I don’t get why we need torch.mean in the function above. Isn’t the loss, which is MSELoss has the “mean” already? Why do we need to do the mean again?
Hi @swg104, great catch. Would like to post a PR and be a contributor?
(However, since the final loss is divided by “n” double times, it won’t affect the weights optimization.)
Thanks @swg104. Feel free to PR if anything else doesn’t look right. We appreciate you effort to promote the community! 
In Data preprocessing, why do we standarize the data before replacing missing values with the corresponding features’s mean? Shouldn’t be the opposite, as stated into the text?
Thx
@HtC
You will find the orders have same effect.
The reason why we replace missing values with the corresponding features’s mean is to keep the whole’s mean and variance same with the mean and variance before.

Thx, I know the reason why we replace missing values with the mean…
I didn’t think the reverse order leads to the same result 
I just realized it isn’t same.
Replacing missing values will make variance smaller than before, because the denominator is bigger.
So replacing missing values before standarizing the data will be bigger.
Yes, I was just looking at the same thing.
Hence, what is the correct order?
Exercises and my silly answers
- Submit your predictions for this section to Kaggle. How good are your predictions?
- I got a rmse value of 0.16703
- Can you improve your model by minimizing the logarithm of prices directly? What happens
if you try to predict the logarithm of the price rather than the price?
- The log rmse values are coming as Nan
- Is it always a good idea to replace missing values by their mean? Hint: can you construct a
situation where the values are not missing at random?
- It might be the case where the date data is given and dates in between are missing in that case we can put in the date
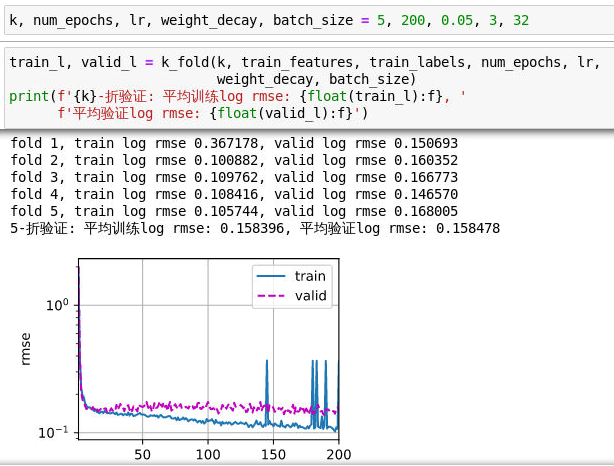
- Improve the score on Kaggle by tuning the hyperparameters through K-fold crossvalidation.
- I have improved it once.
- Improve the score by improving the model (e.g., layers, weight decay, and dropout).
- tried adding more layers but accuracy decreased.
- What happens if we do not standardize the continuous numerical features like what we have
done in this section?
- improper features size that are different for different features.
Only changing the hyperparameters batch_size=64 and lr=10 can achieve a result of 0.14826.
When the layer is added, although the training loss will be reduced, it will always cause over-fitting. No matter whether you use Dropout or weight attenuation, it is unavoidable.I think this data set is too simple and not suitable for deep networks.

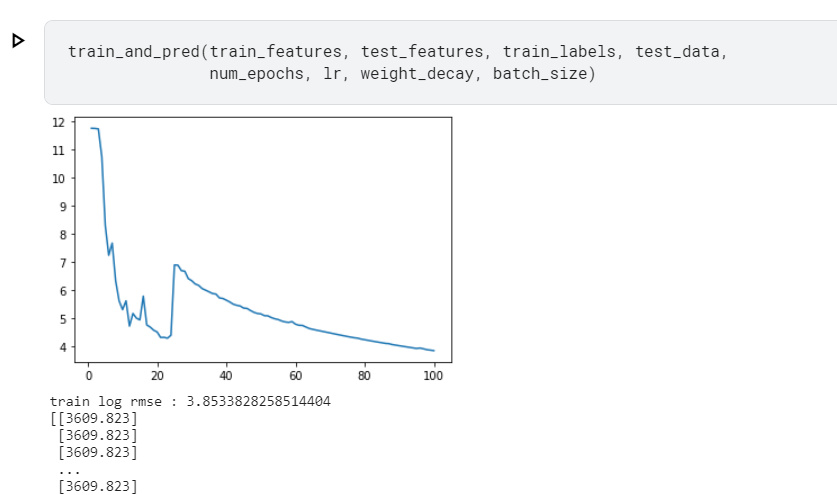
I don’t know if anyone has used the deep network to achieve better results, please share! 
Hi I wonder do we need to initialize the weight and bias before train the model? like using net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
Is the section on Kaggle prediction house price data preprocessing wrong? In the article it says “we apply a heuristic, replacing all missing values by the corresponding feature’s mean.” but in the code it says “Replace NAN numerical features by 0”. Is it better to choose the mean substitution method?
Question: Code test $E[(x-\mu)^2]$ != $\sigma^2$
According the formula below:
$E[(x-\mu)^2] = (\sigma^2 + \mu^2) - 2\mu^2+\mu^2 = \sigma^2$
When I use code to test it, the result is not equal, so I am very confused.
a=torch.tensor([1.,2.,3.])
a_mean=a.mean()
print(a_mean) # tensor(2.)
a_var=a.var() # formula: Var(x)=Sum( (x-E(x))**2 )/(n-1)
print(a_var) # tensor(1.)
a_std=a.std()
print(a_std) # tensor(1.)
b=(a-a_mean)**2
print(b)
print(b.mean()) # tensor(0.6667)
print(b.mean()==a_std**2) # tensor(False) ??? why the result not equal

I’m getting the following error when I simply run the code as-is from the tutorial. Can anyone help me understand?
Hey, bro. I came this error the same.Do you know how to resolve it right now?
In the data preprocessing section, it seems that the code in the book simply standardized the numerical features with mu and sigma computed on a concatenated dataset. Wouldn’t this cause information leak?
Because get_dummies generate bool values. Try this after get_dummies:
features = pd.get_dummies(features, dummy_na=True)
features *= 1
In the code below, I wonder how I get the hash value?
class KaggleHouse(d2l.DataModule):
def init(self, batch_size, train=None, val=None):
super().init()
self.save_hyperparameters()
if self.train is None:
self.raw_train = pd.read_csv(d2l.download(
d2l.DATA_URL + ‘kaggle_house_pred_train.csv’, self.root,
sha1_hash=‘585e9cc93e70b39160e7921475f9bcd7d31219ce’))
self.raw_val = pd.read_csv(d2l.download(
d2l.DATA_URL + ‘kaggle_house_pred_test.csv’, self.root,
sha1_hash=‘fa19780a7b011d9b009e8bff8e99922a8ee2eb90’))