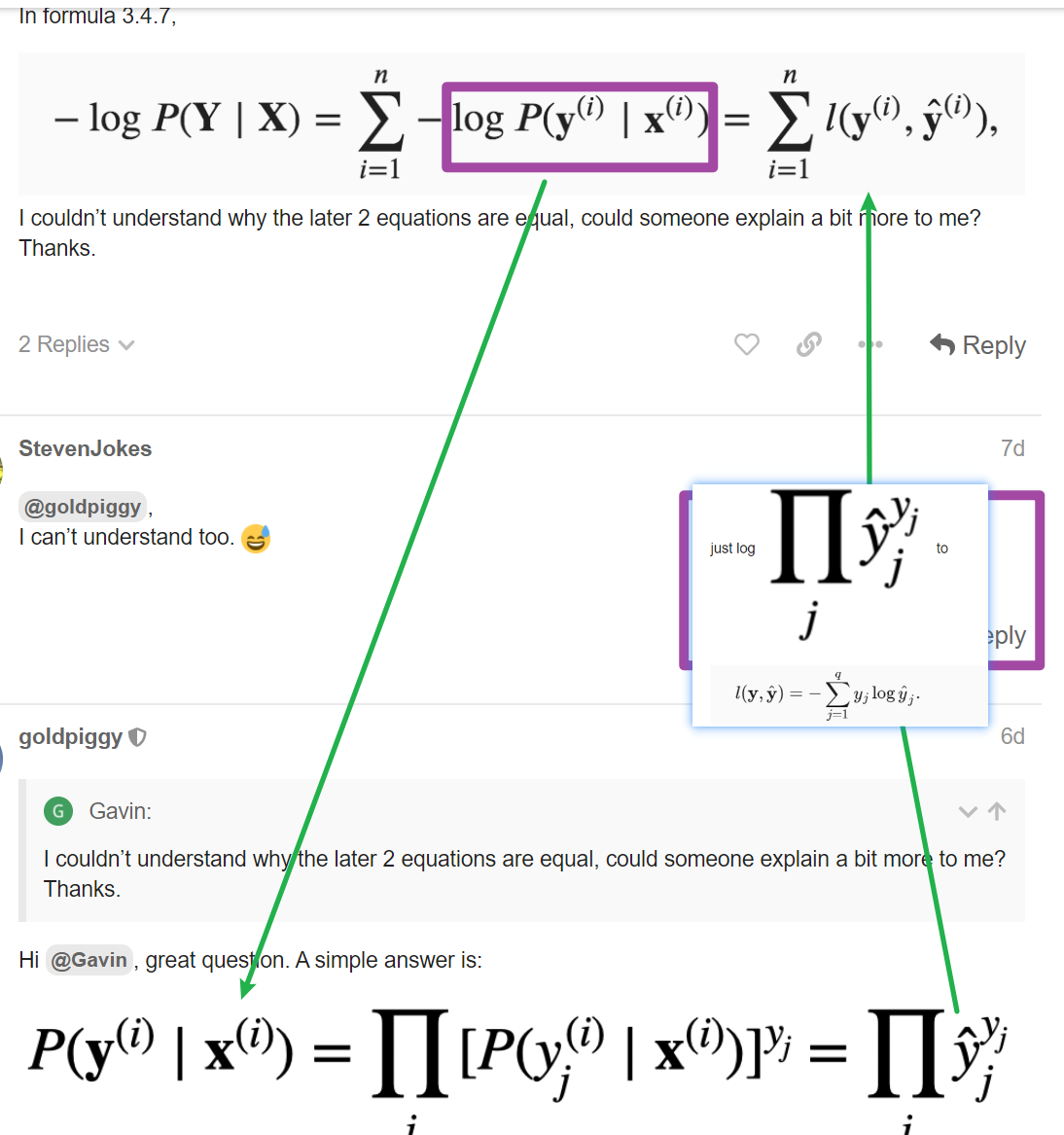
apparrently i copied the answer above, 1.2 the variance is a vector and the j-th element is exactly the form of above which is softmax(0)_j(1-softmax(0)_j)
exercise 3.3 use the squeeze theorem and it’s easy to prove
3.4 softmin could be softmin(-x)? i dont know
3.5 pass (too hard to type on the computer)
Hello. I am still not able to understand clearly how these 2 equations are related. Can you please explain, how for a particular observation i, the probability y given x is related to the entropy definition overall classes?
Thank you for your response. My question was more specifically why is same as
l(y,y_hat)
Is this because y when 1-hot encoded has only single position with 1 and hence when we sum up the y * log(y_hat) over the entire class, we are left with the probability y_hat corresponding to true y. Please advise.
Q1.2. Compute the variance of the distribution given by softmax(𝐨)softmax(o) and show that it matches the second derivative computed above.
Can someone point me in the right direction? I tried to use Var[𝑋]=𝐸[(𝑋−𝐸[𝑋])^2]=𝐸[𝑋^2]−𝐸[𝑋]^2 to find the variance but I ended up having the term 1/q^2… it doesn’t look like the second derivative from Q1.1.
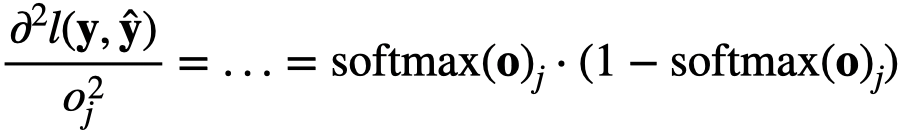
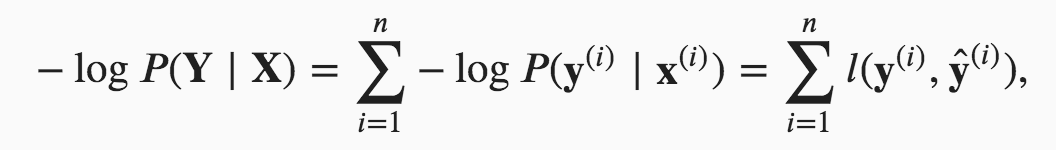

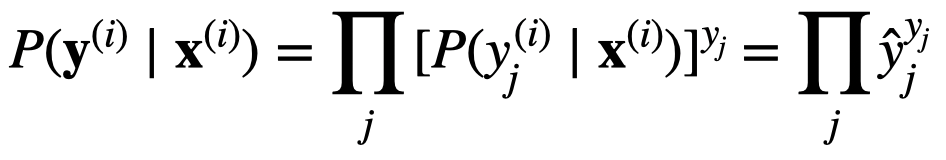
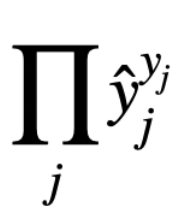
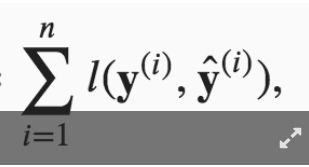 ?
?


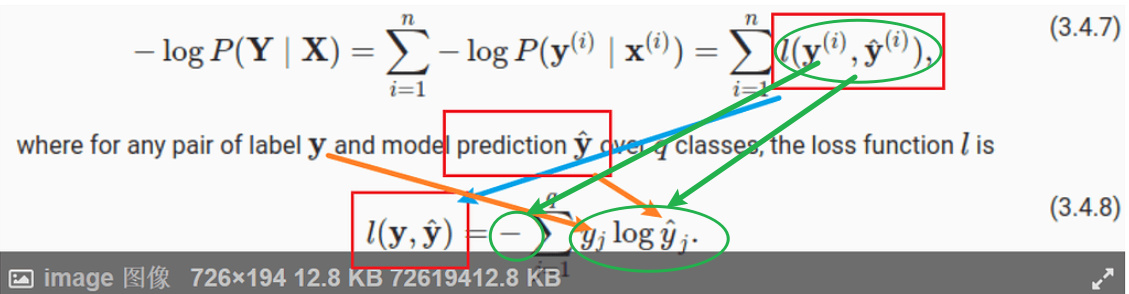
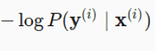 is same as
is same as