https://zh-v2.d2l.ai/chapter_computer-vision/kaggle-cifar10.html
请问运行时报错 :TypeError: array() takes 1 positional argument but 2 were given
该怎么解决?
你好,在模型定义这里 loss = nn.CrossEntropyLoss(reduction=“none”) ,参数reduction="none"的作用是什么呢?
是不是, l.sum() 的区别?如果有这个参数这不需要对loss进行累加?
你是不是这样调用array(item1, item2),改成array([item1,item2]),把两个元素合一个list传入
我看了torch源码,reduction总共有三个选项,“mean”,“sum”,“none”。
当我们输入一个batch的样本后,每个样本都有一个损失值,就得到一个batch_size大小的损失值向量。
这三个选项就是对这个损失值向量做的操作。
"mean"就是对这个向量求平均,得到整个batch的平均损失
“sum”就是求和损失向量
“none”:什么也不做,直接返回整个损失向量。
在代码中,执行backward()之前是l.sum().backward() ,其实相当于reduction=“sum”,然后执行l.backward()。
(btw,reduction 默认值为mean,选取不同的reduction需要注意learning_rate的调整,使用sum的话loss变成mean的batch_size倍,梯度也变成batch_size倍,注意lr过大导致模型不收敛的问题)
6 Likes
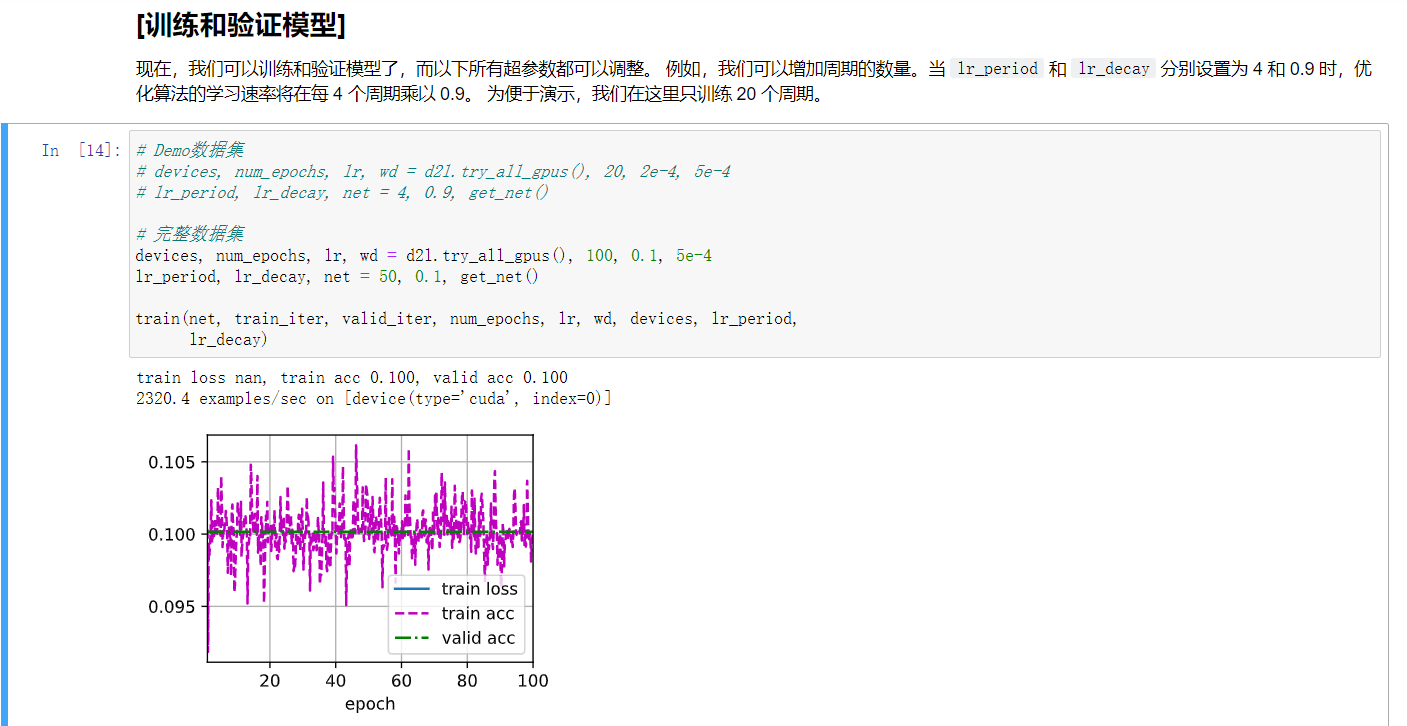
请问使用完整的数据集,按照练习里面给定的参数训练,出现训练精度和验证精度一直保持在0.1左右是什么原因? batch_size = 128 , num_epochs = 100 , lr = 0.1 , lr_period = 50 , lr_decay = 0.1
问下最后提交生成CSV文件的时候,下面两句话有什么意义?
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
貌似排序后前几个数变成1,10,100,1000,10000,100000,100001,这样去对应预测的标签?
啥原因,最后咋解决的呢?, 我也遇到了这样的问题哈。
应该是学习率过大了,设置成lr=0.1e-4就可以了。。。 
! pip install matplotlib==3.0.0可以解决问题
在 13.13.5. 定义训练函数,关于train训练函数的一个疑问:
for epoch in range(num_epochs):
net.train() #这个调用为什么需要,多余吗?在下面train_batch_ch13里面已经有train的调用?
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
是的是的,降低学习率就行。。。。。。。。。。。。。。。。。。。。
提交一个issue:
建议在测试前添加net.eval(),在代码中,测试集的预测部分缺少了将模型设置为评估模式的步骤(即net.eval()),因为resnet中使用了BatchNorm2d,在测试时仍会更新统计信息(moving mean和moving variance),导致测试结果受到一定的波动,并影响准确率。
net, preds = get_net(), []
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period, lr_decay)
# Add net.eval() before testing
net.eval()
for X, _ in test_iter:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
类似的问题也出现在《 实战Kaggle比赛:狗的品种识别(ImageNet Dogs)》的代码中,建议一并修改
1 Like
你好,请问知道是啥原因吗 ![]() ,测试数据集不是顺序读取的吗,排序后不就对应不上了我理解
,测试数据集不是顺序读取的吗,排序后不就对应不上了我理解
测试了下,ImageFolder读取数据是按文件名字典序来的,所以id也要按照字符串顺序来读才能对应上
请问老师,重新整理数据集的操作是必须的吗,就是构造各个类别下的数据子集
train函数最后是不是应该返回net,不然根本得不到训练后的模型。。去预测测试集也是错的?