-
pass
-
pass
-
yes,pass
-
first dimension:2
-
first dimension
-
not match!
A = torch.arange(20, dtype = torch.float32).reshape(5, 4)
A / A.sum(axis=1)
RuntimeError: The size of tensor a (4) must match the size of tensor b (5) at non-singleton dimension 1
It will be fine.
B = torch.arange(25, dtype = torch.float32).reshape(5, 5)
B / B.sum(axis=1)
tensor([[0.0000, 0.0286, 0.0333, 0.0353, 0.0364],
[0.5000, 0.1714, 0.1167, 0.0941, 0.0818],
[1.0000, 0.3143, 0.2000, 0.1529, 0.1273],
[1.5000, 0.4571, 0.2833, 0.2118, 0.1727],
[2.0000, 0.6000, 0.3667, 0.2706, 0.2182]])
- Walk:Manhattan’s distance.the â„“1 norm
# distances of avenues and streets
dist_ave = 30.0
dist_str = 40.0
dis_2pt = torch.tensor([dist_ave, dist_str])
torch.abs(dis_2pt).sum()
Can. Fly straightly and diagonally.the â„“2 norm
torch.norm(dis_2pt)
tensor(50.)
- The shape is just the shape of the original tensor that deleted the axis required.
X.sum(axis = 0).size() torch.Size([3, 4])
X.sum(axis = 1).size() torch.Size([2, 4])
X.sum(axis = 2).size() torch.Size([2, 3])
- $|\mathbf{x}|{2}=\sqrt{\sum{i=1}^{n} x_{i}^{2}}$
Y= torch.arange(24,dtype = torch.float32).reshape(2, 3, 4)
torch.norm(Y)
tensor(65.7571)
i = 0
for j in range(24):
i += j**2
j += 1
import math
print(math.sqrt(i))
65.75712889109438
The numbers are same.
For more:
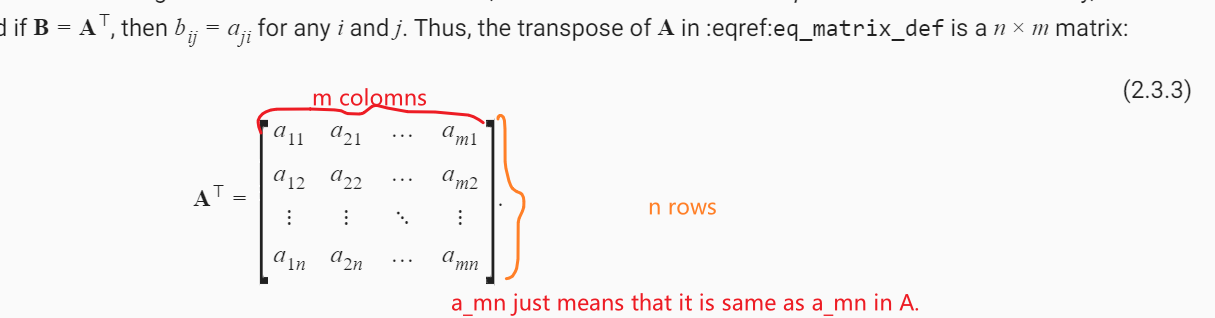
The matrix should be indexed via nm instead of mn, since the original matrix is mn and this is the transposed version.
Hey @goldpiggy, the link given includes a # query parameter which directly links to “the matrix”. Does that work for you?
Hi @manuel-arno-korfmann, you mean the matirx index like $a_12$ and $a_21$? The indexes’ location is flipped, while they have to keep the original values. Ultimately, $a_mn$ and $a_nm$ have different values at the original matrix

Its said that “By default, invoking the function for calculating the sum reduces a tensor along all its axes to a scalar. We can also specify the axes along which the tensor is reduced via summation. Take matrices as an example. To reduce the row dimension (axis 0) by summing up elements of all the rows, we specify axis=0 when invoking the function.” Are you sure? Look at my code:
A = torch.arange(25).reshape(5,5)
A, A.sum(axis = 1)
(tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]]),
tensor([ 10, 35, 60, 85, 110]))
When axis = 1, all elements in row 0 are added.
Otherwse (axis = 0), all elements colummns are added.
I didn’t understand that. Could you explain it with more details, please?
Maybe this reply is too late but here you go.
Your understanding of row vs column is wrong.
In,
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])
[ 0, 1, 2, 3, 4] is a column and [ 0, 5, 10, 15, 20] is a row.
It feels like the following solution is more appropriate for question 6 as there is no change in the actual value of A like in your answer.
A = torch.arange(20, dtype = torch.float32).reshape(5, 4)
A / A.sum(axis=1, keep_dim=True)
After using keep_dim=True, broadcasting happens and dimensionality error would disapper.
Your understanding of row vs column is wrong.
Are you sure you don’t have it backwards?
A = torch.arange(25, dtype = torch.float32).reshape(5, 5)
"""
>>> A
tensor([[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[10., 11., 12., 13., 14.],
[15., 16., 17., 18., 19.],
[20., 21., 22., 23., 24.]])
>>> A[0]
tensor([0., 1., 2., 3., 4.])
>>> A[:,0] # Fix column 0, run across rows
tensor([ 0., 5., 10., 15., 20.])
>>> A[0, :] # Fix row 0, run across columns
tensor([0., 1., 2., 3., 4.])
"""
About the exercises, the questions needed to be coded or mathematically solved?
Can anybody solve the No. 9 in the exercise.
Hi, I gave it a shot and here is what I found:
The torch.linalg.norm function computes the L2-norm no matter the rank of a Tensor. In other words, it squares all the elements of a Tensor, sums them up, and reports the square root of the sum.
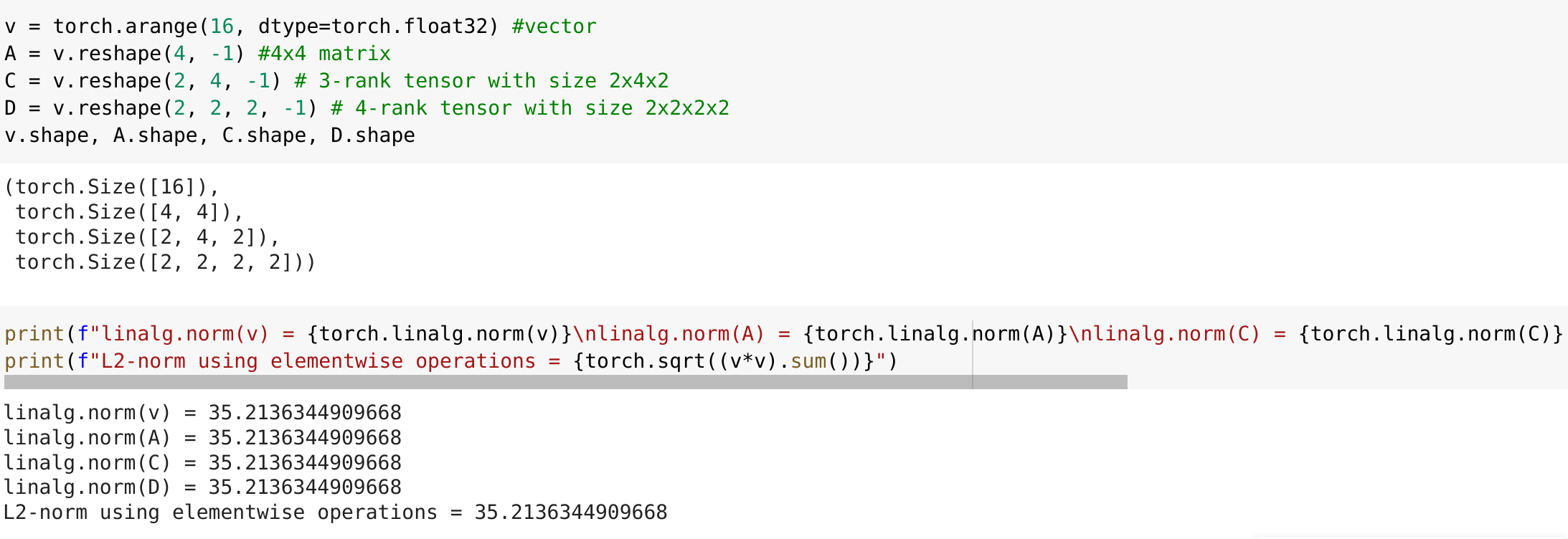
I hope this helps. Thanks.
About Exersize.11
After some testing, I think using C=B^T is fater
Here is the code for testing:
import torch
import time
a = torch.randn([2**10,2**16])
b = torch.randn([2**16,2**5])
c = torch.randn([2**5,2**16])
start = time.time()
a@b
end = time.time()
delay0 = end-start
start = time.time()
a@c.T
end = time.time()
delay1 = end-start
print(delay0, ',', delay1, '|', delay0/delay1)
d = torch.randn([2**10,2**16])
e = torch.randn([2**16,2**5])
f = e.T
start = time.time()
d@e
end = time.time()
delay0 = end-start
start = time.time()
d@f.T
end = time.time()
delay1 = end-start
print(delay0, ',', delay1, '|', delay0/delay1)
The outputs in jupyter are:
the first time:
0.09555768966674805 , 0.07239270210266113 | 1.3199906467261895
0.07950305938720703 , 0.08091998100280762 | 0.9824898424586701
the second time
0.08409309387207031 , 0.06908702850341797 | 1.2172052510249438
0.07972121238708496 , 0.07754659652709961 | 1.028042698936831
I test it for several times, the results are likely, but I’m not so sure ![]() , because the difference between them is not so obvious, so is there anybody who have any other way to do this exercise?
, because the difference between them is not so obvious, so is there anybody who have any other way to do this exercise?
Note: my memory of computer is 8GB, memory of GPU is 4GB, I tried the matrices below to reach the memory limit and then my jupyter kernel went died ![]() and forced to restarted…
and forced to restarted…
a = torch.randn([2**10,2**21])
b = torch.randn([2**21,2**5])
c = torch.randn([2**5,2**21])
My attempts :
Exercises
1. Prove that the transpose of the transpose of a matrix is the matrix itself: $ (\mathbf{A}^\top)^\top = \mathbf{A} $
The $ (i, j)^{th} $ element of A corresponds to $ (j, i)^{th} $ element of $ \mathbf{A}^{\top} $, so the $ (i, j)th $ element of $ (\mathbf{A}^{\top})^{\top} $ will correspond to the $ (j, i)^{th} $ element of $ \mathbf{A}^{\top} $, which corresponds to the $ (i, j)^{th} $ element of $ \mathbf{A} $; therefore the two will be equal
2. Given two matrices $ mathbf{A} $ and $ mathbf{B} $, show that sum and transposition commute: $ \mathbf{A}^\top + \mathbf{B}^\top = (\mathbf{A} + \mathbf{B})^\top $.
$ (j, i)^{th} $ element of $ \mathbf{A}^\top $ + $ (j, i)^{th} $ element of $ \mathbf{B}^\top $ are equal to the $ ( \mathbf{i}, \mathbf{j})^{th} $ element of $ \mathbf{A} + \mathbf{B} $, therefore the two will be equal if we transpose $ \mathbf{A} + \mathbf{B} $
3. Given any square matrix $ \mathbf{A} $ , is $ \mathbf{A} $ + $ \mathbf{A}^{\top} $ always symmetric? Can you prove the result by using only the result of the previous two exercises?
Yes, since we’re literally just asking whether $ (x) + (y) == x + y $. How? Both , the $ (i, j)^{th} $ and $ (j, i)^{th} $ values of any matrix $ \mathbf{A} $ are being added to each other, making them the same, leading to symmetricity
4. We defined the tensor $ \mathsf{X} $ of shape (2, 3, 4) in this section. What is the output of len(X)? Write your answer without implementing any code, then check your answer using code.
2, since we’re taking the length of a “list” that contains elements of shape (3, 4).
X = torch.arange(2 * 3 * 4, dtype = torch.float32).reshape(2, 3, 4)
len(X)
2
5. For a tensor $ \mathsf{X} $ of arbitrary shape, does len(X) always correspond to the length of a certain axis of $ \mathsf{X} $? What is that axis?
Yes, axis 0
6. Run A / A.sum(axis=1) and see what happens. Can you analyze the reason?
A / A.sum(axis=1)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [68], in <cell line: 1>()
----> 1 A / A.sum(axis=1)
RuntimeError: The size of tensor a (3) must match the size of tensor b (2) at non-singleton dimension 1
The reason is that the shapes completely mismatch : the very order of the tensors themselves is incompatible, so broadcasting won’t save us
7. When traveling between two points in downtown Manhattan, what is the distance that you need to cover in terms of the coordinates, i.e., in terms of avenues and streets? Can you travel diagonally?
I don’t know what avenues are ![]() . But I believe we travel along streets/roads that lead us to our destination. We can’t travel diagonally since there will be things like houses and other buildings/parks/private properties getting in the way
. But I believe we travel along streets/roads that lead us to our destination. We can’t travel diagonally since there will be things like houses and other buildings/parks/private properties getting in the way ![]()
8. Consider a tensor with shape (2, 3, 4). What are the shapes of the summation outputs along axis 0, 1, and 2?
X.sum(axis = 0).shape, X.sum(axis = 1).shape, X.sum(axis = 2).shape
(torch.Size([3, 4]), torch.Size([2, 4]), torch.Size([2, 3]))
The axis along which we reduced got destroyed
9. Feed a tensor with 3 or more axes to the linalg.norm function and observe its output. What does this function compute for tensors of arbitrary shape?
X, torch.linalg.norm(X)
(tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]],
[[12., 13., 14., 15.],
[16., 17., 18., 19.],
[20., 21., 22., 23.]]]),
tensor(65.7571))
Sum = 0
for item in X.flatten():
Sum += item ** 2
torch.sqrt(Sum)
tensor(65.7571)
Looks like it simply sums the square of all the elements inside the tensor then takes square root
10. Define three large matrices, say $ \mathbf{A} \in \mathbb{R}^{2^{10} \times 2^{16}} $, $ \mathbf{B} \in \mathbb{R}^{2^{16} \times 2^{5}} $ and $ \mathbf{C} \in \mathbb{R}^{2^{5} \times 2^{16}} $, for instance initialized with Gaussian random variables. You want to compute the product . Is there any difference in memory footprint and speed, depending on whether you compute $ (\mathbf{A} \mathbf{B}) \mathbf{C} $ or $ \mathbf{A} (\mathbf{B} \mathbf{C}) $. Why?
$ (\mathbf{A} \mathbf{B}) \mathbf{C} $ will result in time being $ \mathcal{O}(2^{10} \times 2^{16} \times 2^5 + 2^{10} \times 2^{5} \times 2^{16} ) $
$ \mathbf{A} (\mathbf{B} \mathbf{C}) $ will result in time being $ \mathcal{O}(2^{10} \times 2^{16} \times 2^{16} + 2^{16} \times 2^{5} \times 2^{16} ) $
The latter is much much more expensive because of the algorithms being designed to have complexity of $ \mathcal{O}(n \times m \times k) $ where the matrices $ A $ and $ B $ are of size $ \mathbb{R}^{n \times m} $ and $ \mathbb{R}^{m \times k} $ respectively
11. Define three large matrices, say $ \mathbf{A} \in \mathbb{R}^{2^{10} \times 2^{16}} $ , $ \mathbf{B} \in \mathbb{R}^{2^{16} \times 2^{5}} $ and $ \mathbf{C} \in \mathbb{R}^{2^{5} \times 2^{16}} $. Is there any difference in speed depending on whether you compute $ \mathbf{A} \mathbf{B} $ or $ \mathbf{A} \mathbf{C}^\top $? Why? What changes if you initialize $ \mathbf{C} = \mathbf{B}^\top $ without cloning memory? Why?
A = torch.randn( (2 ** 10, 2 ** 16) )
B = torch.randn( (2 ** 16, 2 ** 5) )
C = torch.randn( (2 ** 5, 2 ** 16) )
%time
temp = A @ B
CPU times: user 2 µs, sys: 0 ns, total: 2 µs
Wall time: 5.96 µs
%time
temp = A @ C.T
CPU times: user 2 µs, sys: 0 ns, total: 2 µs
Wall time: 5.48 µs
%time
temp = A @ B.T
CPU times: user 2 µs, sys: 0 ns, total: 2 µs
Wall time: 5.25 µs
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [101], in <cell line: 3>()
1 get_ipython().run_line_magic('time', '')
----> 3 temp = A @ B.T
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1024x65536 and 32x65536)
$ \mathbf{A} \times \mathbf{C}^{\top} $ yields better performance due to the layout of data in memory : since the row major format in which data is usually stored in torch usually prefers memory accesses of the same row, when you take transpose of $ \mathbf{C}^{\top} $, it’s not really taking a physical transpose, but a logical one, meaning when we index the trasposes matrix at $ (i, j) $, it just gets internally converted to $ (j, i) $ of the matrix before transposition. Since the elements of the second matrix are accessed column-wise, it is inefficient for this task, but if we have it logically transposed, then the accesses become efficent again, since the data is logically being accessed across rows, ie, columns-wise, but is physically geting accessed across columns, ie, row-wise, since we didn’t actually perform the element swaps, only decided to change indexing under the hood. Hence, the transpose technique works faster
I just don’t understand what is being asked about transposing $ \mathbf{B}^{\top} $. Now the resulting matrix can’t be multiplied with $ \mathbf{A} $ since their shapes are incompatible
12. Define three matrices, say $ \mathbf{A}, \mathbf{B}, \mathbf{C} \in \mathbb{R}^{100 \times 200} $. Constitute a tensor with 3 axes by stacking $ [\mathbf{A}, \mathbf{B}, \mathbf{C}] $ . What is the dimensionality? Slice out the second coordinate of the third axis to recover $\mathbf{B} $ . Check that your answer is correct.
A = torch.randn( (100, 200) )
B = torch.randn( (100, 200) )
C = torch.randn( (100, 200) )
stacked = torch.stack([ A, B, C ])
print(f"{stacked.shape = }")
stacked [ 1 ] == B
stacked.shape = torch.Size([3, 100, 200])
tensor([[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True],
...,
[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True]])
I have no idea why the latex rendering isn’t working ![]()
@goldpiggy @mli sorry for pinging like this but can anything be done about this? It’s very disheartening to see all my efforts to write equations in an aesthetically pleasing way turn out like this ![]()
Thanks in advance
Edit : I found a link to a post where there seems to be an official plugin to enable latex support. Maybe that can help? Discourse Math - plugin - Discourse Meta
-
The (i,j)-entry of AT is the (j,i)-entry of A, so the (i,j)-entry of (AT)T is the (j,i)-entry of AT, which is the (i,j)-entry of A. Thus all entries of (AT)T coincide with the corresponding entries of A, so these two matrices are [equal.]
-
The (i,j)-entry of AT+BT is the sum of (i,j)-entries of AT and BT, which are (j,i)-entries of A and B, respectively. Thus the (i,j)-entry of AT+BT is the (j,i)-entry of the sum of A and B, which is equal to the (i,j)-entry of the transpose (A+B)T.
-
Given any square matrix A, is A + A⊤ always symmetric? Why?, A has mxn and if A is symetric m=n so A⊤ has nxm where m=n for symetric, so A+A⊤ is simetric
-
len(x) = 2
-
first axis lengh
-
No broadcast chance, last dimension is diferente for both matrix
x.shape, x.sum(axis=1).shape -
the norm L2 of vector, pass, pass
-
(torch.Size([3, 4]), torch.Size([2, 4]), torch.Size([2, 3]))
-
Frobenius norm
In section 2.3.9. Matrix-Vector Products, why is the row vector $\mathbf{a}^\top_{i}$ represented as a transpose? Or is the transpose symbol there to represent something else?
I get the following error when trying to transpose the matrix using A.T
UserWarning: The use of x.T on tensors of dimension other than 2 to reverse their shape is deprecated and it will throw an error in a future release. Consider x.mT to transpose batches of matricesor x.permute(*torch.arange(x.ndim - 1, -1, -1)) to reverse the dimensions of a tensor. (Triggered internally at …/aten/src/ATen/native/TensorShape.cpp:2985.)
When I use x.permute on a 2 x 2 array all is does is make a it a 1 x 4 array.
I can’t seem to get the transpose right.
Thanks!