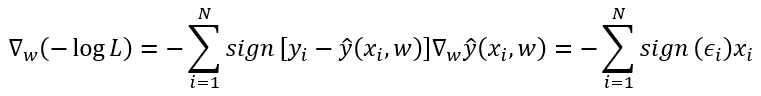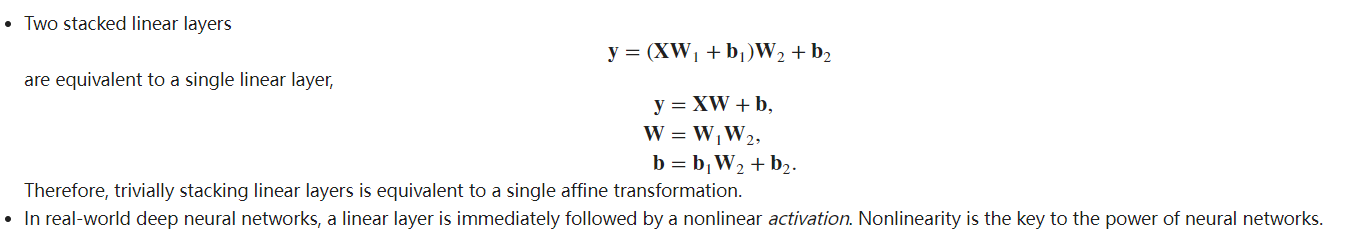No, “minibatches” is fine here. Compare this to:
She likes gummy bears so much, that she typically eats whole packets of them at one sitting.
Here “packets” is the right word, not “packet”.
No, “minibatches” is fine here. Compare this to:
She likes gummy bears so much, that she typically eats whole packets of them at one sitting.
Here “packets” is the right word, not “packet”.
The following sentence is not easy to parse:
Certainly, the high-level idea that many such units could be cobbled together with the right connectivity and right learning algorithm, to produce far more interesting and complex behavior than any one neuron alone could express owes to our study of real biological neural systems.
Adding some parentheses seems to make it clearer:
Certainly, the high-level idea that many such units could be cobbled together with the right connectivity and right learning algorithm—to produce far more interesting and complex behavior than any one neuron alone could express—owes to our study of real biological neural systems.
Or:
Certainly, the high-level idea that many such units could be cobbled together with the right connectivity and right learning algorithm (to produce far more interesting and complex behavior than any one neuron alone could express) owes to our study of real biological neural systems.
Here are my wrong answers.
∑x1, . . . , xn ∈ R. Our goal is to find a constant b such that (xi − b)2 is minimized.
1. Find a analytic solution for the optimal value of b.
* solving for xi = b
2. How does this problem and its solution relate to the normal distribution?
* if xi=b then normal equation becomes 1/rootof(2 * pi * sigma^2) * exp(0) == 1/rootof(2 * pi * sigma^2)
error. To keep things simple, you can omit the bias b from the problem (we can do this in
principled fashion by adding one column to X consisting of all ones).
1. Write out the optimization problem in matrix and vector notation (treat all the data as
a single matrix, and all the target values as a single vector).
* X = [[2,3],[4,5]] , y = [0,1]
2. Compute the gradient of the loss with respect to w.
* Not really what was asked but -

3. Find the analytic solution by setting the gradient equal to zero and solving the matrix
equation.
* The questions subpoint tell you how to do it step wise. we have to minimize || y- Xw ||^2 so differentiating w.r.t w and putting it to zero, we have 2X(y-Xw) = 0, which means = Xy = X.Xw w = (X.X)^-1* Xy.

4. When might this be better than using stochastic gradient descent? When might this
method break?
* This method would be good for small datasets, but on larger datasets the cost of storing the entire data in memory and multiplication may be prohibhitive.
That is, p(ϵ) = 1/2 * exp(−|ϵ|).
1. Write out the negative log-likelihood of the data under the model − log P(y | X).
* 1/2 * exp(-|1/root(2 * pi * sigma ^ 2) * exp(-1/(2 * sigma **2) * (x- mu) **2)|) ? what is exponential distribution formula?
2. Can you find a closed form solution?
hmm not quite.
3. Suggest a stochastic gradient descent algorithm to solve this problem. What could possibly go wrong (hint: what happens near the stationary point as we keep on updating the parameters)? Can you fix this?
Not really know whats going on here.In linear regression the epsilon is called error, noise, or disturbance. In classical linear regression context, say, it is this error that has distribution, for instance, N(0, sigma^2). Theoretically, this normality assumption is critical in applying linear regression. Not only for obtaining maximum likelihood estimator for each of parameters, but also for making inference. On the other hand, residuals can be obtained once you have sample. In linear regression theory, the error and the residual have different variances. However, in practice, we can use residual as proxy for the error.
Thank you @gphilip
From deeplearningbook.org I understood why it should be minibatches:
from section 8.1.3:
“Many optimization problems in machine learning decompose over examples well enough that we can compute entire separate updates over different examples in parallel. In other words, we can compute the update that minimizes J(X) for one minibatch of examples X at the same time that we compute the update for several other minibatches. Such asynchronous parallel distributed approaches are discussed further in section 12.1.3.”
Oh well, I read your original question as one about grammar, not about how the training process works!
Hi Halu,
You’re right that the solution (3.1.8) is only correct if (X⊤X) is invertible. In the case where (X⊤X) is not invertible (which happens when the columns of X are dependent), it turns out that the set of weights w*,
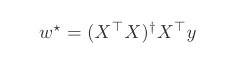
minimizes the loss function (3.1.6). Here, X^+ is the pseudoinverse of X. In essence, every matrix has a pseudoinverse, and the pseudoinverse of an invertible matrix is equivalent to its inverse. You may refer to
Numerically, computing the pseudoinverse of an n x n matrix takes O(n^3), which is similar to computing inverse.
I believe that the authors did not discuss the more general case, because of its technicalities, but they omitted to make the implicit assumption that you pointed out.
Excercise 3 (Median regression?)
This was more interesting than I thought initially.
With the likelihood
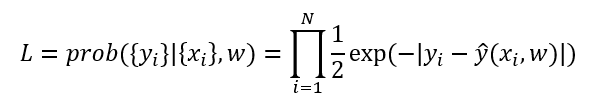
and the prediction
![]()
the negative log-likelihood should be
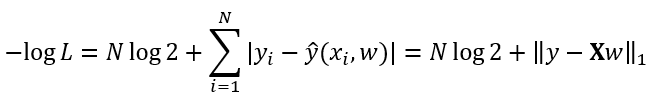 .
.
This is kind of a closed-form solution that should be easily vectorizable.
I could not find a closed-form analytical solution to the gradient in respect to the weights to solve ![]() though. The farthest I got was
though. The farthest I got was
I don’t know what is done in this case, but I could imagine that increasing the batch size when the optimization comes closer to a stationary point could be useful, or reduction of the learning rate over time, but this would be certainly a parameter to tune.
I would try also to average the gradient between minibatches, e.g. so that the gradient used to update the parameters consists of some small constant ![]() times the gradient of the current batch plus
times the gradient of the current batch plus ![]() times the gradient of the previous batch. Unfortunately, this would make parallelization over batches difficult.
times the gradient of the previous batch. Unfortunately, this would make parallelization over batches difficult.
Maybe there’s also a way to smooth the jumps?
Its the issue with the matplotlib version. Try updating it
I still have some problem in ex.5_C, ex.7_A, can anybody help me with them?
My opinions about the exercises:
ex.1
A.
∂ ∑(𝑥𝑖−𝑏)^2 = 0
-> ∂(∑𝑥𝑖^2 + nb^2 - 2b∑𝑥𝑖) = 0
-> 2nb - 2∑𝑥𝑖 = 0
-> b = (∑𝑥𝑖)/n
B. Assume that y = b + 𝜖 where the noise 𝜖 is normally distributed, if we want to maximize the likelihood of the entire dataset, then we will minimize ∑(𝑥𝑖−𝑏)^2.
C.cannot get an analytical solution because absolution doesn’t have a derivative.
ex.2
theory: (xT, 1) * (w; b) = xTw + b
code:
import torch
def ex2_affine(w, x, b):
result_by_affine = torch.mm(x.T,w)+b
print("result_by_affine:\n",result_by_affine)
def ex2_linear(w, x, b):
b_in_row = torch.ones(x.shape[1]).unsqueeze(0)
x_and_one = torch.cat((x,b_in_row),0)
w_and_b = torch.cat((w,torch.tensor([b]).unsqueeze(0)),0)
result_by_linear = torch.mm(x_and_one.T, w_and_b)
print("result_by_linear:\n",result_by_linear)
w = torch.tensor([1.,2.]).unsqueeze(1)
x = torch.randn([2,3])
b = 3.
ex2_affine(w,x,b)
ex2_linear(w,x,b)
result_by_affine:
tensor([[1.4326],
[3.2007],
[2.7533]])
result_by_linear:
tensor([[1.4326],
[3.2007],
[2.7533]])
ex.3
ex.4
A. There will be more than one (actually infinite) optimal solution for (w,b).
B. I think we can drop out the dependent dimension(s) from each example, which means we will reduce the number of dimensions of both x and w.
But if we add a coordinate-wise independent Gaussian noise to each dependent dimension(is that what “small amout” means, I’m not so sure about the statement in this question), so we can make the design matrix to have full rank.
C. Given that each Gaussian noise 𝜖∼N(𝜇,𝜎^2) is independent from each other, the element at ith row and j col of design matrix X.TX will be:
XiXj
= ∑[for all d] XidXjd
= ∑[for all originally indenpentdent dimension d] Xid * Xjd
+∑[for all idenpentdent dimension d] Xid * Xjd + 𝜖d ^ 2 + 𝜖d *(Xid + Xjd)
and the expectation of it will be(Ed and 𝜇d is the expectation of dth diemention and the Gaussian noise added on it)
∑(for all dimension d) Ed ^ 2
+∑(for all idenpentdent dimension d) 𝜇d ^ 2
+∑(for all idenpentdent dimension d) 2 * 𝜇d * Ed
D. If we compute the partial derivative of one dependent dimension u, which is depent on v, say, u = f(v), then the result will be like ∂ul + ∂vl * ∂uf’, the same thing happens when we compute on dimension v.
ex.5
A. −log𝑃(𝐲∣𝐗) = ∑ |𝑦−𝐰⊤𝐱−𝑏|
B. There is no close-formed solution cause the absolute.
C. ???
ex.6
As each input of the second layer is like w1x1 + w2x2 +…, some of them may become very large while others become very small, and that may break the balance among the weights of the second layer.
ex.7
A. The Gaussian noise varies from negative infinite to positive infinite, so it’s possible that the price will take a negative value, that is not appropriate.
But for the existing fluctuation, maybe the squared Gaussian noise is useful.(??? I’m not so sure.)
B. If we use logarithm of the price, the price will be limited to be positive.
C. If the price takes a very penny value, the logarithm of it will go to a very large negative number, that may cause overflow. As the price for a house is always not so penny, we may need to drop the peenystocks in our dataset.
ex.8
A. As the Gaussian noise is a continuous value while the number of apples is a discrete value, we cannot use Gaussian noise without any preprocessing.
B.
I searched on the internet an found this, note that the core idea is using Taylor’s formula for e^x.
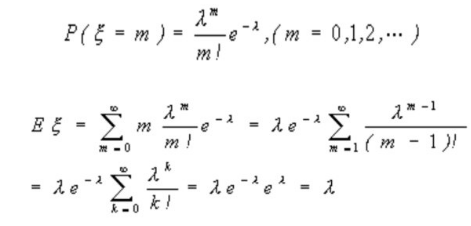
C.
Assume that each example is fetched independently, so the maximum likelihood for the X is like:
argmax[𝜆] P(X)
->armax[𝜆] ∏(𝜆^x * 𝑒^(−𝜆)/x!
→ argmax[𝜆] log(∏(𝜆^x * 𝑒^(−𝜆)/x!)
→ argmin[𝜆] -∑log(𝜆^x * 𝑒^(−𝜆)/x!)
→ argmin[𝜆] -∑(x * log𝜆 - 𝜆 - log(x!))
→ argmin[𝜆] -log𝜆∑x + n𝜆
So the loss function is (-log𝜆∑x + n𝜆), where n is the number of examples.
D. According to C, the loss function for log𝜆(denoted by L) will be
(-L∑x + n * e^L)
ex1:
a. The analytical solution is: b = x_(bar), x_bar is the sample mean.
b. The problem is a sum of residual problem, and the solution is the maximum likelihood estimator of b. By a statistical theorem, the MLE follows a normal distribution with the mean being the MLE and variance being the inverse of the observed fisher information.
c. the analytical solution is b = x_bar. The key is to transform the absolute value into square root of the square of x_i - b.
Hi,
Just to clarify terminology here, on 3.1.1.4 where it says:
“The most naive application of gradient descent consists of taking the derivative of the loss function, which is an average of the losses computed on every single example in the dataset”
Would it be a cost function instead of the loss function due to the fact that the loss function is for one example, while the correct terminology for a cost function is the average over every example?
Thank you,
Ethan
What is meant by the value of a matrix in exercise 4.3 to this chapter?
Question 8: “Suppose we want to use regression to estimate the number of apples sold in a grocery store”. It is not clear to me, estimate the number of apples from what? I.e. what are the independent variables? Do we have a history of daily sales (number of apples sold every day or time intervals between sale of each apple or something else) and want to estimate lambda?
Or do you mean linear regression with the error term distributed according to the Poisson distribution?
Answers to Exercises generated by ChatGPT with GPT 4.0 and the Wolfram Plugin:
Exercise 1:
Let’s solve this analytically.
To minimize the sum of squared differences, we take the derivative of the function with respect to (b), set it equal to zero, and solve for (b).
The function to minimize is:
$$
f(b) = \sum_{i=1}^{n} (x_i - b)^2
$$
Taking the derivative with respect to (b) gives:
$$
f’(b) = \sum_{i=1}^{n} -2(x_i - b)
$$
Setting this equal to zero and solving for (b) gives:
$$
0 = \sum_{i=1}^{n} -2(x_i - b)
$$
Solving for (b) gives:
$$
b = \frac{1}{n} \sum_{i=1}^{n} x_i
$$
So the value of (b) that minimizes the sum of squared differences is the mean of the (x_i).
This problem and its solution relate to the normal distribution because the sum of squared differences is the basis for the maximum likelihood estimation of the mean of a normal distribution. In other words, the mean of a normal distribution is the value that maximizes the likelihood of the observed data, which is equivalent to minimizing the sum of squared differences from the mean.
If we change the loss function to the sum of absolute differences, the problem becomes finding the median of the (x_i). This is because the median is the value that minimizes the sum of absolute differences. Unlike the mean, the median is not sensitive to extreme values, so it is a more robust measure of central tendency when there are outliers in the data.
Exercise 2:
An affine function is a function composed of a linear transformation and a translation. In the context of machine learning, an affine function often takes the form (f(\mathbf{x}) = \mathbf{x}^\top \mathbf{w} + b), where (\mathbf{x}) is an input vector, (\mathbf{w}) is a weight vector, and (b) is a bias term.
We can show that this affine function is equivalent to a linear function on the augmented vector ((\mathbf{x}, 1)) by considering a new weight vector (\mathbf{w}’ = (\mathbf{w}, b)) and an augmented input vector (\mathbf{x}’ = (\mathbf{x}, 1)). Then the affine function can be written as a linear function:
$$
f(\mathbf{x}) = \mathbf{x}^\top \mathbf{w} + b = \mathbf{x}’^\top \mathbf{w}’
$$
Here’s the proof:
The original affine function is (f(\mathbf{x}) = \mathbf{x}^\top \mathbf{w} + b).
We define (\mathbf{x}’ = (\mathbf{x}, 1)) and (\mathbf{w}’ = (\mathbf{w}, b)).
The dot product (\mathbf{x}’^\top \mathbf{w}’) is (\mathbf{x}^\top \mathbf{w} + 1 \cdot b), which is exactly the original affine function.
Therefore, the affine function (\mathbf{x}^\top \mathbf{w} + b) is equivalent to the linear function (\mathbf{x}’^\top \mathbf{w}’) on the augmented vector ((\mathbf{x}, 1)). This equivalence is often used in machine learning to simplify the notation and the implementation of algorithms.
Answers to Exercises generated by ChatGPT with GPT 4.0 and the Wolfram Plugin:
Exercise 3:
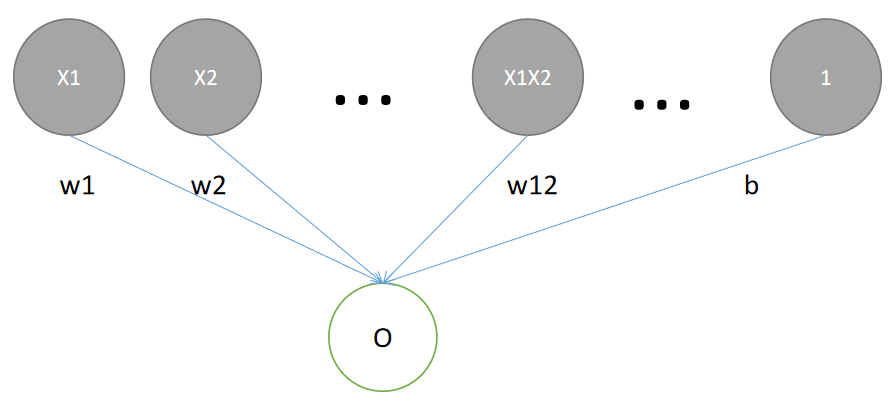
A quadratic function of the form (f(\mathbf{x}) = b + \sum_i w_i x_i + \sum_{j \leq i} w_{ij} x_{i} x_{j}) can be implemented in a deep network using a fully connected layer followed by an element-wise multiplication operation and another fully connected layer. Here’s how you can do it:
Input Layer: The input to the network is the vector (\mathbf{x}).
First Fully Connected Layer: This layer applies a linear transformation to the input vector. The weights of this layer represent the (w_i) terms in the quadratic function. The output of this layer is (b + \sum_i w_i x_i).
Element-wise Multiplication Layer: This layer computes the element-wise product of the input vector with itself, resulting in the vector (\mathbf{x} \odot \mathbf{x}), where (\odot) denotes element-wise multiplication. This operation corresponds to the (x_i x_j) terms in the quadratic function.
Second Fully Connected Layer: This layer applies a linear transformation to the output of the element-wise multiplication layer. The weights of this layer represent the (w_{ij}) terms in the quadratic function. The output of this layer is (\sum_{j \leq i} w_{ij} x_{i} x_{j}).
Summation Layer: This layer adds the outputs of the first fully connected layer and the second fully connected layer to produce the final output of the network, which is the value of the quadratic function.
Note that this network does not include any activation functions, because the quadratic function is a polynomial function, not a nonlinear function. If you want to model a more complex relationship between the input and the output, you can add activation functions to the network.
Exercise 4:
If the design matrix (\mathbf{X}^\top \mathbf{X}) does not have full rank, it means that there are linearly dependent columns in the matrix (\mathbf{X}). This can lead to several problems:
The matrix (\mathbf{X}^\top \mathbf{X}) is not invertible, which means that the normal equations used to solve the linear regression problem do not have a unique solution. This makes it impossible to find a unique set of regression coefficients that minimize the sum of squared residuals.
The presence of linearly dependent columns in (\mathbf{X}) can lead to overfitting, as the model can “learn” to use these redundant features to perfectly fit the training data, but it will not generalize well to new data.
One common way to fix this issue is to add a small amount of noise to the entries of (\mathbf{X}). This can help to make the columns of (\mathbf{X}) linearly independent, which ensures that (\mathbf{X}^\top \mathbf{X}) has full rank and is invertible. Another common approach is to use regularization techniques, such as ridge regression or lasso regression, which add a penalty term to the loss function that discourages the model from assigning too much importance to any one feature.
If you add a small amount of coordinate-wise independent Gaussian noise to all entries of (\mathbf{X}), the expected value of the design matrix (\mathbf{X}^\top \mathbf{X}) remains the same. This is because the expected value of a Gaussian random variable is its mean, and adding a constant to a random variable shifts its mean by that constant. So if the noise has mean zero, the expected value of (\mathbf{X}^\top \mathbf{X}) does not change.
Stochastic gradient descent (SGD) can still be used when (\mathbf{X}^\top \mathbf{X}) does not have full rank, but it may not converge to a unique solution. This is because SGD does not rely on the invertibility of (\mathbf{X}^\top \mathbf{X}), but instead iteratively updates the regression coefficients based on a randomly selected subset of the data. However, the presence of linearly dependent columns in (\mathbf{X}) can cause the loss surface to have multiple minima, which means that SGD may converge to different solutions depending on the initial values of the regression coefficients.
Answers to Exercises generated by ChatGPT with GPT 4.0 and the Wolfram Plugin:
Exercise 5:
The negative log-likelihood of the data under the model is given by:
The likelihood function for the data is (P(\mathbf y \mid \mathbf X) = \prod_{i=1}^{n} \frac{1}{2} \exp(-|y_i - (\mathbf x_i^\top \mathbf w + b)|)), where (y_i) is the (i)-th target value, (\mathbf x_i) is the (i)-th input vector, (\mathbf w) is the weight vector, and (b) is the bias term.
Taking the negative logarithm of this gives the negative log-likelihood:
(-\log P(\mathbf y \mid \mathbf X) = \sum_{i=1}^{n} \left( \log 2 + |y_i - (\mathbf x_i^\top \mathbf w + b)| \right)).
Unfortunately, there is no closed-form solution for this problem. The absolute value in the log-likelihood function makes it non-differentiable at zero, which means that we cannot set its derivative equal to zero and solve for (\mathbf w) and (b).
A minibatch stochastic gradient descent algorithm to solve this problem would involve the following steps:
Initialize (\mathbf w) and (b) with random values.
For each minibatch of data:
Compute the gradient of the negative log-likelihood with respect to (\mathbf w) and (b). The gradient will be different depending on whether (y_i - (\mathbf x_i^\top \mathbf w + b)) is positive or negative.
Update (\mathbf w) and (b) by taking a step in the direction of the negative gradient.
Repeat until the algorithm converges.
One issue that could arise with this algorithm is that the updates could become very large if (y_i - (\mathbf x_i^\top \mathbf w + b)) is close to zero, because the gradient of the absolute value function is not defined at zero. This could cause the algorithm to diverge.
One possible solution to this problem is to use a variant of gradient descent that includes a regularization term, such as gradient descent with momentum or RMSProp. These algorithms modify the update rule to prevent the updates from becoming too large. Another solution is to add a small constant to the absolute value inside the logarithm to ensure that it is always differentiable.
Exercise 6:
The composition of two linear layers in a neural network essentially results in another linear layer. This is due to the property of linearity: the composition of two linear functions is another linear function.
Mathematically, if we have two linear layers (L_1) and (L_2) such that (L_1(x) = Ax + b) and (L_2(x) = Cx + d), then the composition (L_2(L_1(x)) = L_2(Ax + b) = C(Ax + b) + d = (CA)x + (Cb + d)), which is another linear function.
This means that a neural network with two linear layers has the same expressive power as a neural network with a single linear layer. It cannot model complex, non-linear relationships between the input and the output.
To overcome this limitation, we typically introduce non-linearities between the linear layers in the form of activation functions, such as the ReLU (Rectified Linear Unit), sigmoid, or tanh functions. These non-linear activation functions allow the neural network to model complex, non-linear relationships and greatly increase its expressive power.
Answers to Exercises generated by ChatGPT with GPT 4.0 and the Wolfram Plugin:
Exercise 7:
Regression for realistic price estimation of houses or stock prices can be challenging due to the complex nature of these markets. Prices can be influenced by a wide range of factors, many of which may not be easily quantifiable or available for use in a regression model.
The additive Gaussian noise assumption may not be appropriate for several reasons. First, prices cannot be negative, but a Gaussian distribution is defined over the entire real line, meaning it allows for negative values. Second, the Gaussian distribution is symmetric, but price changes in real markets are often not symmetric. For example, prices may be more likely to increase slowly but decrease rapidly, leading to a skewed distribution of price changes. Finally, the Gaussian distribution assumes that large changes are extremely unlikely, but in real markets, large price fluctuations can and do occur.
Regression to the logarithm of the price can be a better approach because it can help to address some of the issues with the Gaussian noise assumption. Taking the logarithm of the prices can help to stabilize the variance of the price changes and make the distribution of price changes more symmetric. It also ensures that the predicted prices are always positive, since the exponential of any real number is positive.
When dealing with penny stocks, or stocks with very low prices, there are several additional factors to consider. One issue is that the prices of these stocks may not be able to change smoothly due to the minimum tick size, or the smallest increment by which the price can change. This can lead to a discontinuous distribution of price changes, which is not well modeled by a Gaussian distribution. Another issue is that penny stocks are often less liquid than higher-priced stocks, meaning there may not be enough buyers or sellers to trade at all possible prices. This can lead to large price jumps, which are also not well modeled by a Gaussian distribution.
The Black-Scholes model for option pricing is a celebrated model in financial economics that makes specific assumptions about the distribution of stock prices. It assumes that the logarithm of the stock price follows a geometric Brownian motion, which implies that the stock price itself follows a log-normal distribution. This model has been very influential, but it has also been criticized for its assumptions, which may not hold in real markets. For example, it assumes that the volatility of the stock price is constant, which is often not the case in reality.
Exercise 8:
The Gaussian additive noise model may not be appropriate for estimating the number of apples sold in a grocery store for several reasons:
The Gaussian model allows for negative values, but the number of apples sold cannot be negative.
The Gaussian model is a continuous distribution, but the number of apples sold is a discrete quantity.
The Gaussian model assumes that large deviations from the mean are extremely unlikely, but in reality, there could be large fluctuations in the number of apples sold due to various factors (e.g., seasonal demand, promotions).
The Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events (in this case, the number of apples sold) occurring in a fixed interval of time or space. The parameter (\lambda) is the rate at which events occur. The expected value of a Poisson-distributed random variable is indeed (\lambda). This can be shown as follows:
The expected value (E[k]) of a random variable (k) distributed according to a Poisson distribution is given by:
$$E[k] = \sum_{k=0}^{\infty} k \cdot p(k \mid \lambda) = \sum_{k=0}^{\infty} k \cdot \frac{\lambda^k e^{-\lambda}}{k!}$$
By the properties of the Poisson distribution, this sum equals (\lambda).
The loss function associated with the Poisson distribution is typically the negative log-likelihood. Given observed counts (y_1, y_2, \ldots, y_n) and predicted rates (\lambda_1, \lambda_2, \ldots, \lambda_n), the negative log-likelihood is:
$$L(\lambda, y) = \sum_{i=1}^{n} (\lambda_i - y_i \log \lambda_i)$$
If we want to estimate (\log \lambda) instead of (\lambda), we can modify the loss function accordingly. One possible choice is to use the squared difference between the logarithm of the predicted rate and the logarithm of the observed count:
$$L(\log \lambda, y) = \sum_{i=1}^{n} (\log \lambda_i - \log y_i)^2$$
This loss function penalizes relative errors in the prediction of the rate, rather than absolute errors. It can be more appropriate when the counts vary over a wide range, as it gives equal weight to proportional errors in the prediction of small and large counts.
Ex1.
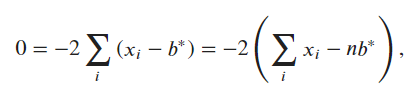
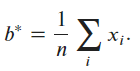
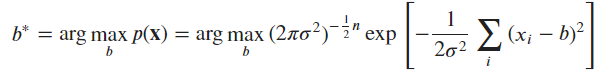
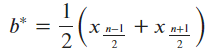
Ex5.
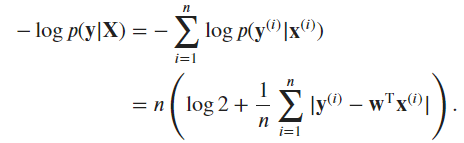
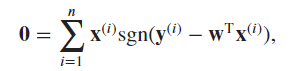
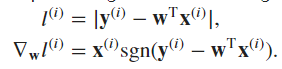
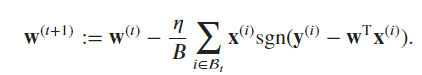
Ex6.
Ex8.
In qeustion 5, i think \epsilon is distributed as Laplacian, and not exponential