https://d2l.ai/chapter_computer-vision/image-augmentation.html
As mentioned in the beginning of this section, one reason image augmentation could improve the performance of a DL model is that it increases the size of the training dataset by generated the augmented samples. However, in our example, load_cifar10(), it seems we applied the transformation without upsampling. So just curious, in practice, do we apply the transformation repeatedly (by n times) to upsample the data (get a training dataset of n times larger)? Could you please give an example of how to do that using gluon?
Thank you in advance!
Hi @lkforward, great question! It really depends on the size of original training set. For example, some domain images (such as medical domain) are lack of samples, then we have to upsample n times to get a decent size of training examples. However, if the original training set already has sufficient number of samples, what image augmentation does is to add variety or diversity of features (e.g., it may rotate the cat from different angles rather than only one angle).
1 Like
I did some experiments trying to address Exercise 1, “… Can your comparative experiment support the argument that image augmentation can mitigate overfitting? Why?”
I used a subset of CIFAR10, with 500 images (50 for each class, and 10 classes in all) for training and 100 images for validation. Resnet18 was used to predict the probability of an image belongs to one of the classes.
Settings:
Case 1. Benchmark, the original images without augmentations.
Case 2. Apply the following augmentations:
aug = transforms.Compose(
[transforms.Resize(40),
transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
Case 3. A up-sampling is applied using the same augmentation. The augmentation is applied with replacement for four times for each original image, so the data size becomes 2000/400 for training / validation.
Results for case 1:

Results for case 2:
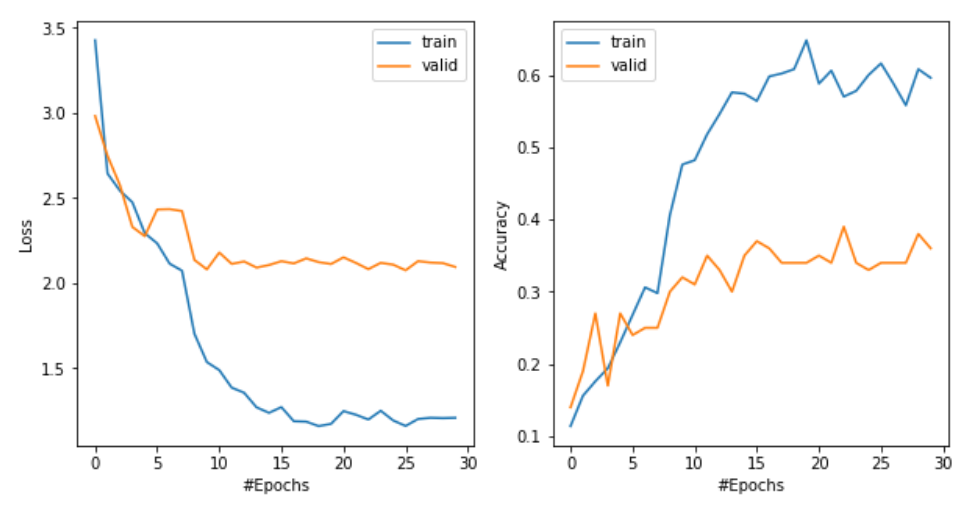
Results for case 3:
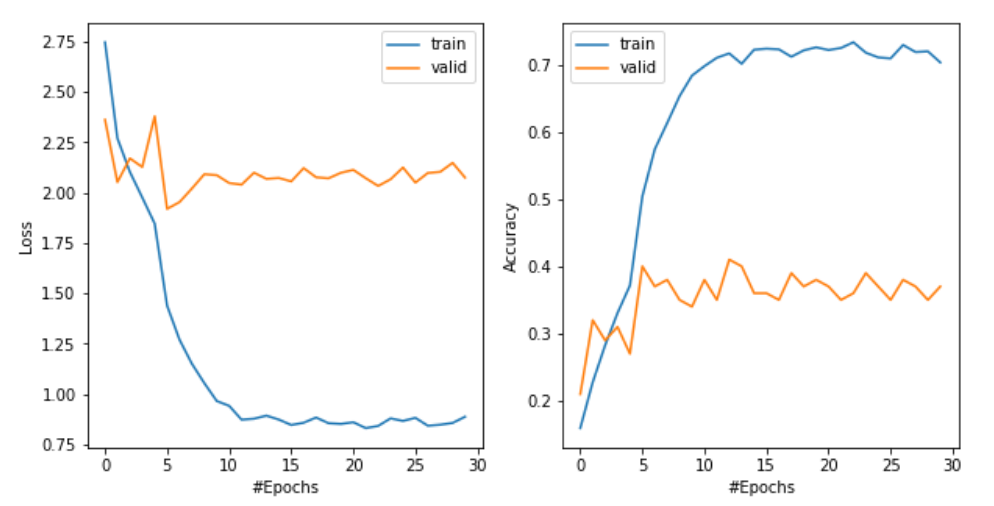
Based on the loss and the accuracy in the plots, the results from case 3 and case 2 are better than the benchmark, which seems to verify our expectation. However, there are two issues I am not quite sure:
- (1) In case 3, the gap (of both loss and accuracy) between the training and the validation curve is larger than other cases. Is it fair to state that “augmentation with upsampling could mitigate overfitting”? As some one can argue that the overfitting is worse in this case.
- (2) The loss in the validation data seem to reach a stable value faster (taking about 8 epochs) than the training data in all the cases here. Can we say the model starts to overfit after about 8 epochs?
Why it’s often only a percentage of the data is augmented, not the whole data? If I have 1K images, why can’t I augment my data to 5K with 5 different transformations?
in the code train_ch13, the fourth metric refers to number of features, but in the code, the value given by labels.size and it is the same as labels.shape[0] (number of examples in each batch) since labels is a vector of dim one, shouldn’t it be number of examples too? Why is it written as number of features. Thank you.
Hi @rezahabibi96, great question! I believe you are asking about https://d2l.ai/_modules/d2l/mxnet.html#Animator. Let me know if it helps?!
For colab users:
- Look this first: http://preview.d2l.ai/d2l-en/master/chapter_appendix-tools-for-deep-learning/colab.html
- Follow my discussion to download all colab code: Using Google Colab
- Then follow my code:
https://github.com/StevenJokess/d2l-en-read/blob/master/Ch13_CV/image_augmentation.ipynb
Trying to utilize gluon’s RandomRotation:
train_augs = gluon.data.vision.transforms.Compose([
gluon.data.vision.transforms.ToTensor(),
gluon.data.vision.transforms.RandomRotation((0, 360))
])
train_augs(img)
but hitting a snag:
TypeError: This transformation only supports float32. Consider calling it after ToTensor
It’s clearly after calling ToTensor.
Ideas?
Hello all experts,
Greetings.
I’m new to deep learning and computer vision. I use tensorflow, for this chapter there’s no tensorflow code. Where can I get tensorflow code.
@astonzhang
@goldpiggy
Thanks
@new2dl
http://preview.d2l.ai/d2l-en/master/chapter_computer-vision/image-augmentation.html
There isn’t tf code now. You need to wait. tangyuan is working for the part.