As far as I understood, the model should have no knowledge of the test data. Therefore,
for data preprocessing, shouldn’t we use only the training data to calculate the mean and variance,
then use them to rescale the test data?
Hi @Dchaoqun, great question! The normalization step here is to have all the features in the same scales, rather than one feature in range [0,0.1], another in [-1000, 1000]. The later case may lead to some sensitive weights parameters. But you are right, in the real life scenario, we may not know the test data at all, so we will assume the test and train set are following the similar feature distributions.
1 Like

I guess,maybe the gradient will be too small due to the derivation of (log(y)-log(y hat))^2.I don’t know if I am right.
A minor point, but in the PyTorch definition of log_rmse :
def log_rmse(net, features, labels):
# To further stabilize the value when the logarithm is taken, set the
# value less than 1 as 1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(torch.mean(loss(torch.log(clipped_preds),
torch.log(labels))))
return rmse.item()
Isn’t the torch.mean() call unnecessary, since loss is already the Mean Squared Error, ie the mean is already taken?
I tried to predict the logs of the prices instead, using the following loss function:
def log_train(preds, labels):
clipped_preds = torch.clamp(preds, 1, float('inf'))
rmse = torch.mean((torch.log(clipped_preds) - torch.log(labels)) ** 2)
return rmse
And the results were much worse. During the k-fold validation step, some of the folds had much higher validation/training losses than the others:

And sometimes the plot of losses didn’t appear to descend with epochs at all:
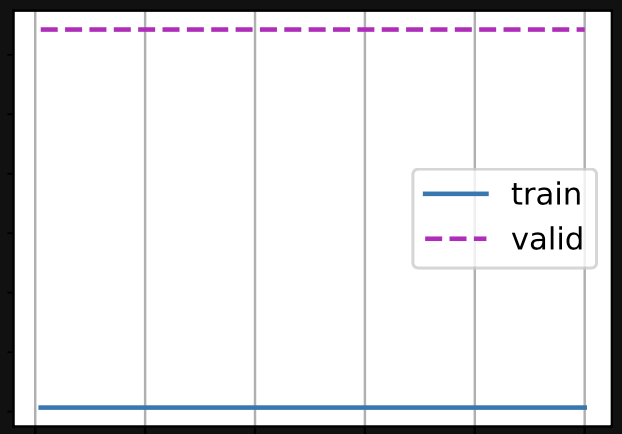
I suppose this is the point of the exercise, to show that it’s a bad idea, but I’m having trouble understanding why. It seems that instead of trying to minimise some concept of absolute error we’re trying to minimise a concept of relative (percentage) error between the prediction and the reality. Why would this lead to such instability?
Edit: I have an idea. In order to maintain numerical stability we have to clamp the predictions:
clipped_preds = torch.clamp(preds, 1, float('inf'))
But if the network parameters are initialised so that all of the initial predictions are below 1 (as is what I observed debugging one run) then they could all get clamped in this way and backprop would fail as the gradients are zero/meaningless?
1 Like
Hey @Nish, great question! Actually using log_rmse may not be a bad idea. I guess you only change the loss function but not other hyperparameters such as “lr” and “epoch”. Try a smaller “lr” such as 1, and a larger “epoch” such as 1000. What is more, the folds with high loss as 12 here might result from bad initialization, you can try net.initialize(init=init.Xavier() and more details here.)
3 Likes
Thank you @goldpiggy ! So it sounds like my final point could be correct - that the issues came from bad initialisation so that all the initial predictions get clamped to 1 and the gradient is meaningless?
Hey @Nish, you got the idea! Initialization and learning rate are crucial to neural network. If you read further into advanced HPO in later chapters, you will find learning rate scheduler. Keep up!
2 Likes
Hi, @goldpiggy
Analogy:
- Initialization is more like talent?
- lr is more like efforts to understand world?
I don’t get why we need torch.mean in the function above. Isn’t the loss, which is MSELoss has the “mean” already? Why do we need to do the mean again?
Hi @swg104, great catch. Would like to post a PR and be a contributor?
(However, since the final loss is divided by “n” double times, it won’t affect the weights optimization.)
Thanks @swg104. Feel free to PR if anything else doesn’t look right. We appreciate you effort to promote the community! 
In Data preprocessing, why do we standarize the data before replacing missing values with the corresponding features’s mean? Shouldn’t be the opposite, as stated into the text?
Thx
@HtC
You will find the orders have same effect.
The reason why we replace missing values with the corresponding features’s mean is to keep the whole’s mean and variance same with the mean and variance before.

Thx, I know the reason why we replace missing values with the mean…
I didn’t think the reverse order leads to the same result 
I just realized it isn’t same.
Replacing missing values will make variance smaller than before, because the denominator is bigger.
So replacing missing values before standarizing the data will be bigger.