请问有人遇到这种情况吗
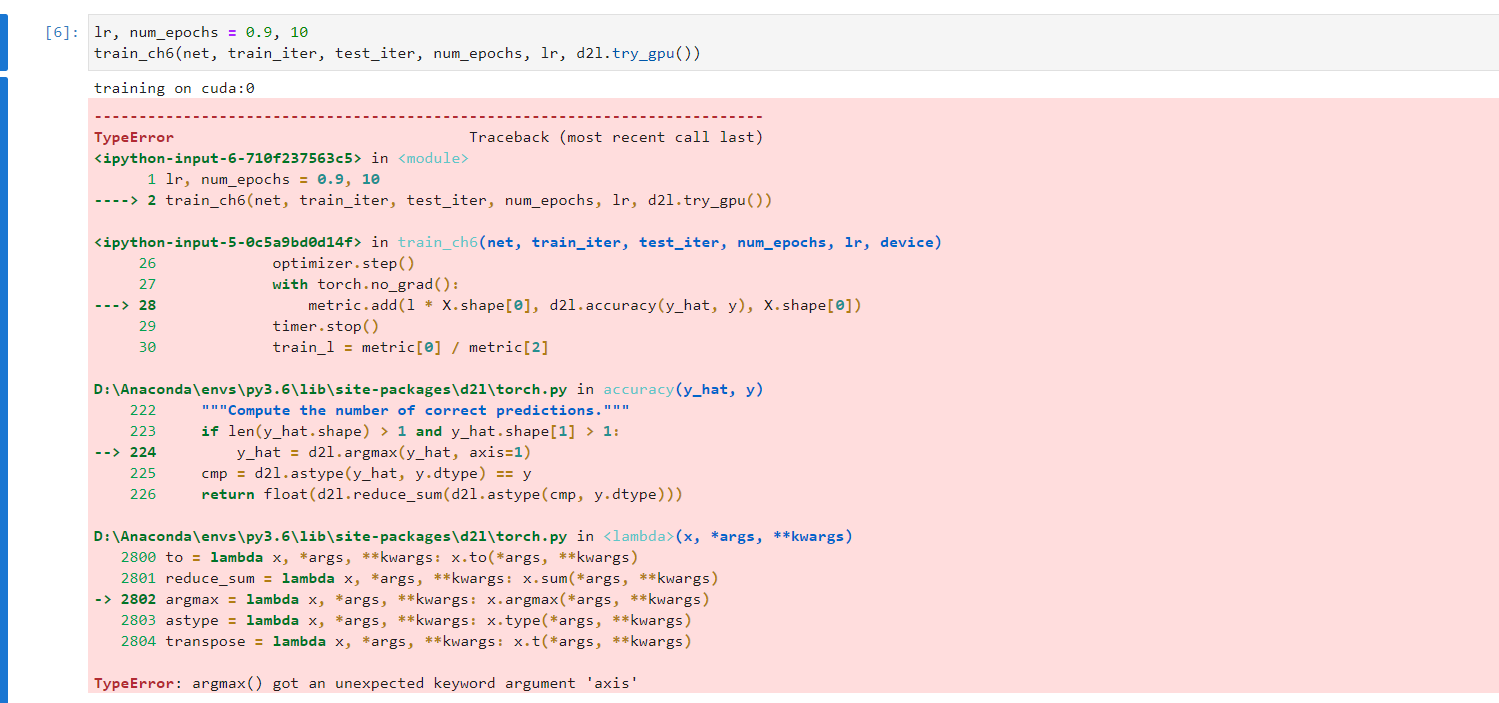
卷积层里的偏置项起到什么作用呢?防止过拟合么?
1 Like
我也遇到了这个问题,一运行代码c盘直接满了,请问你的问题解决了吗?
1 Like
我猜是因为没有偏置的话拟合超平面必须要穿过原点。而实际上拟合超平面不一定是穿过原点的。
2 Likes
我尝试着用了最大池化,并且将激活函数全部修改为ReLU,发现结果并不收敛,但我在我更改学习率为0.1之后它就能很快收敛了。可以预见的是就算是相似的网络结构某些超参数的调整仍是非常有必要的
4 Likes
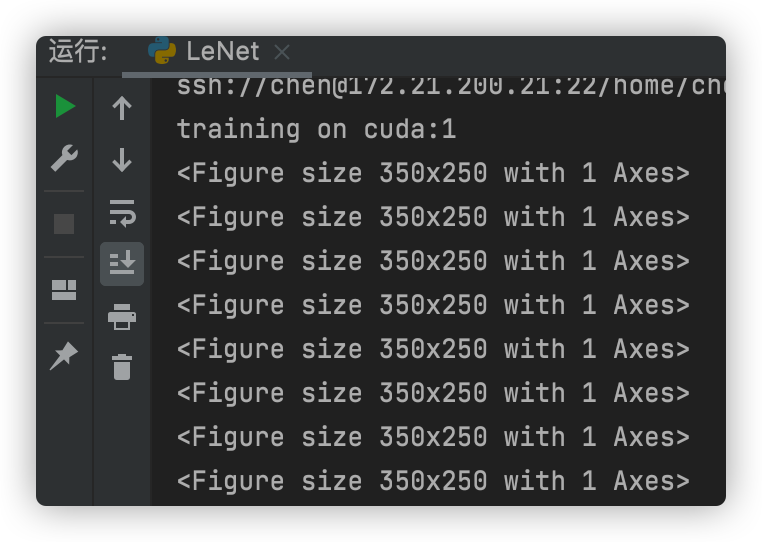
为什么我有警告
UserWarning: Failed to load image Python extension: Could not find module ‘C:\Users\DELL.conda\envs\d2l-zh-gpu\Lib\site-packages\torchvision\image.pyd’ (or one of its dependencies). Try using the full path with constructor syntax.
咋办啊
pycharm中运行的话想要显示图形,需要加上plt.show()
1 Like
我尝试修改过d2l.train_ch6里面的代码,在里面加上了ply.show(),还是无法得到老师在jupyter里面的效果。
我也遇到同样的问题,请问应该怎么处理呢?
在Animator类的add()方法的倒数第二行上面加上
plt.draw(),
plt.pause(0.001)
4 Likes
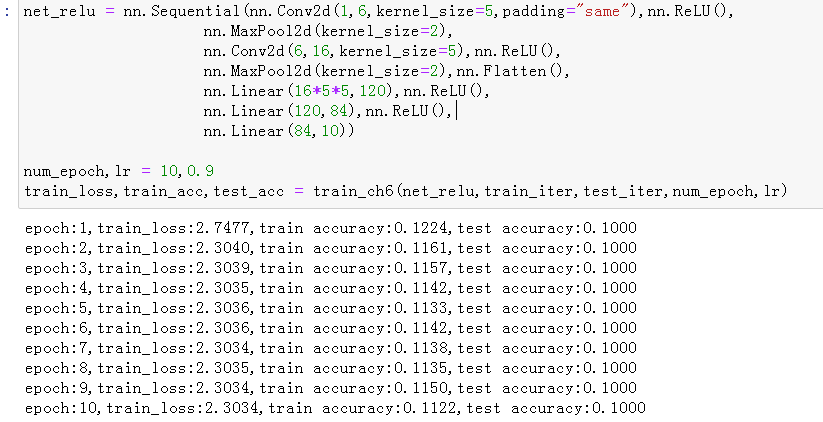
调节了卷积窗口的大小,每层输出的shape会发生变化,需要重新计算新的值
1 Like
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
这里在计算训练损失时,为什么不可以直接用l, 而是要l * X.shape[0]/X.shape[0]?
因为训练得到的l已经是平均值了。。。。。
1 Like
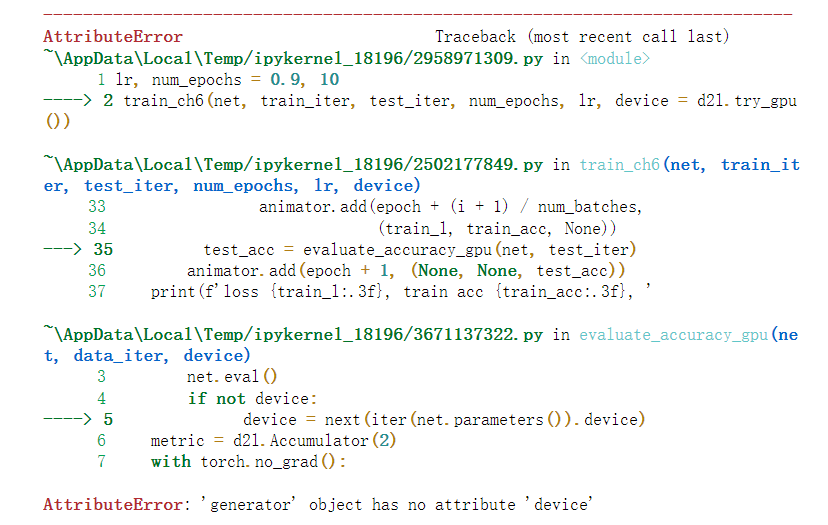
啊 没懂啊 为什么不能直接返回l 乘批量大小再除,不还是原来的损失吗?
请问一下大家,在GPU上跑的时候,但是CPU利用率还是很高,而GPU利用率只是间歇性地跑到60-70%。这是什么原因呢??
把lr调小就可以很快收敛,0.9这个学习率对于ReLU来说太大了。我觉得可能是因为ReLU在0的右邻域内的梯度比sigmoid大得多,所以适用于sigmoid的lr用在ReLU身上容易步子迈太大,走过头,反而不好收敛。
3 Likes
我也遇到同样的问题,请问你现在解决了吗?